 NEWSLETTER
NEWSLETTER
artificial intelligence (ai) and machine learning (ML) have been transformative in numerous fields, but a significant challenge remains in reproducibility of experiments. Researchers often rely on previously published work to validate or extend their findings. This process often involves running complex code from research repositories. However, setting up these repositories, configuring the environment, and resolving various technical issues such as outdated dependencies and bugs requires significant time and expertise. As ai continues to evolve, researchers are looking for ways to automate these tasks to accelerate scientific discovery.
One of the critical problems with reproducing experiments from research repositories is that these repositories are often poorly maintained. Poor documentation and outdated code make it difficult for other researchers to run experiments as intended. This problem is further complicated by the different platforms and tools required to run different experiments. Researchers spend a considerable amount of time installing dependencies, troubleshooting compatibility issues, and configuring the environment to meet the specific needs of each experiment. Addressing this problem could significantly improve the pace at which discoveries are validated and scaled across the scientific community.
Historically, methods for handling the setup and execution of research repositories have been largely manual. Researchers must possess deep knowledge of the codebase and the specific domain of study to resolve issues that arise during replication of experiments. While some tools help manage dependencies or troubleshoot bugs, these are limited in scope and effectiveness. Recent advances in large language models (LLMs) have shown potential for automating this process, such as generating code or commands to resolve issues. However, there is currently no robust method for assessing the ability of LLMs to handle the complex and often incomplete nature of real-world research repositories.
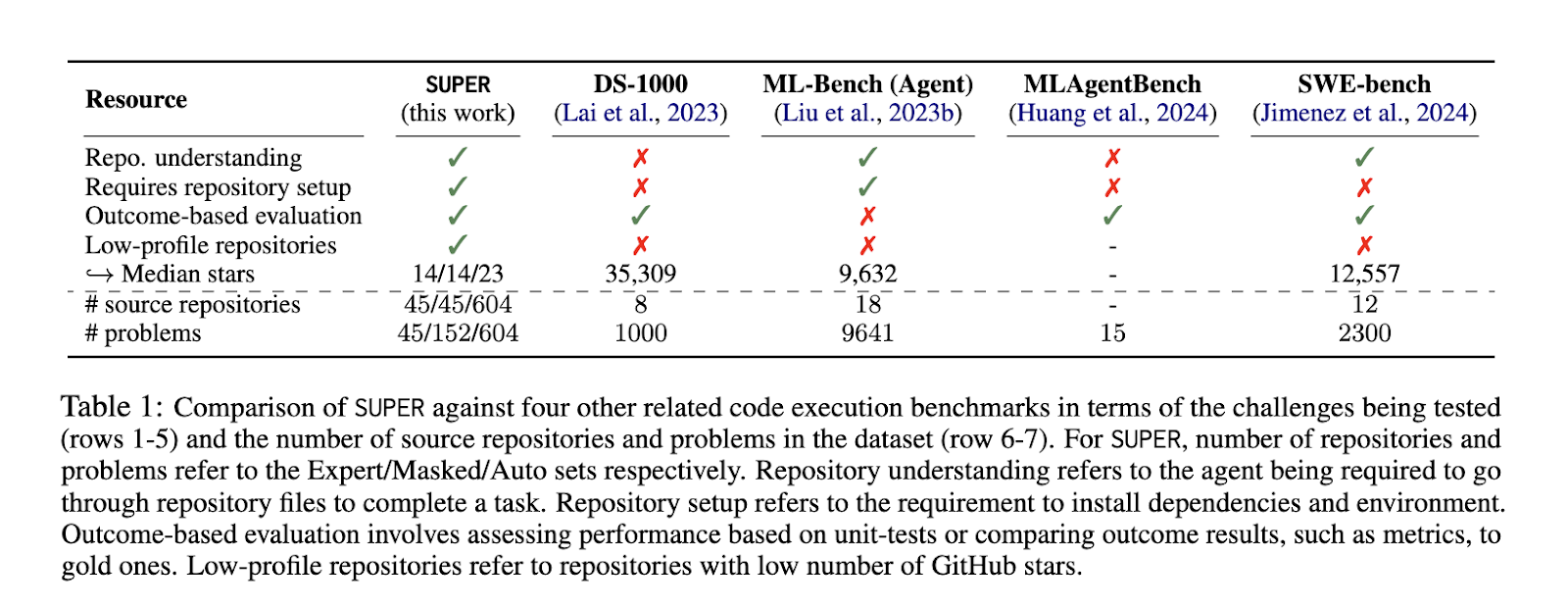
Researchers at the Allen Institute for ai and the University of Washington introduced SUPER, a benchmark designed to evaluate the ability of LLMs to configure and execute tasks from research repositories. Unlike other tools that focus on popular, well-maintained repositories, SUPER emphasizes the real-world challenges researchers face when using lower-profile repositories that are not always well documented. The benchmark includes a variety of scenarios that mimic the types of obstacles researchers routinely encounter. By testing LLMs on these tasks, SUPER provides a comprehensive framework for evaluating how well these models can support research tasks that involve code execution and problem solving.
The SUPER benchmark is divided into three distinct sets:
- He Expert The set includes 45 hand-selected problems based on real research tasks.
- He Masked The set breaks these problems down into 152 smaller challenges that focus on specific technical issues, such as configuring a trainer or resolving runtime exceptions.
- He Car The suite consists of 604 automatically generated tasks designed for large-scale development and model tuning.
Each problem set presents different challenges, from installing dependencies and configuring hyperparameters to troubleshooting errors and reporting metrics. The benchmark evaluates task success, partial progress, and the accuracy of the generated solutions, providing a detailed assessment of the model’s capabilities.
Evaluating the performance of LLMs on the SUPER benchmark reveals significant limitations in current models. The most advanced model tested, GPT-4o, successfully solved only 16.3% of end-to-end tasks on the Expert set and 46.1% of subproblems on the Masked set. These results highlight the difficulties in automating the setup and execution of research experiments, as even the best-performing models struggle with many tasks. Furthermore, open-source models lag far behind, completing a smaller percentage of tasks. The Auto set showed similar performance patterns, suggesting that the challenges observed in the selected sets are consistent across multiple problems. The evaluation also highlighted that agents perform better on specific tasks, such as resolving dependency conflicts or addressing runtime errors, than on more complex tasks, such as setting up new datasets or modifying training scripts.
In conclusion, the SUPER benchmark sheds light on the current limitations of LLMs in automating research tasks. Despite recent advances, there is still a considerable gap between the capabilities of these models and the complex needs of researchers working with real-world repositories. The results of the SUPER benchmark indicate that while LLMs can be useful in solving well-defined technical problems, they are not yet capable of handling the full range of tasks required for the complete automation of research experiments. This benchmark provides a valuable resource for the ai community to measure and improve, offering a path forward for the development of more sophisticated tools that could one day fully support scientific research.
Take a look at the Paper, GitHuband HF PageAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Nikhil is a Consultant Intern at Marktechpost. He is pursuing an integrated dual degree in Materials from Indian Institute of technology, Kharagpur. Nikhil is an ai and Machine Learning enthusiast who is always researching applications in fields like Biomaterials and Biomedical Science. With a strong background in Materials Science, he is exploring new advancements and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}