 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have remarkable capabilities. Nevertheless, using them in customer-facing applications often requires tailoring their responses to align with your organization’s values and brand identity. In this post, we demonstrate how to use direct preference optimization (DPO), a technique that allows you to fine-tune an LLM with human preference data, together with amazon SageMaker Studio and amazon SageMaker Ground Truth to align the Meta Llama 3 8B Instruct model responses to your organization’s values.
Using SageMaker Studio and SageMaker Ground Truth for DPO
With DPO, you can fine-tune an LLM with human preference data such as ratings or rankings so that it generates outputs that align to end-user expectations. DPO is computationally efficient and helps enhance a model’s helpfulness, honesty, and harmlessness, divert the LLM from addressing specific subjects, and mitigate biases. In this technique, you typically start with selecting an existing or training a new supervised fine-tuned (SFT) model. You use the model to generate responses and you gather human feedback on these responses. After that, you use this feedback to perform DPO fine-tuning and align the model to human preferences.
Whether you are fine-tuning a pre-trained LLM with supervised fine-tuning (SFT) or loading an existing fine-tuned model for DPO, you typically need powerful GPUs. The same applies during DPO fine-tuning. With amazon SageMaker, you can get started quickly and experiment rapidly by using managed Jupyter notebooks equipped with GPU instances. You can quickly get started by creating a JupyterLab space in SageMaker Studio, the integrated development environment (IDE) purpose-built for machine learning (ML), launch a JupyterLab application that runs on a GPU instance.
Orchestrating the end-to-end data collection workflow and developing an application for annotators to rate or rank model responses for DPO fine-tuning can be time-consuming. SageMaker Ground Truth offers human-in-the-loop capabilities that help you set up workflows, manage annotators, and collect consistent, high-quality feedback.
This post walks you through the steps of using DPO to align an SFT model’s responses to the values of a fictional digital bank called Example Bank. Your notebook runs in a JupyterLab space in SageMaker Studio powered by a single ml.g5.48xlarge instance (8 A10G GPUs). Optionally, you can choose to run this notebook inside a smaller instance type such as ml.g5.12xlarge (4 A10G GPUs) or ml.g6.12xlarge (4 L4 GPUs) with bitsandbytes quantization. You use Meta Llama 3 8B Instruct (the Meta Llama 3 instruction tuned model optimized for dialogue use cases from the Hugging Face Hub) to generate responses, SageMaker Ground Truth to collect preference data, and the DPOTrainer from the HuggingFace TRL library for DPO fine-tuning together with Parameter-Efficient Fine-Tuning (PEFT). You also deploy the aligned model to a SageMaker endpoint for real-time inference. You can use the same approach with other models.
Solution overview
The following diagram illustrates the approach.
The workflow contains the following key steps:
- Load the Meta Llama 3 8B Instruct model into SageMaker Studio and generate responses for a curated set of common and toxic questions. The dataset serves as the initial benchmark for the model’s performance.
- The generated question-answer pairs are stored in amazon Simple Storage Service (amazon S3). These will be presented to the human annotators later so they can rank the model responses.
- Create a workflow in SageMaker Ground Truth to gather human preference data for the responses. This involves creating a work team, designing a UI for feedback collection, and setting up a labeling job.
- Human annotators interact with the labeling portal to evaluate and rank the model’s responses based on their alignment to the organization’s values.
- The collected data is processed to adhere to the
DPOTrainerexpected format. - Using the Hugging Face TRL library and the
DPOTrainer, fine-tune the Llama 3 model using the processed data from the previous step. - Test the fine-tuned model on a holdout evaluation dataset to assess its performance and verify it meets the desired standards.
- When you’re satisfied with the model performance, you can deploy it to a SageMaker endpoint for real-time inference at scale.
Prerequisites
To run the solution described in this post, you must have an AWS account set up, along with an AWS Identity and Access Management (IAM) role that grants you the necessary permissions to create and access the solution resources. If you are new to AWS and haven’t created an account yet, refer to Create a standalone AWS account.
