 NEWSLETTER
NEWSLETTER
Hoy, nos complace anunciar la capacidad de ajustar el modelo Mistral 7B mediante Amazon SageMaker JumpStart. Ahora puede ajustar e implementar modelos de generación de texto de Mistral en SageMaker JumpStart usando la interfaz de usuario de Amazon SageMaker Studio con unos pocos clics o usando el SDK de SageMaker Python.
Los modelos básicos funcionan muy bien con tareas generativas, desde redactar textos y resúmenes, responder preguntas hasta producir imágenes y videos. A pesar de las grandes capacidades de generalización de estos modelos, a menudo hay casos de uso que tienen datos de dominio muy específicos (como atención médica o servicios financieros), y es posible que estos modelos no puedan proporcionar buenos resultados para estos casos de uso. Esto resulta en la necesidad de seguir ajustando estos modelos de IA generativa sobre los datos específicos del caso de uso y del dominio.
En esta publicación, demostramos cómo ajustar el modelo Mistral 7B usando SageMaker JumpStart.
¿Qué es Mistral 7B?
Mistral 7B es un modelo básico desarrollado por Mistral ai, que admite capacidades de generación de código y texto en inglés. Admite una variedad de casos de uso, como resumen de texto, clasificación, finalización de texto y finalización de código. Para demostrar la personalización del modelo, Mistral ai también lanzó un modelo Mistral 7B-Instruct para casos de uso de chat, ajustado utilizando una variedad de conjuntos de datos de conversaciones disponibles públicamente.
Mistral 7B es un modelo transformador y utiliza atención de consultas agrupadas y atención de ventana deslizante para lograr una inferencia más rápida (baja latencia) y manejar secuencias más largas. La atención de consultas agrupadas es una arquitectura que combina la atención de múltiples consultas y de múltiples cabezas para lograr una calidad de salida cercana a la atención de múltiples cabezas y una velocidad comparable a la atención de