 NEWSLETTER
NEWSLETTER
Introduction
artificial intelligence (ai) is rapidly changing industries around the world, including healthcare, autonomous vehicles, banking, and customer service. While building ai models gets a lot of attention, ai inference (the process of applying a trained model to new data to make predictions) is where real-world impact occurs. As businesses become more reliant on ai-powered applications, the demand for efficient, scalable, and low-latency inference solutions has never been greater.
This is where NVIDIA NIM comes into the picture. NVIDIA NIM is designed to help developers deploy ai models as microservices, simplifying the process of delivering inference solutions at scale. In this blog, we will delve into the capabilities of NIM, check out some models that use the NIM API, and how it is revolutionizing ai inference.
Learning outcomes
- Understand the importance of ai inference and its impact on various industries.
- Learn about the capabilities and benefits of NVIDIA NIM for deploying ai models.
- Learn how to access and use pre-trained models through the NVIDIA NIM API.
- Discover the steps to measure inference speed for different ai models.
- Explore practical examples of using NVIDIA NIM for both text generation and image creation.
- Learn about NVIDIA NIM's modular architecture and its benefits for scalable ai solutions.
This article was published as part of the Data Science Blogathon.
What is NVIDIA NIM?
NVIDIA NIM is a platform that uses microservices to facilitate ai inference in real-life applications. Microservices are small services that can function on their own but can also be combined to create larger systems that can grow. By embedding out-of-the-box ai models in microservices, NIM helps developers use these models quickly and easily, without needing to think about infrastructure or how to scale it.
NVIDIA NIM Key Features
- Pre-trained ai models: NIM comes with a library of pre-trained models for various tasks such as speech recognition, natural language processing (NLP), computer vision, and more.
- Optimized for performance: NIM leverages powerful NVIDIA GPUs and software optimizations (such as TensorRT) to deliver high-performance, low-latency inference.
- Modular design: Developers can mix and match microservices depending on the specific inference task they need to perform.
Understanding the key features of NVIDIA NIM
Let us understand in detail the key features of NVIDIA NIM below:
Pre-trained models for fast deployment
NVIDIA NIM provides a wide range of pre-trained models that are ready for immediate deployment. These models cover various ai tasks, including:

