 NEWSLETTER
NEWSLETTER
Today, we’re pleased to announce the general availability (GA) of amazon Bedrock Custom Model Import. This feature empowers customers to import and use their customized models alongside existing foundation models (FMs) through a single, unified API. Whether leveraging fine-tuned models like Meta Llama, Mistral Mixtral, and IBM Granite, or developing proprietary models based on popular open-source architectures, customers can now bring their custom models into amazon Bedrock without the overhead of managing infrastructure or model lifecycle tasks.
amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading ai companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API, along with a broad set of capabilities to build generative ai applications with security, privacy, and responsible ai. amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
With amazon Bedrock Custom Model Import, customers can access their imported custom models on demand in a serverless manner, freeing them from the complexities of deploying and scaling models themselves. They’re able to accelerate generative ai application development by using native amazon Bedrock tools and features such as Knowledge Bases, Guardrails, Agents, and more—all through a unified and consistent developer experience.
Benefits of amazon Bedrock Custom Model Import include:
- Flexibility to use existing fine-tuned models:Customers can use their prior investments in model customization by importing existing customized models into amazon Bedrock without the need to recreate or retrain them. This flexibility maximizes the value of previous efforts and accelerates application development.
- Integration with amazon Bedrock Features: Imported custom models can be seamlessly integrated with the native tools and features of amazon Bedrock, such as Knowledge Bases, Guardrails, Agents, and Model Evaluation. This unified experience enables developers to use the same tooling and workflows across both base FMs and imported custom models.
- Serverless: Customers can access their imported custom models in an on-demand and serverless manner. This eliminates the need to manage or scale underlying infrastructure, as amazon Bedrock handles all those aspects. Customers can focus on developing generative ai applications without worrying about infrastructure management or scalability issues.
- Support for popular model architectures: amazon Bedrock Custom Model Import supports a variety of popular model architectures, including Meta Llama 3.2, Mistral 7B, Mixtral 8x7B, and more. Customers can import custom weights in formats like Hugging Face Safetensors from amazon SageMaker and amazon S3. This broad compatibility allows customers to work with models that best suit their specific needs and use cases, allowing for greater flexibility and choice in model selection.
- Leverage amazon Bedrock converse API: amazon Custom Model Import allows our customers to use their supported fine-tuned models with amazon Bedrock Converse API which simplifies and unifies the access to the models.
Getting started with Custom Model Import
One of the critical requirements from our customers is the ability to customize models with their proprietary data while retaining complete ownership and control over the tuned model artifact and its deployment. Customization could be in form of domain adaptation or instruction fine-tuning. Customers have a wide degree of options for fine-tuning models efficiently and cost effectively. However, hosting models presents its own unique set of challenges. Customers are looking for some key aspects, namely:
- Using the existing customization investment and fine-grained control over customization.
- Having a unified developer experience when accessing custom models or base models through amazon Bedrock’s API.
- Ease of deployment through a fully managed, serverless, service.
- Using pay-as-you-go inference to minimize the costs of their generative ai workloads.
- Be backed by enterprise grade security and privacy tooling.
amazon Bedrock Custom Model Import feature seeks to address these concerns. To bring your custom model into the amazon Bedrock ecosystem, you need to run an import job. The import job can be invoked using the AWS Management Console or through APIs. In this post, we demonstrate the code for running the import model process through APIs. After the model is imported, you can invoke the model by using the model’s amazon Resource Name (ARN).
As of this writing, supported model architectures today include Meta Llama (v.2, 3, 3.1, and 3.2), Mistral 7B, Mixtral 8x7B, Flan and IBM Granite models like Granite 3B-Code, 8B-Code, 20B-Code and 34B-Code.
A few points to be aware of when importing your model:
- Models must be serialized in Safetensors format.
- If you have a different format, you can potentially use Llama convert scripts or Mistral convert scripts to convert your model to a supported format.
- The import process expects at least the following files:
.safetensors,json,tokenizer_config.json,tokenizer.json, andtokenizer.model. - The precision for the model weights supported is FP32, FP16, and BF16.
- For fine-tuning jobs that create adapters like
LoRA-PEFTadapters, the import process expects the adapters to be merged into the main base model weight as described in Model merging.