múltiples consultas. El método de atención de ventana deslizante utiliza los múltiples niveles de un modelo transformador para centrarse en la información que llegó antes, lo que ayuda al modelo a comprender un contexto más amplio. . Mistral 7B tiene una longitud de contexto de 8000 tokens, demuestra baja latencia y alto rendimiento, y tiene un rendimiento sólido en comparación con alternativas de modelos más grandes, lo que proporciona bajos requisitos de memoria en un tamaño de modelo 7B. El modelo está disponible bajo la licencia permisiva Apache 2.0, para su uso sin restricciones.
Puede ajustar los modelos utilizando la interfaz de usuario de SageMaker Studio o el SDK de SageMaker Python. Discutimos ambos métodos en esta publicación.
Ajuste a través de la interfaz de usuario de SageMaker Studio
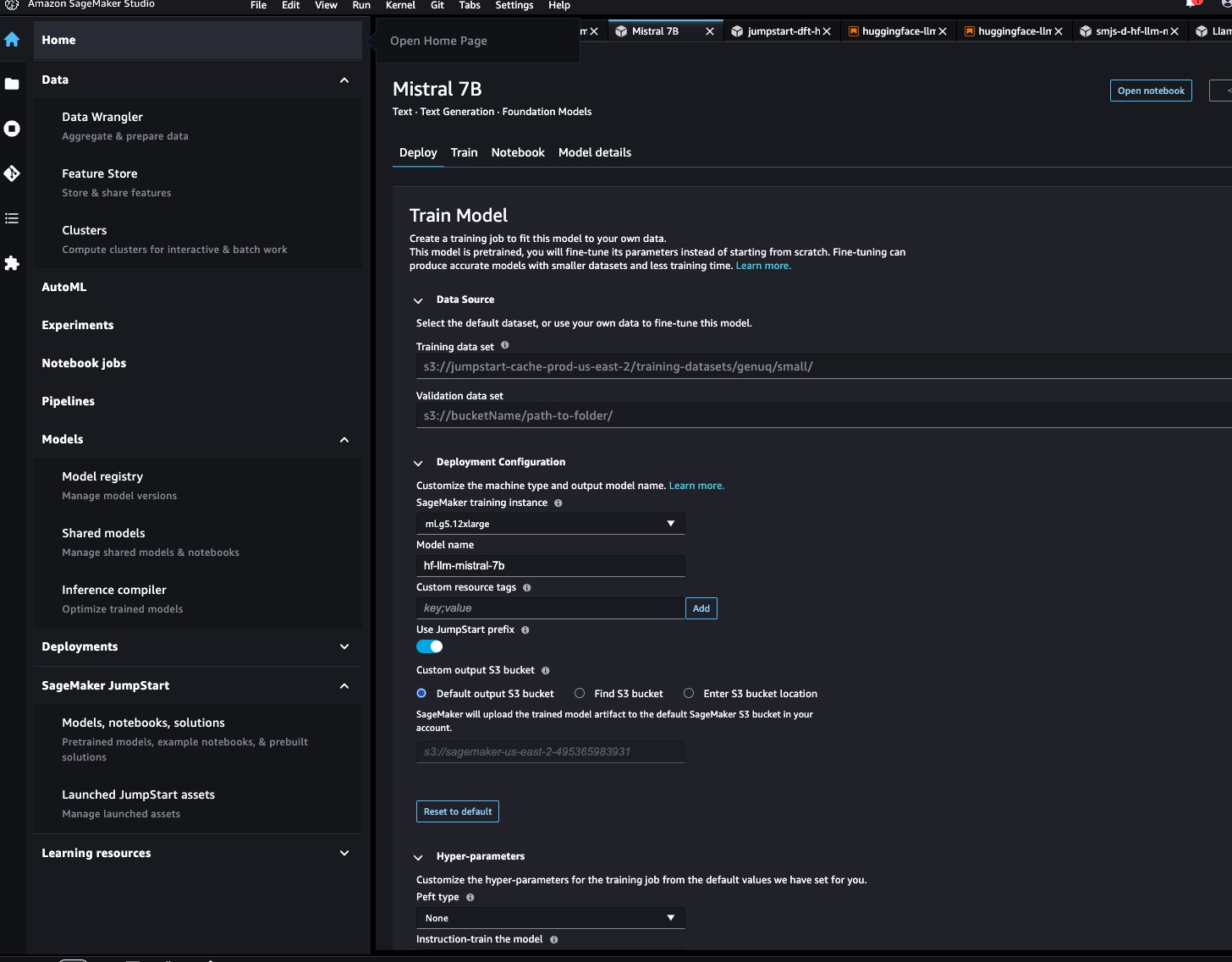
En SageMaker Studio, puede acceder al modelo Mistral a través de SageMaker JumpStart en Modelos, cuadernos y soluciones.como se muestra en la siguiente captura de pantalla.
Si no ve los modelos de Mistral, actualice su versión de SageMaker Studio apagándolo y reiniciándolo. Para obtener más información sobre las actualizaciones de versiones, consulte Cerrar y actualizar aplicaciones de Studio.
En la página del modelo, puede señalar el depósito de Amazon Simple Storage Service (Amazon S3) que contiene los conjuntos de datos de entrenamiento y validación para realizar ajustes. Además, puede configurar la configuración de implementación, los hiperparámetros y la configuración de seguridad para realizar ajustes. Luego puedes elegir Tren para iniciar el trabajo de capacitación en una instancia de SageMaker ML.
Implementar el modelo
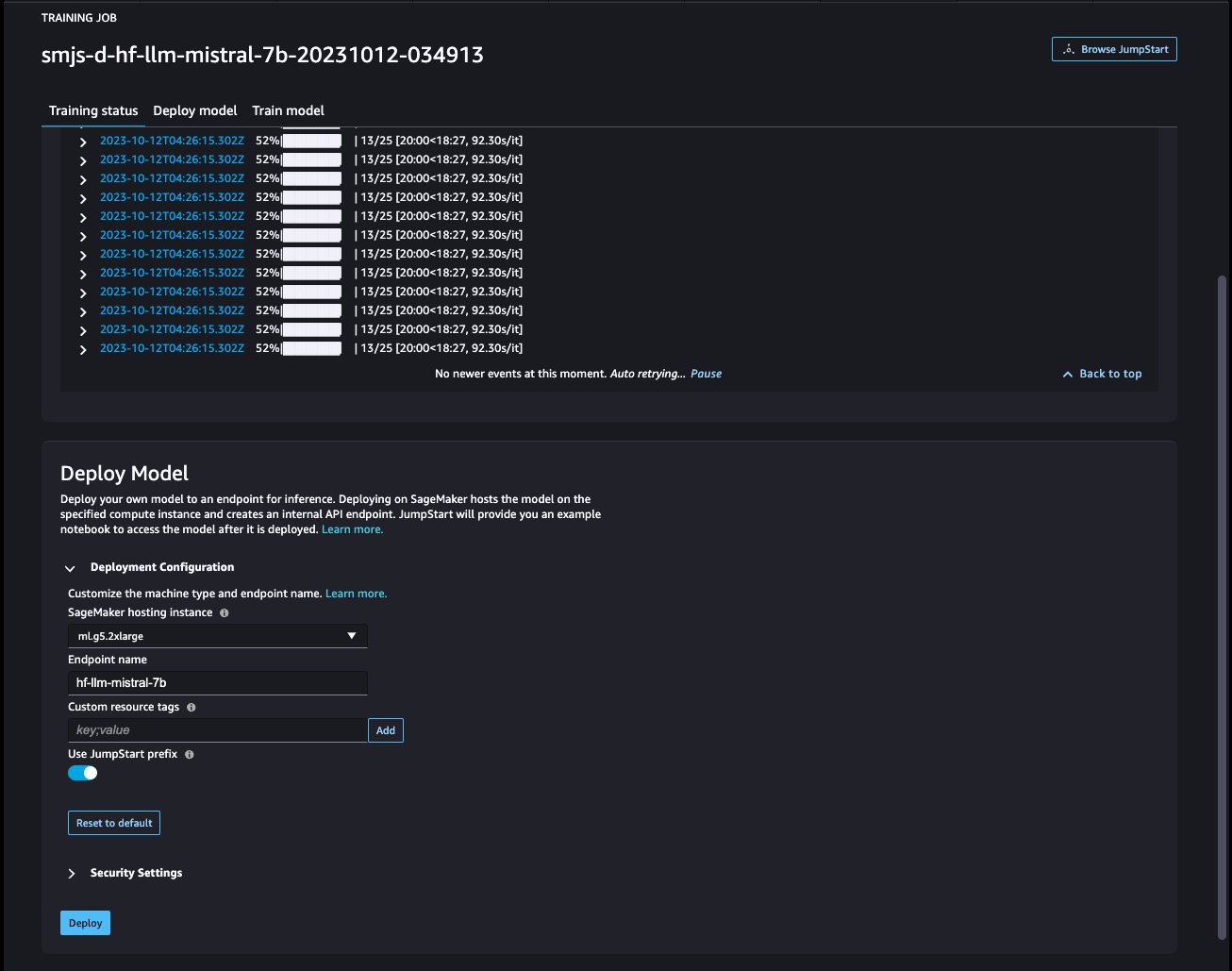
Una vez que el modelo esté ajustado, puede implementarlo usando la página del modelo en SageMaker JumpStart. La opción para implementar el modelo ajustado aparecerá cuando se complete el ajuste, como se muestra en la siguiente captura de pantalla.