Low latency inference
It's very good for quick responses, so it tends to work well for applications that need real-time processing. For example, in an autonomous vehicle, decisions are made using live data from sensors and cameras. NIM ensures that such ai models work fast enough with that type of data as real-time needs demand.
How to access models from NVIDIA NIM
Next we will see how we can access the models from NVIDIA NIM:
- Sign in via email to NVIDIA NIM here.
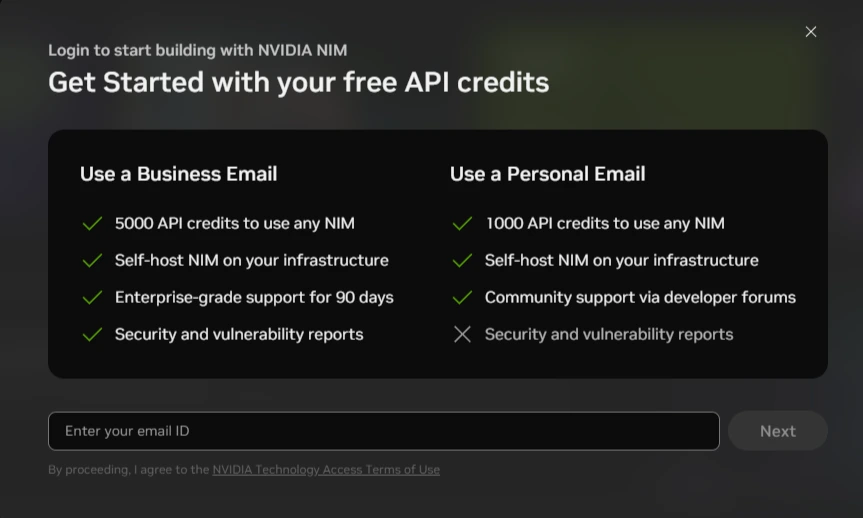
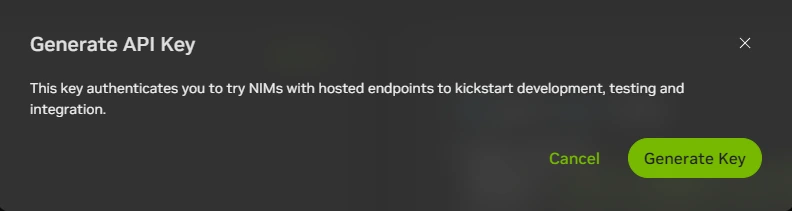
- Choose any model and get your API key.
Checking inference speed using different models
In this section, we will explore how to evaluate the inference speed of various ai models. Understanding the response time of these models is crucial for applications that require real-time processing. We'll start with the reasoning model, focusing specifically on the Llama-3.2-3b instruction preview.
Reasoning model
The Llama-3.2-3b-instruct model performs natural language processing tasks, effectively understanding and responding to user queries. Below we provide the necessary requirements and a step-by-step guide to setting up the environment to run this model.
Requirements
Before you begin, make sure you have the following libraries installed:
openai: This library allows interaction with OpenAI models.python-dotenv: This library helps manage environment variables.
openai
python-dotenvCreate a virtual environment and activate it
To ensure a clean setup, we will create a virtual environment. This helps manage dependencies effectively without affecting the overall Python environment. Follow the following commands to configure it:
python -m venv env
.\env\Scripts\activateCode implementation
Now, we will implement the code to interact with the Llama-3.2-3b-instruct model. The following script initializes the model, accepts user input, and calculates the inference speed:
from openai import OpenAI
from dotenv import load_dotenv
import os
import time
load_dotenv()
llama_api_key = os.getenv('NVIDIA_API_KEY')
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = llama_api_key)
user_input = input("What you want to ask: ")
start_time = time.time()
completion = client.chat.completions.create(
model="meta/llama-3.2-3b-instruct",
messages=({"role":"user","content":user_input}),
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=True
)
end_time = time.time()
for chunk in completion:
if chunk.choices(0).delta.content is not None:
print(chunk.choices(0).delta.content, end="")
response_time = end_time - start_time
print(f"\nResponse time: {response_time} seconds")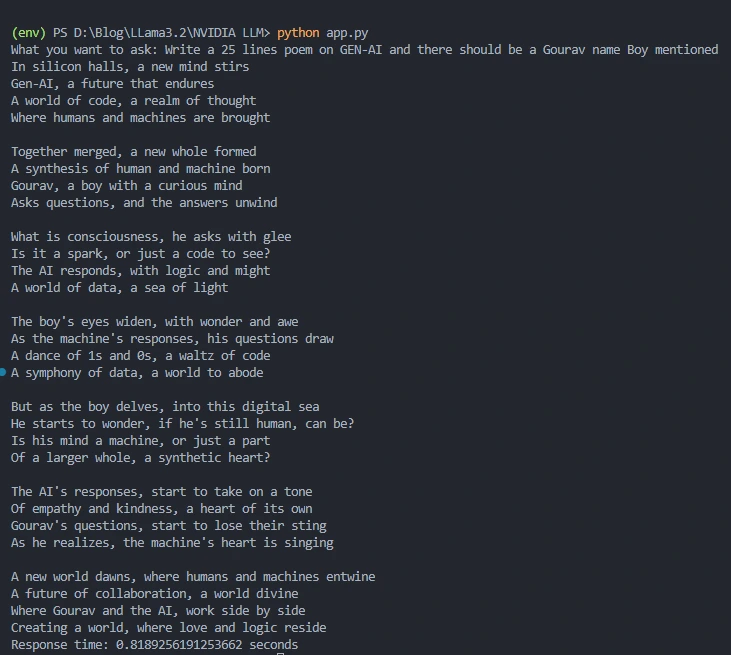
Response time
The result will include the response time, allowing you to evaluate the efficiency of the model: 0.8189256191253662 seconds
Stable diffusion 3 medium
Stable Diffusion 3 Medium is a cutting-edge generative ai model designed to transform text prompts into stunning visual images, allowing creators and developers to explore new realms of artistic expression and innovative applications. Below we have implemented code that demonstrates how to use this model to generate captivating images.
Code implementation
import requests
import base64
from dotenv import load_dotenv
import os
import time
load_dotenv()
invoke_url = "https://ai.api.nvidia.com/v1/genai/stabilityai/stable-diffusion-3-medium"
api_key = os.getenv('STABLE_DIFFUSION_API')
headers = {
"Authorization": f"Bearer {api_key}",
"Accept": "application/json",
}
payload = {
"prompt": input("Enter Your Image Prompt Here: "),
"cfg_scale": 5,
"aspect_ratio": "16:9",
"seed": 0,
"steps": 50,
"negative_prompt": ""
}
start_time = time.time()
response = requests.post(invoke_url, headers=headers, json=payload)
end_time = time.time()
response.raise_for_status()
response_body = response.json()
image_data = response_body.get('image')
if image_data:
image_bytes = base64.b64decode(image_data)
with open('generated_image.png', 'wb') as image_file:
image_file.write(image_bytes)
print("Image saved as 'generated_image.png'")
else:
print("No image data found in the response")
response_time = end_time - start_time
print(f"Response time: {response_time} seconds")Production:


Response time: 3.790468692779541 seconds
Conclusion
With the increasing speed of ai applications, solutions that can perform many tasks effectively are required. A crucial part of this area is NVIDIA NIM, as it helps businesses and developers use ai easily and in a scalable way by using pre-trained ai models combined with fast GPU processing and microservices setup. They can quickly deploy real-time applications in both cloud and edge environments, making them very flexible and durable in the field.
Key takeaways
- NVIDIA NIM leverages microservices architecture to efficiently scale ai inference by deploying models in modular components.
- NIM is designed to take full advantage of NVIDIA GPUs, using tools like TensorRT to accelerate inference and achieve faster performance.
- Ideal for industries such as healthcare, autonomous vehicles, and industrial automation, where low-latency inference is critical.
Frequently asked questions
A. The core components include the inference server, pre-trained models, TensorRT optimizations, and microservices architecture to handle ai inference tasks more efficiently.
A. NVIDIA NIM is designed to work easily with today's ai models. It allows developers to add pre-trained models from different sources to their applications. This is done by offering containerized microservices with standard APIs. This makes it easy to include these models in existing systems without many changes. It basically acts as a bridge between ai models and applications.
A. NVIDIA NIM removes the barriers to building ai applications by providing industry-standard APIs for developers, allowing them to create robust ai co-pilots, chatbots, and assistants. It also ensures that building ai applications is easier for IT and DevOps teams in terms of installing ai models within their controlled environments.
A. If you use your personal email, you will get 1000 API credits and 5000 API credits for business email.
The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.

Hi, I'm Gourav, a data science enthusiast with a medium background in statistical analysis, machine learning and data visualization. My journey into the world of data began with the curiosity to unravel insights from data sets.