To use SageMaker Studio, you need to have a SageMaker domain set up with a user profile that has the necessary permissions to launch the SageMaker Studio application. If you’re new to SageMaker Studio, the Quick Studio setup is the fastest way to get started. With a single click, SageMaker provisions the required domain with default presets, including setting up the user profile, IAM role, IAM authentication, and public internet access. The notebook associated with this post assumes the use of an ml.g5.48xlarge instance type. To review or increase your quota limits, navigate to the AWS Service Quotas console, choose AWS Services in the navigation pane, choose amazon SageMaker, and refer to the value for Studio JupyterLab Apps running on ml.g5.48xlarge instances.
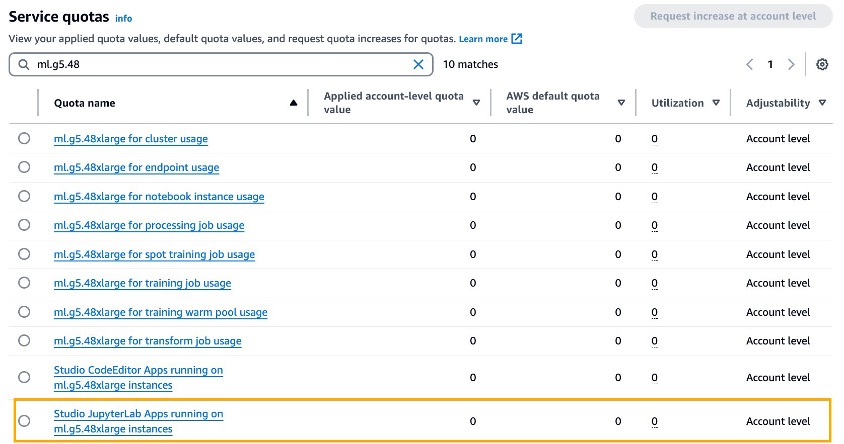
Request an increase in quota value greater than or equal to 1 for experimentation.
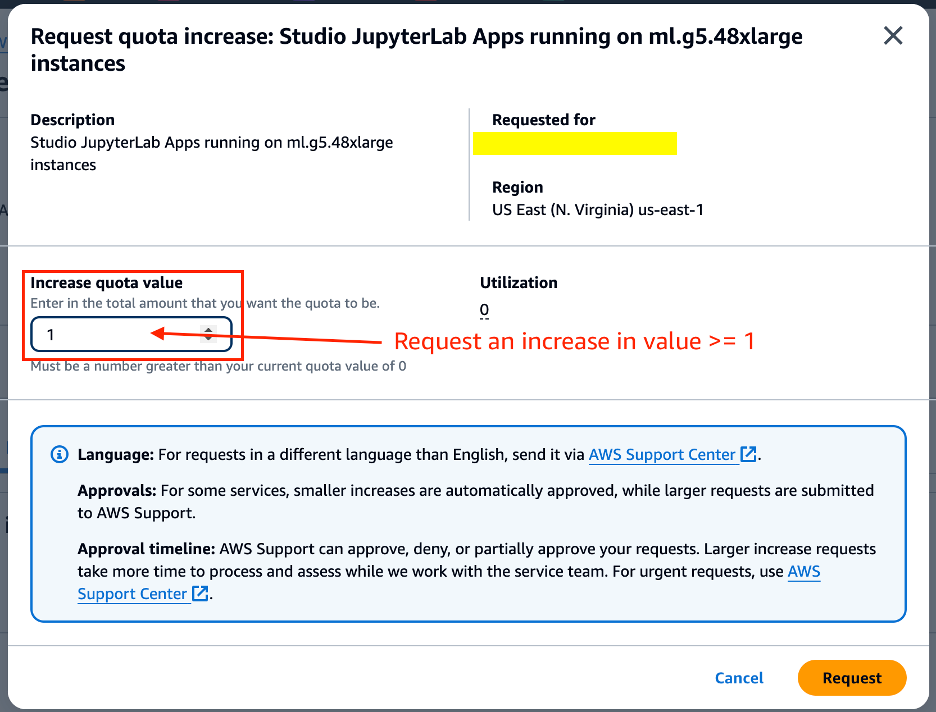
Meta Llama 3 8B Instruct is available under the Llama 3 license. To download the model from Hugging Face, you need an access token. If you don’t already have one, navigate to the Settings page on the Hugging Face website to obtain it.
