
Ensuring the safety of increasingly powerful ai systems is a critical concern. Current ai safety research aims to address emerging and future risks by developing benchmarks that measure various safety properties, such as fairness, reliability, and robustness. However, the field remains ill-defined, with benchmarks often reflecting general ai capabilities rather than genuine safety improvements. This ambiguity can lead to “safety whitewashing,” where advances in capabilities are misrepresented as safety advances, which fails to ensure that ai systems are actually safer. Addressing this challenge is essential to advancing ai research and ensuring that safety measures are meaningful and effective.
Existing methods for ensuring ai safety involve benchmarks designed to assess attributes such as fairness, reliability, and robustness against adversaries. Common benchmarks include tests of model alignment with human preferences, bias assessments, and calibration metrics. However, these benchmarks have significant limitations. Many are highly correlated with general ai capabilities, meaning that improvements in these benchmarks are often the result of general performance improvements rather than specific safety improvements. This confusion leads to improvements in capabilities being misrepresented as advances in safety, which does not ensure that ai systems are actually safer.
A team of researchers from the Center for ai Safety, the University of Pennsylvania, the University of California at Berkeley, Stanford University, Yale University, and Keio University introduces a novel empirical approach to distinguish true safety progress from general capability improvements. The researchers perform a meta-analysis of several ai safety benchmarks and measure their correlation with general capabilities across numerous models. This analysis reveals that many safety benchmarks are in fact correlated with general capabilities, leading to potential safety whitewashing. The innovation lies in the empirical basis for developing more meaningful safety metrics that are distinguishable from generic capability advances. By defining ai safety in a machine learning context as a set of clearly separable research goals, the researchers aim to create a rigorous framework that truly measures safety progress, thereby advancing the science of safety assessments.
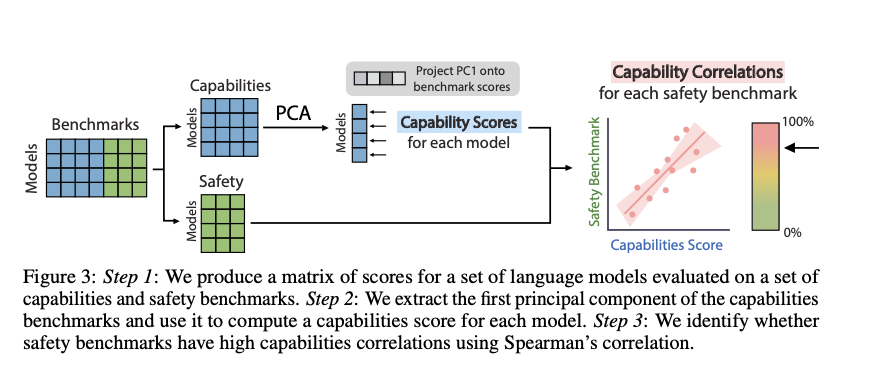
The methodology involves collecting performance scores from multiple models on numerous security and capability parameters. The scores are normalized and analyzed using principal component analysis (PCA) to obtain an overall capabilities score. The correlation between this capabilities score and the security parameter scores is then calculated using Spearman correlation. This approach allows identifying which parameters measure security properties independently of overall capabilities and which do not. Researchers use a diverse set of models and parameters to ensure robust results, including task-specific tuned models and general models, as well as parameters for alignment, bias, adversarial robustness, and calibration.
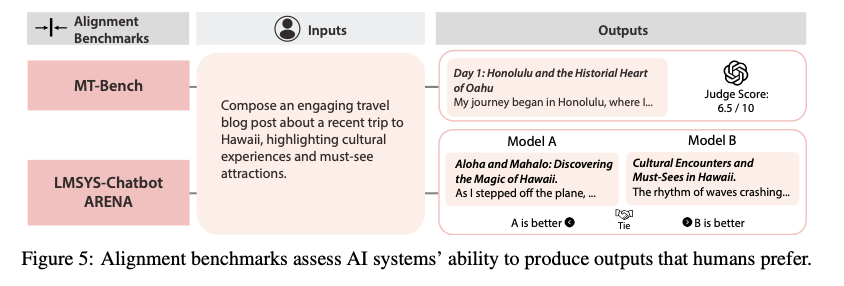
The results of this study reveal that many ai safety benchmarks are highly correlated with general capabilities, indicating that improvements in these benchmarks often arise from general performance improvements rather than specific safety advances. For example, the MT-Bench alignment benchmark shows a capability correlation of 78.7%, suggesting that higher alignment scores are primarily due to the general capabilities of the model. In contrast, the MACHIAVELLI benchmark for ethical propensities shows a low correlation with general capabilities, demonstrating its effectiveness in measuring different safety attributes. This distinction is crucial as it highlights the risk of whitewashing, where improvements in ai safety benchmarks can be misinterpreted as genuine safety progress when they are simply reflections of general capability improvements. Emphasizing the need for benchmarks that independently measure safety properties ensures that ai safety advances are meaningful and not simply superficial improvements.

In conclusion, the researchers provide empirical clarity on measuring ai safety. By showing that many current benchmarks are highly correlated with general capabilities, they highlight the need to develop benchmarks that truly measure safety improvements. The proposed solution involves creating a set of empirically separable safety research objectives, ensuring that advances in ai safety are not mere reflections of general capability improvements, but genuine improvements in ai reliability and trustworthiness. This work has the potential to significantly influence ai safety research by providing a more rigorous framework for assessing safety progress.
Review the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our Newsletter..
Don't forget to join our Over 47,000 ML subscribers on Reddit
Find upcoming ai webinars here
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from Indian Institute of technology, Kharagpur. He is passionate about Data Science and Machine Learning and has a strong academic background and hands-on experience in solving real-world interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}