Importing a model using the amazon Bedrock console
- Go to the amazon Bedrock console and choose Foundational models and then Imported models from the navigation pane on the left hand side to get to the Models
- Click on Import Model to configure the import process.
- Configure the model.
- Enter the location of your model weights. These can be in amazon S3 or point to a SageMaker Model ARN object.
- Enter a Job name. We recommend this be suffixed with the version of the model. As of now, you need to manage the generative ai operations aspects outside of this feature.
- Configure your AWS Key Management Service (AWS KMS) key for encryption. By default, this will default to a key owned and managed by AWS.
- Service access role. You can create a new role or use an existing role which will have the necessary permissions to run the import process. The permissions must include access to your amazon S3 if you’re specifying model weights through S3.
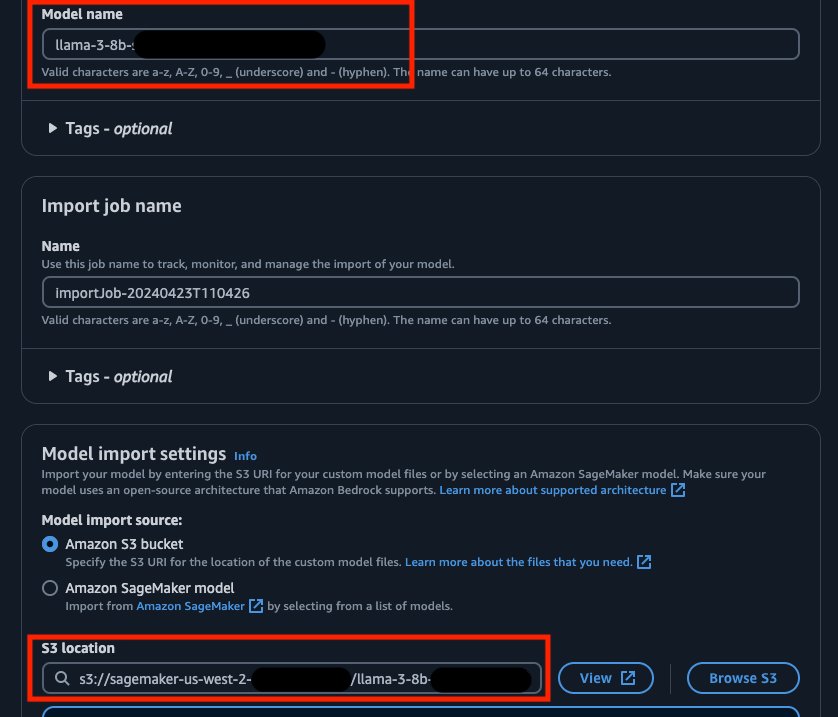
- After the Import Model job is complete, you will see the model and the model ARN. Make a note of the ARN to use later.

- Test the model using the on-demand feature in the Text playground as you would for any base foundations model.

The import process validates that the model configuration complies with the specified architecture for that model by reading the config.json file and validates the model architecture values such as the maximum sequence length and other relevant details. It also checks that the model weights are in the Safetensors format. This validation verifies that the imported model meets the necessary requirements and is compatible with the system.
Fine tuning a Meta Llama Model on SageMaker
Meta Llama 3.2 offers multi-modal vision and lightweight models, representing Meta’s latest advances in large language models (LLMs). These new models provide enhanced capabilities and broader applicability across various use cases. With a focus on responsible innovation and system-level safety, the Llama 3.2 models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features to help you build a new generation of ai experiences.
SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the SageMaker Python SDK. This gives you multiple options to discover and use hundreds of models for your use case.
In this section, we’ll show you how to fine-tune the Llama 3.2 3B Instruct model using SageMaker JumpStart. We’ll also share the supported instance types and context for the Llama 3.2 models available in SageMaker JumpStart. Although not highlighted in this post, you can also find other Llama 3.2 Model variants that can be fine-tuned using SageMaker JumpStart.