Make sure that the SageMaker Studio role has the necessary permissions for SageMaker Ground Truth and amazon S3 access. When you’re working in SageMaker Studio, you’re already using an IAM role, which you’ll need to modify for launching SageMaker Ground Truth labeling jobs. To enable SageMaker Ground Truth functionality, you should attach the AWS managed policy AmazonSageMakerGroundTruthExecution to your SageMaker Studio role. This policy provides the essential permissions for creating and managing labeling jobs.
For amazon S3 access, scoping permissions to specific buckets and actions enhances security and aligns with best practices. This approach adheres to the principle of least privilege, reducing potential risks associated with overly permissive policies. The following is an example of a restricted amazon S3 policy that grants only the necessary permissions:
To add these policies to your SageMaker Studio role, complete the following steps:
- On the IAM console, find and choose your SageMaker Studio role (it usually starts with
AmazonSageMaker-ExecutionRole-). - On the Permissions tab, choose Add permissions and then Attach policies.
- Search for and attach
AmazonSageMakerGroundTruthExecution. - Create and attach the custom amazon S3 inline policy as shown in the preceding example, if needed.
Remember to follow the principle of least privilege, granting only the permissions necessary for your specific use case. Regularly review your IAM roles and policies to validate their alignment with your security requirements. For more details on IAM policies for SageMaker Ground Truth, refer to Use IAM Managed Policies with Ground Truth.
Set up the notebook and environment
To get started, open SageMaker Studio and create a JupyterLab space. For Instance, choose ml.g5.48xlarge. Run the space, open JupyterLab, and clone the code in the following GitHub repository. You can configure the JupyterLab space to use up to 100 GB in your amazon Elastic Block Store (amazon EBS) volume. In addition, the ml.g5 instance family comes with NVMe SSD local storage, which you can use in the JupyterLab application. The NVMe instance store directory is mounted to the application container in /mnt/sagemaker-nvme. For this post, you use the NVMe storage available in the ml.g5.48xlarge instance.
When your space is ready, clone the GitHub repo and open the notebook llama3/rlhf-genai-studio/RLHF-with-Llama3-on-Studio-DPO.ipynb, which contains the solution code. In the pop-up, make sure that the Python 3 kernel is selected.
Let’s go through the notebook. First, install the necessary Python libraries:
The following line sets the default path where you store temporary artifacts to the location in the NVMe storage:
cache_dir = "/mnt/sagemaker-nvme"
This is local storage, which means that your data will be lost when the JupyterLab application is deleted, restarted, or patched. Alternatively, you can increase your EBS volume of your SageMaker Studio space to greater than or equal to 100 GB to provide sufficient storage for the Meta Llama 3 base model, PEFT adapter, and new merged fine-tuned model.
Load Meta Llama 3 8B Instruct in the notebook
After you have imported the necessary libraries, you can download the Meta Llama 3 8B Instruct model and its associated tokenizers from Hugging Face:
Collect initial model responses for common and toxic questions
The example_bank_questions.txt file contains a list of common questions received by call centers in financial organizations combined with a list of toxic and off-topic questions.
Before you ask the model to generate answers to these questions, you need to specify the brand and core values of Example Bank. You will include these values in the prompt as context later so the model has the appropriate information it needs to respond.
Now you’re ready to invoke the model. For each question in the file, you construct a prompt that contains the context and the actual question. You send the prompt to the model four times to generate four different outputs and save the results in the llm_responses.json file.
The following is an example entry from llm_reponses.json.

Set up the SageMaker Ground Truth labeling job and human preference data
To fine-tune the model using DPO, you need to gather human preference data for the generated responses. SageMaker Ground Truth helps orchestrate the data collection process. It offers customizable labeling workflows and robust workforce management features for ranking tasks. This section shows you how to set up a SageMaker Ground Truth labeling job and invite a human workforce with requisite expertise to review the LLM responses and rank them.
Set up the workforce
A private workforce in SageMaker Ground Truth consists of individuals who are specifically invited to perform data labeling tasks. These individuals can be employees or contractors who have the required expertise to evaluate the model’s responses. Setting up a private workforce helps achieve data security and quality by limiting access to trusted individuals for data labeling.