Ajuste a través del SDK de SageMaker Python
También puede ajustar los modelos Mistral utilizando el SDK de SageMaker Python. El cuaderno completo está disponible en GitHub. En esta sección, proporcionamos ejemplos de dos tipos de ajuste fino.
Ajuste de instrucciones
El ajuste de instrucciones es una técnica que implica ajustar un modelo de lenguaje en una colección de tareas de procesamiento del lenguaje natural (PLN) mediante instrucciones. En esta técnica, el modelo está entrenado para realizar tareas siguiendo instrucciones textuales en lugar de conjuntos de datos específicos para cada tarea. El modelo está ajustado con un conjunto de ejemplos de entrada y salida para cada tarea, lo que permite que el modelo se generalice a nuevas tareas en las que no ha sido entrenado explícitamente, siempre y cuando se proporcionen indicaciones para las tareas. El ajuste de instrucciones ayuda a mejorar la precisión y eficacia de los modelos y es útil en situaciones en las que no hay grandes conjuntos de datos disponibles para tareas específicas.
Repasemos el código de ajuste proporcionado en el ejemplo. computadora portátil con el SDK de Python de SageMaker.
Usamos un subconjunto de conjunto de datos de plataforma rodante en un formato de ajuste de instrucciones y especifique el template.json archivo que describe los formatos de entrada y salida. Los datos de entrenamiento deben tener el formato de líneas JSON (.jsonl), donde cada línea es un diccionario que representa una única muestra de datos. En este caso le ponemos el nombre train.jsonl.
El siguiente fragmento es un ejemplo de train.jsonl. Las llaves instruction, contexty response en cada muestra debe haber entradas correspondientes {instruction}, {context}, {response} en el template.json.
La siguiente es una muestra de template.json:
Después de cargar la plantilla de solicitud y los datos de entrenamiento en un depósito de S3, puede configurar los hiperparámetros.
