
Large language models (LLMs) based on autoregressive transformer decoder architectures have advanced natural language processing with exceptional performance and scalability. Recently, diffusion models have gained attention for visual generation tasks, eclipsing autoregressive models (AMs). However, AMs show better scalability for large-scale applications and perform more efficiently with language models, making them better suited for unifying language and vision tasks. Recent advances in autoregressive visual generation (AVG) have shown promising results, matching or outperforming diffusion models in quality. Despite this, significant challenges still exist, especially in computational efficiency due to the high complexity of visual data and the quadratic computational demands of transformers.
Existing methods include vector quantization (VQ)-based models and state-space models (SSMs) to solve AVG challenges. VQ-based approaches, such as VQ-VAE, DALL-E, and VQGAN, compress images into discrete codes and use AM to predict these codes. SSMs, especially the Mamba family, have shown potential in handling long sequences with linear computational complexity. Recent adaptations of Mamba for visual tasks, such as ViM, VMamba, Zigma, and DiM, have explored multi-directional scanning strategies to capture 2D spatial information. However, these methods add additional parameters and computational costs, which decreases Mamba's speed advantage and increases GPU memory requirements.
Researchers from Beijing University of Posts and Telecommunications, the University of the Chinese Academy of Sciences, the Hong Kong Polytechnic University and the Institute of Automation of the Chinese Academy of Sciences have proposed AiM, a new TOautoregressive YoWizard generation model based on the METROAmba framework. It is developed for efficient and high-quality class-conditional image generation, making it the first model of its kind. Aim uses positional encoding, providing a new and more generalized adaptive layer normalization method called adaLN-Group, which optimizes the trade-off between performance and parameter count. Furthermore, AiM has demonstrated state-of-the-art performance among AMs on the ImageNet 256×256 benchmark while achieving fast inference speeds.
AiM was developed at four scales and evaluated on the ImageNet1K benchmark to assess its architectural design, performance, scalability, and inference efficiency. It uses an image tokenizer with a subsampling factor of 16, initialized with pre-trained weights from LlamaGen. Each 256×256 image is tokenized into 256 tokens. Training was performed on 80GB A100 GPU using the AdamW optimizer with specific hyperparameters. Training epochs vary between 300 and 350 depending on the model scale, and a dropout rate of 0.1 was applied to class embeddings for classifier-free guidance. Evaluation metrics used Frechet inception distance (FID) as the primary metric to evaluate model performance on image generation tasks.
AiM showed significant performance improvements as model size and training duration increased, with a strong correlation coefficient of -0.9838 between FID scores and model parameters. This demonstrates the scalability of AiM and the effectiveness of larger models in improving image generation quality. It achieved state-of-the-art performance among AMs such as GANs, diffusion models, masked generative models, and Transformer-based AMs. Furthermore, AiM has a clear advantage in inference speed compared to other models, and Transformer-based models benefit from Flash-Attention and KV Cache optimizations.
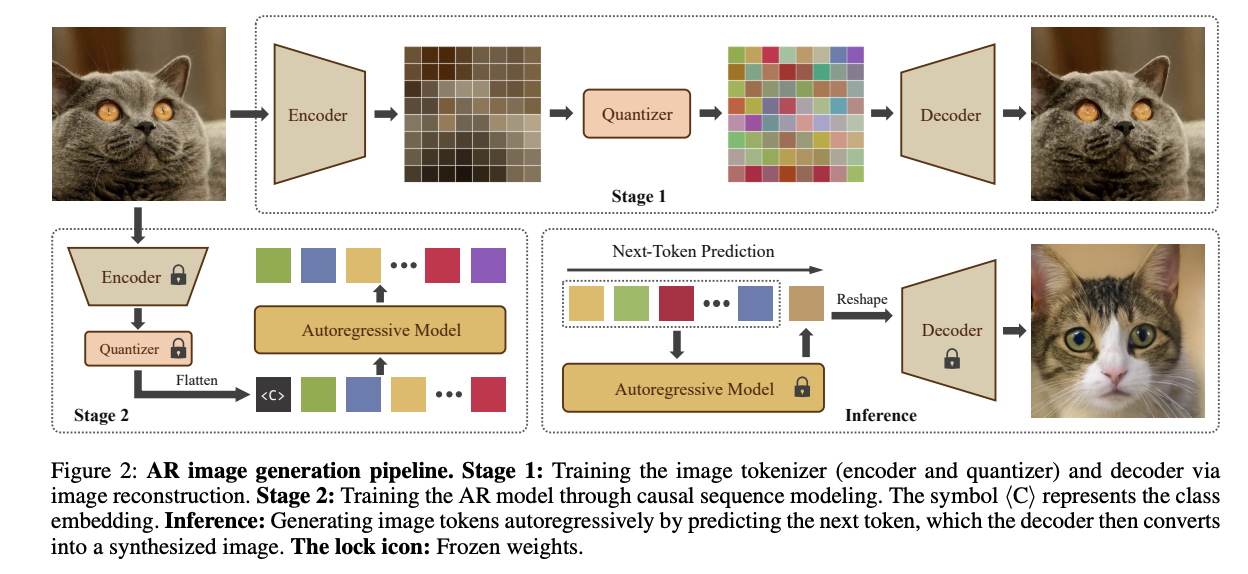
In conclusion, the researchers have presented Aim, a new autoregressive image generation model based on the Mamba framework. This paper explores the potential of Mamba in visual tasks, successfully adapting it to visual generation without requiring additional multi-directional scans. The effectiveness and efficiency of AiM highlight its scalability and wide applicability in autoregressive visual modeling. However, it focuses only on conditional class generation, without exploring text-to-image generation, which provides directions for future research for further advancements in the field of visual generation using state-space models like Mamba.
Take a look at the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Below is a highly recommended webinar from our sponsor: ai/webinar-nvidia-nims-and-haystack?utm_campaign=2409-campaign-nvidia-nims-and-haystack-&utm_source=marktechpost&utm_medium=banner-ad-desktop” target=”_blank” rel=”noreferrer noopener”>'Developing High-Performance ai Applications with NVIDIA NIM and Haystack'

Sajjad Ansari is a final year student from IIT Kharagpur. As a technology enthusiast, he delves into practical applications of ai, focusing on understanding the impact of ai technologies and their real-world implications. He aims to articulate complex ai concepts in a clear and accessible manner.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}