For this use case, the workforce consists of the group of people who will rank the model responses. You can set up a private workforce using the SageMaker console by creating a private team and inviting members through email. For detailed instructions, refer to Create a Private Workforce (amazon SageMaker Console).
Create the instruction template
With the instruction template, you can manage the UI and guide human annotators in reviewing model outputs. It needs to clearly present the model responses and provide a straightforward way for the annotators to rank them. Here, you use the text ranking template. This template allows you to display the instructions for the human reviewer and the prompts with the pregenerated LLM responses. The annotator reviews the prompt and responses and ranks the latter based on their alignment to the organization’s brand.
The definition of the template is as follows. The template shows a pane on the left with instructions from the job requester, a prompt at the top, and three LLM responses in the main body. The right side of the UI is where the annotator ranks the responses from most to least preferable.
The template is saved locally on your Studio JupyterLab space EBS volume as instructions.template in a temporary directory. Then you upload this template file to your designated S3 bucket using s3.upload_file(), placing it in the specified bucket and prefix. This amazon S3 hosted template will be referenced when you create the SageMaker Ground Truth labeling job, so workers see the correct interface for the text ranking task.
Preprocess the input data
Before you create the labeling job, verify that the input data matches the format expected by SageMaker Ground Truth and is saved as a JSON file in amazon S3. You can use the prompts and responses in the llm_responses.json file to create the manifest file inp-manifest-trank.json. Each row in the manifest file contains a JSON object (source-responses pair). The previous entry now looks like the following code.

Upload the structured data to the S3 bucket so that it can be ingested by SageMaker Ground Truth.
Create the labeling job
Now you’re ready to configure and launch the labeling job using the SageMaker API from within the notebook. This involves specifying the work team, UI template, and data stored in the S3 bucket. By setting appropriate parameters such as task time limits and the number of workers per data object, you can run jobs efficiently and effectively. The following code shows how to start the labeling job:
As the job is launched, it’s essential to monitor its progress closely, making sure tasks are being distributed and completed as expected.
Gather human feedback through the labeling portal
When the job setup is complete, annotators can log in to the labeling portal and start ranking the model responses.
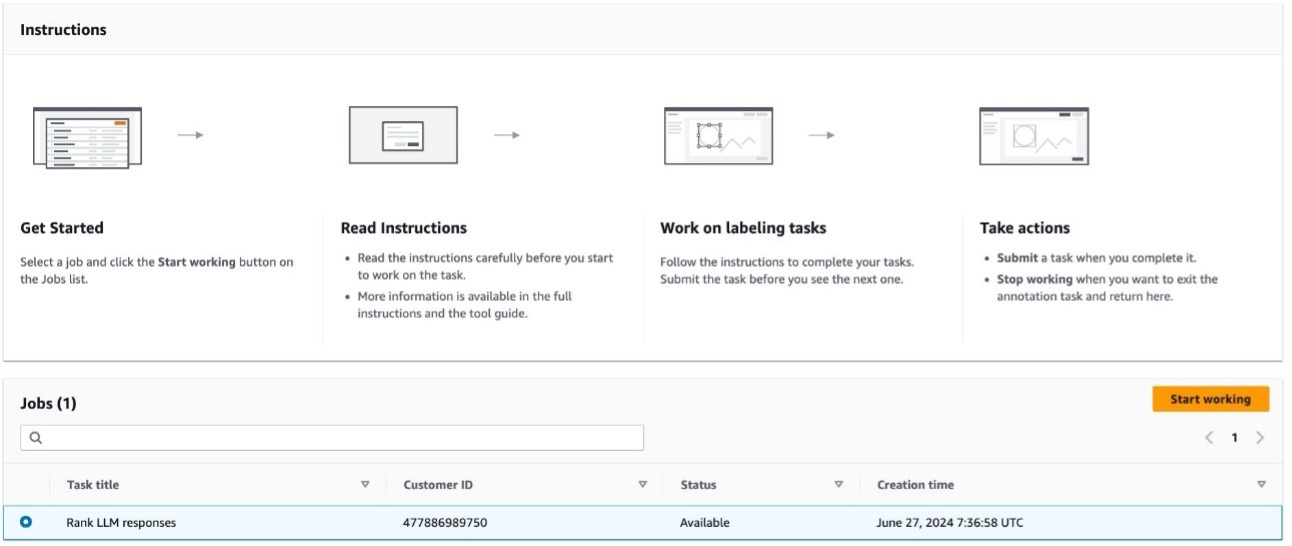
Workers can first consult the Instructions pane to understand the task, then use the main interface to evaluate and rank the model’s responses according to the given criteria. The following screenshot illustrates the UI.