Luego puede iniciar el proceso de ajuste e implementar el modelo en un punto final de inferencia. En el siguiente código, utilizamos una instancia ml.g5.12xlarge:
Ajuste de la adaptación del dominio
El ajuste de la adaptación del dominio es un proceso que perfecciona un LLM previamente capacitado para que se adapte mejor a un dominio o tarea específica. Al utilizar un conjunto de datos más pequeño y específico de un dominio, el LLM se puede ajustar para comprender y generar contenido que sea más preciso, relevante y esclarecedor para ese dominio específico, sin dejar de conservar el vasto conocimiento adquirido durante su capacitación original.
El modelo Mistral se puede ajustar en cualquier conjunto de datos de dominio específico. Una vez ajustado, se espera que genere texto de dominio específico y resuelva varias tareas de PNL en ese dominio específico. Para el conjunto de datos de entrenamiento, proporcione un directorio de entrenamiento y un directorio de validación opcional, cada uno de los cuales contenga un único archivo CSV, JSON o TXT. Para formatos CSV y JSON, utilice datos del text columna o la primera columna si text no está presente. Asegúrese de que solo exista un archivo en cada directorio. Por ejemplo, los datos de entrada pueden ser presentaciones ante la SEC de Amazon como un archivo de texto:
Puede iniciar el ajuste de la adaptación del dominio especificando el hiperparámetro “instruction_tuned” como “False“. El resto de los pasos son similares a los pasos de ajuste fino de las instrucciones.
Establecimos max_input_length ser 2048 en g5.12xlarge. Puede utilizar una longitud de entrada mayor en un tipo de instancia más grande. Para más detalles, consulte el cuaderno de ejemplo.
Ejemplo de inferencia con y sin ajuste fino
La siguiente tabla contiene los resultados del modelo Mistral 7B ajustado con los documentos de presentación de Amazon ante la SEC de 2021 a 2022. Comparamos el resultado antes y después del ajuste fino.
| Solicitud de entrada | Salida antes del ajuste fino | Salida después del ajuste fino | Parámetros |
| Este informe del Formulario 10-K muestra que |
La empresa existe desde hace 10 años y cuenta con un total de 10 empleados. La empresa cuenta con un total de 10 empleados y se dedica a prestar servicios al público. La empresa cuenta con un total de 10 empleados y se dedica a prestar servicios al público. La empresa cuenta con un total de 10 empleados y se dedica a prestar servicios al público. La empresa cuenta con un total de 10 empleados y se dedica a prestar servicios al público. La empresa cuenta con un total de 10 empleados y se dedica a prestar servicios al público. La empresa tiene un total de 10 empleados y se dedica a proporcionar |
tuvimos ventas netas de $1.2 mil millones, $1.5 mil millones y $1.8 mil millones en 2004, 2003 y 2002. Estas cantidades incluyen las ventas de nuestros sitios web internacionales. Las ventas netas de nuestros sitios web internacionales fueron de $323 millones, $242 millones y $150 millones en 2004, 2003 y 2002. Las ventas netas de nuestros sitios web internacionales representaron el 27%, el 16% y el 8% de las ventas netas en 2004, 2003 y 2002. . | “temperatura”: 0,2, “max_new_tokens”: 150, |
| Servimos a los consumidores a través de |
nuestra red minorista de 1,700 tiendas, que incluye 1,200 tiendas en Estados Unidos, 400 tiendas en Canadá y 100 tiendas en México. También atendemos a los consumidores a través de nuestros sitios web de comercio electrónico. ## ¿Cuál es la tienda de mejoras para el hogar más grande? The Home Depot es el minorista de mejoras para el hogar más grande de Estados Unidos. ## ¿Cuál es la tienda de mejoras para el hogar más grande del mundo? La tienda de mejoras para el hogar más grande del mundo es Home Depot. ## ¿Cuál es la tienda de mejoras para el hogar más grande del mundo? |
nuestras tiendas físicas y en línea y nos centramos en la selección, el precio y la conveniencia. Diseñamos nuestras tiendas para permitir que nosotros y terceros vendamos cientos de millones de productos únicos en docenas de categorías de productos. Los clientes acceden a nuestras ofertas a través de nuestros sitios web, aplicaciones móviles, Alexa, dispositivos, streaming y visitando físicamente nuestras tiendas. También fabricamos y vendemos dispositivos electrónicos, incluidos Kindle, tableta Fire, Fire TV, Echo y Ring, y desarrollamos y producimos contenido multimedia. Buscamos ofrecer a nuestros clientes precios bajos, entrega rápida y gratuita, funcionalidad fácil de usar y servicio al cliente oportuno. Además, ofrecemos servicios de suscripción como Amazon Prime, un | |