Instruction fine-tuning
The text generation model can be instruction fine-tuned on any text data, provided that the data is in the expected format. The instruction fine-tuned model can be further deployed for inference. The training data must be formatted in a JSON Lines (.jsonl) format, where each line is a dictionary representing a single data sample. All training data must be in a single folder, but can be saved in multiple JSON Lines files. The training folder can also contain a template.json file describing the input and output formats.
Synthetic dataset
For this use case, we’ll use a synthetically generated dataset named amazon10Ksynth.jsonl in an instruction-tuning format. This dataset contains approximately 200 entries designed for training and fine-tuning LLMs in the finance domain.
The following is an example of the data format:
Prompt template
Next, we create a prompt template for using the data in an instruction input format for the training job (because we are instruction fine-tuning the model in this example), and for inferencing the deployed endpoint.
After the prompt template is created, upload the prepared dataset that will be used for fine-tuning to amazon S3.
Fine-tuning the Meta Llama 3.2 3B model
Now, we’ll fine-tune the Llama 3.2 3B model on the financial dataset. The fine-tuning scripts are based on the scripts provided by the Llama fine-tuning repository.
Importing a custom model from SageMaker to amazon Bedrock
In this section, we will use a Python SDK to create a model import job, get the imported model ID and finally generate inferences. You can refer to the console screenshots in the amazon.com/L7IhATl9oYmv/Custom-Model-Import-launch-Blog#temp:C:WUYbd68d74a722241fead00bc60f” target=”_blank” rel=”noopener”>earlier section for how to import a model using the amazon Bedrock console.
Parameter and helper function set up
First, we’ll create a few helper functions and set up our parameters to create the import job. The import job is responsible for collecting and deploying the model from SageMaker to amazon Bedrock. This is done by using the create_model_import_job function.
Stored safetensors need to be formatted so that the amazon S3 location is the top-level folder. The configuration files and safetensors will be stored as shown in the following figure.

Check the status and get job ARN from the response:
After a few minutes, the model will be imported, and the status of the job can be checked using get_model_import_job. The job ARN is then used to get the imported model ARN, which we will use to generate inferences.
Generating inferences using the imported custom model
The model can be invoked by using the invoke_model and converse APIs. The following is a support function that will be used to invoke and extract the generated text from the overall output.
Context set up and model response
Finally, we can use the custom model. First, we format our inquiry to match the fined-tuned prompt structure. This will make sure that the responses generated closely resemble the format used in the fine-tuning phase and are more aligned to our needs. To do this we use the template that we used to format the data used for fine-tuning. The context will be coming from your RAG solutions like amazon Bedrock Knowledgebases. For this example, we take a sample context and add to demo the concept:
The output will look similar to:

After the model has been fine-tuned and imported into amazon Bedrock, you can experiment by sending different sets of input questions and context to the model to generate a response, as shown in the following example:
Some points to note
This examples in this post are to demonstrate Custom Model Import and aren’t designed to be used in production. Because the model has been trained on only 200 samples of synthetically generated data, it’s only useful for testing purposes. You would ideally have more diverse datasets and additional samples with continuous experimentation conducted using hyperparameter tuning for your respective use case, thereby steering the model to create a more desirable output. For this post, ensure that the model temperature parameter is set to 0 and max_tokens run time parameter is set to a lower values such as 100–150 tokens so that a succinct response is generated. You can experiment with other parameters to generate a desirable outcome. See amazon-bedrock-samples/” target=”_blank” rel=”noopener”>amazon Bedrock Recipes and amazon-bedrock-samples/tree/main/custom-models/import_models” target=”_blank” rel=”noopener”>GitHub for more examples.
Best practices to consider:
This feature brings significant advantages for hosting your fine-tuned models efficiently. As we continue to develop this feature to meet our customers’ needs, there are a few points to be aware of:
- Define your test suite and acceptance metrics before starting the journey. Automating this will help to save time and effort.
- Currently, the model weights need to be all-inclusive, including the adapter weights. There are multiple methods for merging the models and we recommend experimenting to determine the right methodology. The Custom Model Import feature lets you test your model on demand.
- When creating your import jobs, add versioning to the job name to help quickly track your models. Currently, we’re not offering model versioning, and each import is a unique job and creates a unique model.