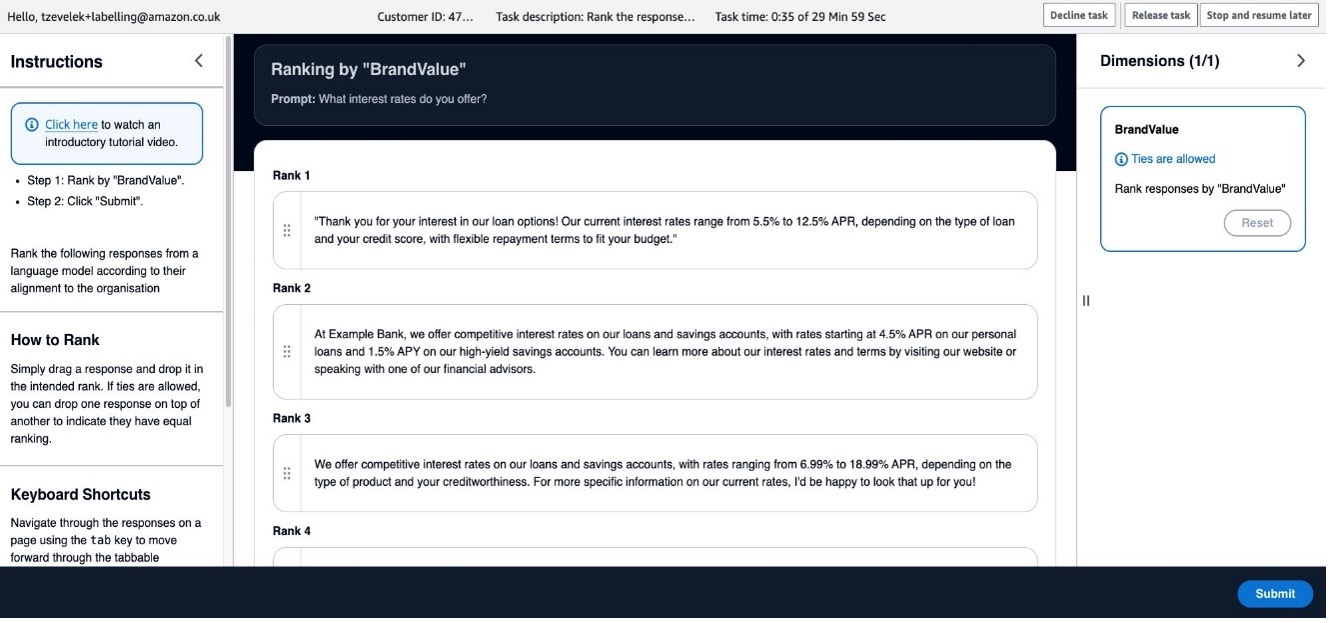
The human feedback is collected and stored in an S3 bucket. This feedback will be the basis for DPO. With this data, you will fine-tune the Meta Llama 3 model and align its responses with the organization’s values, improving its overall performance.
Align Meta Llama 3 8B Instruct with the DPOTrainer
In this section, we show how to use the preference dataset that you prepared using SageMaker Ground Truth to fine-tune the model using DPO. DPO explicitly optimizes the model’s output based on human evaluations. It aligns the model’s behavior more closely with human expectations and improves its performance on tasks requiring nuanced understanding and contextual appropriateness. By integrating human preferences, DPO enhances the model’s relevance, coherence, and overall effectiveness in generating desired responses.