| Nuestra visión es |
ser el proveedor líder de servicios de atención médica accesibles, asequibles y de calidad en las comunidades a las que servimos. Nuestra misión es brindar servicios de atención médica accesibles, asequibles y de calidad a las comunidades a las que servimos. Nuestros valores son: – Integridad: Actuamos con honestidad e integridad en todos nuestros tratos. Nuestro compromiso con nuestros pacientes es brindar servicios de atención médica de calidad, asequibles y accesibles. |
ser la empresa más centrada en el cliente del planeta. Nos guiamos por cuatro principios: obsesión por el cliente en lugar de enfoque en la competencia, pasión por la invención, compromiso con la excelencia operativa y pensamiento a largo plazo. En cada uno de nuestros segmentos, atendemos a nuestros principales conjuntos de clientes, compuestos por consumidores, vendedores, desarrolladores, empresas y creadores de contenido. Además, brindamos servicios, como publicidad. Hemos organizado nuestras operaciones en tres segmentos: Norteamérica, Internacional y AWS. Estos segmentos reflejan la forma en que la Compañía evalúa su desempeño comercial y administra sus operaciones. La información sobre nuestras ventas netas está contenida en el Punto 8 de la Parte II, “Estados Financieros |
Como puede ver, el modelo ajustado proporciona información más específica relacionada con Amazon en comparación con el modelo genérico previamente entrenado. Esto se debe a que el ajuste adapta el modelo para comprender los matices, patrones y detalles del conjunto de datos proporcionado. Al utilizar un modelo previamente entrenado y adaptarlo con ajustes, nos aseguramos de que obtenga lo mejor de ambos mundos: el amplio conocimiento del modelo previamente entrenado y la precisión especializada para su conjunto de datos único. Es posible que una talla única no sirva para todos en el mundo del aprendizaje automático, ¡y el ajuste fino es la solución hecha a medida que necesita!
Conclusión
En esta publicación, analizamos el ajuste del modelo Mistral 7B utilizando SageMaker JumpStart. Mostramos cómo puede utilizar la consola SageMaker JumpStart en SageMaker Studio o el SDK de SageMaker Python para ajustar e implementar estos modelos. Como siguiente paso, puede intentar ajustar estos modelos en su propio conjunto de datos utilizando el código proporcionado en el repositorio de GitHub para probar y comparar los resultados para sus casos de uso.
Sobre los autores
 Xin Huang es científico aplicado sénior de Amazon SageMaker JumpStart y los algoritmos integrados de Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable sobre datos tabulares y el análisis sólido de agrupaciones espacio-temporales no paramétricas. Ha publicado numerosos artículos en conferencias ACL, ICDM, KDD y Royal Statistical Society: Serie A.
Xin Huang es científico aplicado sénior de Amazon SageMaker JumpStart y los algoritmos integrados de Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable sobre datos tabulares y el análisis sólido de agrupaciones espacio-temporales no paramétricas. Ha publicado numerosos artículos en conferencias ACL, ICDM, KDD y Royal Statistical Society: Serie A.
 Vivek Gangasani es un arquitecto de soluciones de inicio de IA/ML para nuevas empresas de IA generativa en AWS. Ayuda a las nuevas empresas emergentes de GenAI a crear soluciones innovadoras utilizando los servicios de AWS y la computación acelerada. Actualmente, se centra en desarrollar estrategias para afinar y optimizar el rendimiento de inferencia de modelos de lenguaje grandes. En su tiempo libre, Vivek disfruta haciendo senderismo, viendo películas y probando diferentes platos.
Vivek Gangasani es un arquitecto de soluciones de inicio de IA/ML para nuevas empresas de IA generativa en AWS. Ayuda a las nuevas empresas emergentes de GenAI a crear soluciones innovadoras utilizando los servicios de AWS y la computación acelerada. Actualmente, se centra en desarrollar estrategias para afinar y optimizar el rendimiento de inferencia de modelos de lenguaje grandes. En su tiempo libre, Vivek disfruta haciendo senderismo, viendo películas y probando diferentes platos.
 Dr. Ashish Khaitan es un científico aplicado senior con algoritmos integrados de Amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado numerosos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
Dr. Ashish Khaitan es un científico aplicado senior con algoritmos integrados de Amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado numerosos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.






{kind=link}