- The precision supported for the model weights is FP32, FP16, and BF16. Run tests to validate that these will work for your use case.
- The maximum concurrency that you can expect for each model will be 16 per account. Higher concurrency requests will cause the service to scale and increase the number of model copies.
- The number of model copies active at any point in time will be available through amazon CloudWatch See Import a customized model to amazon Bedrock for more information.
- As of the writing this post, we are releasing this feature in the US-EAST-1 and US-WEST-2 AWS Regions only. We will continue to release to other Regions. Follow Model support by AWS Region for updates.
- The default import quota for each account is three models. If you need more for your use cases, work with your account teams to increase your account quota.
- The default throttling limits for this feature for each account will be 100 invocations per second.
- You can use this amazon-bedrock-samples/blob/main/custom-models/import_models/perf-test-imported_model.ipynb” target=”_blank” rel=”noopener”>sample notebook to performance test your models imported via this feature. This notebook is mere reference and not designed to be an exhaustive testing. We will always recommend you to run your own full performance testing along with your end to end testing including functional and evaluation testing.
Now available
amazon Bedrock Custom Model Import is generally available today in amazon Bedrock in the US-East-1 (N. Virginia) and US-West-2 (Oregon) AWS Regions. See the full Region list for future updates. To learn more, see the Custom Model Import product page and pricing page.
Give Custom Model Import a try in the amazon Bedrock console today and send feedback to amazon-bedrock” target=”_blank” rel=”noopener”>AWS re:Post for amazon Bedrock or through your usual AWS Support contacts.
About the authors
 Paras Mehra is a Senior Product Manager at AWS. He is focused on helping build amazon SageMaker Training and Processing. In his spare time, Paras enjoys spending time with his family and road biking around the Bay Area.
Paras Mehra is a Senior Product Manager at AWS. He is focused on helping build amazon SageMaker Training and Processing. In his spare time, Paras enjoys spending time with his family and road biking around the Bay Area.
 Jay Pillai is a Principal Solutions Architect at amazon Web Services. In this role, he functions as the Lead Architect, helping partners ideate, build, and launch Partner Solutions. As an Information technology Leader, Jay specializes in artificial intelligence, generative ai, data integration, business intelligence, and user interface domains. He holds 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
Jay Pillai is a Principal Solutions Architect at amazon Web Services. In this role, he functions as the Lead Architect, helping partners ideate, build, and launch Partner Solutions. As an Information technology Leader, Jay specializes in artificial intelligence, generative ai, data integration, business intelligence, and user interface domains. He holds 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
 Shikhar Kwatra is a Sr. Partner Solutions Architect at amazon Web Services, working with leading Global System Integrators. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the ai/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and support the GSI partners in building strategic industry solutions on AWS.
Shikhar Kwatra is a Sr. Partner Solutions Architect at amazon Web Services, working with leading Global System Integrators. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the ai/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and support the GSI partners in building strategic industry solutions on AWS.
 Claudio Mazzoni is a Sr GenAI Specialist Solutions Architect at AWS working on world class applications guiding costumers through their implementation of GenAI to reach their goals and improve their business outcomes. Outside of work Claudio enjoys spending time with family, working in his garden and cooking Uruguayan food.
Claudio Mazzoni is a Sr GenAI Specialist Solutions Architect at AWS working on world class applications guiding costumers through their implementation of GenAI to reach their goals and improve their business outcomes. Outside of work Claudio enjoys spending time with family, working in his garden and cooking Uruguayan food.
 Yanyan Zhang is a Senior Generative ai Data Scientist at amazon Web Services, where she has been working on cutting-edge ai/ML technologies as a Generative ai Specialist, helping customers leverage GenAI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a Ph.D. degree in Electrical Engineering. Outside of work, she loves traveling, working out and exploring new things.
Yanyan Zhang is a Senior Generative ai Data Scientist at amazon Web Services, where she has been working on cutting-edge ai/ML technologies as a Generative ai Specialist, helping customers leverage GenAI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a Ph.D. degree in Electrical Engineering. Outside of work, she loves traveling, working out and exploring new things.
 Simon Zamarin is an ai/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an ai/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Rupinder Grewal is a Senior ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.





{kind=link}