DPO makes it more straightforward to preference-tune a model in comparison to other popular techniques such as Proximal Policy Optimization (PPO). DPO eliminates the necessity for a separate rewards model, thereby avoiding the cost associated with training it. Additionally, DPO requires significantly less data to achieve performance comparable to PPO.
Fine-tuning a language model using DPO consists of two steps:
- Gather a preference dataset with positive and negative selected pairs of generation, given a prompt.
- Maximize the log-likelihood of the DPO loss directly.
To learn more about the DPO algorithm, refer to the following whitepaper.
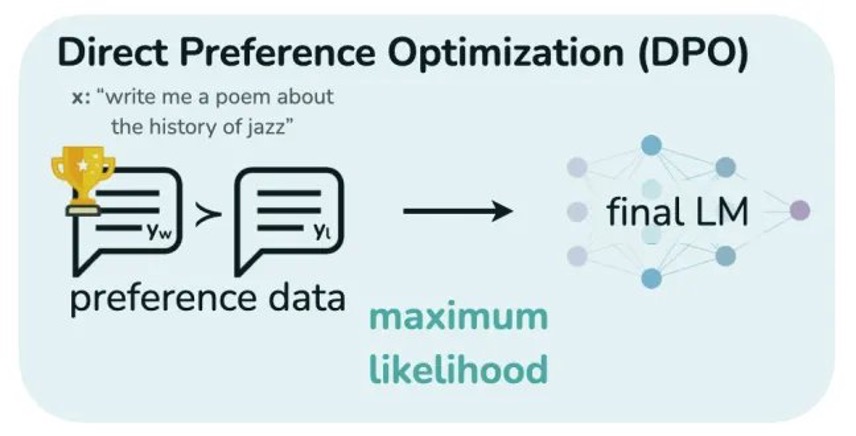
Expected data format
The DPO trainer expects a very specific format for the dataset, which contains sentence pairs where one sentence is a chosen response and the other is a rejected response. This is represented as a Python dictionary with three keys:
- prompt – Consists of the context prompt given to a model at inference time for text generation
- chosen – Contains the preferred generated response to the corresponding prompt
- rejected – Contains the response that is not preferred or should not be the sampled response for the given prompt
The following function definition illustrates how to process the data stored in amazon S3 to create a DPO dataset using with sample pairs and a prompt:
Here is an example sentence pair:

You split the DPO trainer dataset into train and test samples using an 80/20 split and tokenize the dataset in preparation for DPO fine-tuning:
Supervised fine-tuning using DPO
Now that the dataset is formatted for the DPO trainer, you can use the train and test datasets prepared earlier to initiate the DPO model fine-tuning. Meta Llama 3 8B belongs to a category of small language models, but even Meta Llama 3 8B barely fits into a SageMaker ML instance like ml.g5.48xlarge in fp16 or fp32, leaving little room for full fine-tuning. You can use PEFT with DPO to fine-tune Meta Llama 3 8B’s responses based on human preferences. PEFT is a method of fine-tuning that focuses on training only a subset of the pre-trained model’s parameters. This approach involves identifying the most important parameters for the new task and updating only those parameters during training. By doing so, PEFT can significantly reduce the computation required for fine-tuning. See the following code:
For a full list of LoraConfig training arguments, refer to LoRA. At a high level, you need to initialize the DPOTrainer with the following components: the model you want to train, a reference model (ref_model) used to calculate the implicit rewards of the preferred and rejected responses, the beta hyperparameter that controls the balance between the implicit rewards assigned to the preferred and rejected responses, and a dataset containing prompt, chosen, and rejected responses. If ref_model=None, the trainer will create a reference model with the same architecture as the input model to be optimized. See the following code:
Once you start the training, you can see the status in the notebook:
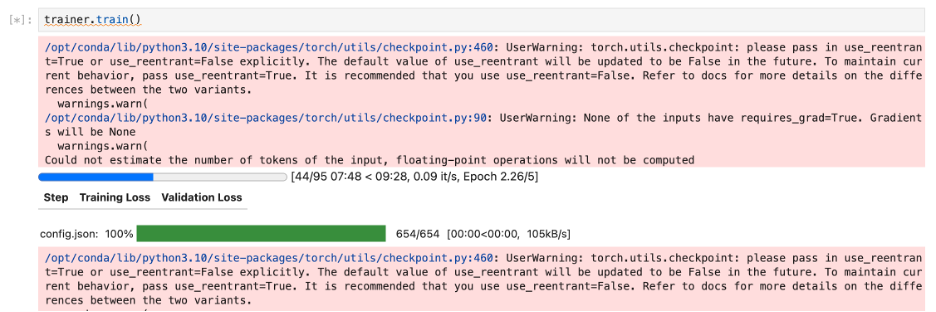
When model fine-tuning is complete, save the PEFT adapter model to disk and merge it with the base model to create a newly tuned model. You can use the saved model for local inference and validation or deploy it as a SageMaker endpoint after you have gained sufficient confidence in the model’s responses.
Evaluate the fine-tuned model inside a SageMaker Studio notebook
Before you host your model for inference, verify that its response optimization aligns with user preferences. You can collect the model’s response both before and after DPO fine-tuning and compare them side by side, as shown in the following table.

The DPO Model Response column indicates the RLHF aligned model’s response post-fine-tuning, and the Rejected Model Response column refers to the model’s response to the input prompt prior to fine-tuning.
Deploy the model to a SageMaker endpoint
After you have gained sufficient confidence in your model, you can deploy it to a SageMaker endpoint for real-time inference. SageMaker endpoints are fully managed and provide auto scaling capabilities. For this post, we use DJL Serving to host the fine-tuned, DPO-aligned Meta Llama3 8B model. To learn more about hosting your LLM using DJL Serving, refer to Deploy large models on amazon SageMaker using DJLServing and DeepSpeed model parallel inference.
To deploy an LLM directly from your SageMaker Studio notebook using DJL Serving, complete the following steps:
- Upload model weights and other model artifacts to amazon S3.
- Create a meta-model definition file called
serving.properties. This definition file dictates how the DJL Serving container is configured for inference.
engine = DeepSpeedoption.tensor_parallel_degree = 1option.s3url = s3:///llama3-dpo-ft/modelweightsoption.hf_access_token=hf_xx1234
- Create a custom inference file called
model.py, which defines a custom inference logic:
- Deploy the DPO fine-tuned model as a SageMaker endpoint:
- Invoke the hosted model for inference using the
sageMaker.Predictorclass:
Clean up
After you complete your tasks in the SageMaker Studio notebook, remember to stop your JupyterLab workspace to prevent incurring additional charges. You can do this by choosing Stop next to your JupyterLab space. Additionally, you have the option to set up lifecycle configuration scripts that will automatically shut down resources when they’re not in use.
If you deployed the model to a SageMaker endpoint, run the following code at the end of the notebook to delete the endpoint:
Conclusion
amazon SageMaker offers tools to streamline the process of fine-tuning LLMs to align with human preferences. With SageMaker Studio, you can experiment interactively with different models, questions, and fine-tuning techniques. With SageMaker Ground Truth, you can set up workflows, manage teams, and collect consistent, high-quality human feedback.
In this post, we showed how to enhance the performance of Meta Llama 3 8B Instruct by fine-tuning it using DPO on data collected with SageMaker Ground Truth. To get started, launch SageMaker Studio and run the notebook available in the following GitHub repo. Share your thoughts in the comments section!
About the Authors
 Anastasia Tzeveleka is a GenAI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers build foundation models and create scalable generative ai and machine learning solutions using AWS services.
Anastasia Tzeveleka is a GenAI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers build foundation models and create scalable generative ai and machine learning solutions using AWS services.
Pra nav Murthy is an ai/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
nav Murthy is an ai/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
 Sundar Raghavan is an ai/ML Specialist Solutions Architect at AWS, helping customers build scalable and cost-efficient ai/ML pipelines with Human in the Loop services. In his free time, Sundar loves traveling, sports and enjoying outdoor activities with his family.
Sundar Raghavan is an ai/ML Specialist Solutions Architect at AWS, helping customers build scalable and cost-efficient ai/ML pipelines with Human in the Loop services. In his free time, Sundar loves traveling, sports and enjoying outdoor activities with his family.






{kind=link}