 NEWSLETTER
NEWSLETTER
Amazon SageMaker multi-model endpoints (MMEs) provide a scalable and cost-effective way to deploy a large number of machine learning (ML) models. It gives you the ability to deploy multiple ML models in a single serving container behind a single endpoint. From there, SageMaker manages loading and unloading the models and scaling resources on your behalf based on your traffic patterns. You will benefit from sharing and reusing hosting resources and a reduced operational burden of managing a large quantity of models.
In November 2022, MMEs added support for GPUs, which allows you to run multiple models on a single GPU device and scale GPU instances behind a single endpoint. This satisfies the strong MME demand for deep neural network (DNN) models that benefit from accelerated compute with GPUs. These include computer vision (CV), natural language processing (NLP), and generative AI models. The reasons for the demand include the following:
- DNN models are typically large in size and complexity and continue growing at a rapid pace. Taking NLP models as an example, many of them exceed billions of parameters, which requires GPUs to satisfy low latency and high throughput requirements.
- We have observed an increased need for customizing these models to deliver hyper-personalized experiences to individual users. As the quantity of these models increases, there is a need for an easier solution to deploy and operationalize many models at scale.
- GPU instances are expensive and you want to reuse these instances as much as possible to maximize the GPU utilization and reduce operating cost.
Although all these reasons point to MMEs with GPU as an ideal option for DNN models, it’s advised to perform load testing to find the right endpoint configuration that satisfies your use case requirements. Many factors can influence the load testing results, such as instance type, number of instances, model size, and model architecture. In addition, load testing can help guide the auto scaling strategies using the right metrics rather than iterative trial and error methods.
For those reasons, we put together this post to help you perform proper load testing on MMEs with GPU and find the best configuration for your ML use case. We share our load testing results for some of the most popular DNN models in NLP and CV hosted using MMEs on different instance types. We summarize the insights and conclusion from our test results to help you make an informed decision on configuring your own deployments. Along the way, we also share our recommended approach to performing load testing for MMEs on GPU. The tools and technique recommended determine the optimum number of models that can be loaded per instance type and help you achieve the best price-performance.
Solution overview
For an introduction to MMEs and MMEs with GPU, refer to Create a Multi-Model Endpoint and Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints. For the context of load testing in this post, you can download our sample code from the GitHub repo to reproduce the results or use it as a template to benchmark your own models. There are two notebooks provided in the repo: one for load testing CV models and another for NLP. Several models of varying sizes and architectures were benchmarked on different type of GPU instances: ml.g4dn.2xlarge, ml.g5.2xlarge, and ml.p3.2xlarge. This should provide a reasonable cross section of performance across the following metrics for each instance and model type:
- Max number of models that can be loaded into GPU memory
- End-to-end response latency observed on the client side for each inference query
- Max throughput of queries per second that the endpoint can process without error
- Max current users per instances before a failed request is observed
The following table lists the models tested.
| Use Case | Model Name | Size On Disk | Number of Parameters |
| CV | resnet50 |
100Mb | 25M |
| CV | convnext_base |
352Mb | 88M |
| CV | vit_large_patch16_224 |
1.2Gb | 304M |
| NLP | bert-base-uncased |
436Mb | 109M |
| NLP | roberta-large |
1.3Gb | 335M |
The following table lists the GPU instances tested.
| Instance Type | GPU Type | Num of GPUs | GPU Memory (GiB) |
| ml.g4dn.2xlarge | NVIDIA T4 GPUs | 1 | 16 |
| ml.g5.2xlarge | NVIDIA A10G Tensor Core GPU | 1 | 24 |
| ml.p3.2xlarge | NVIDIA® V100 Tensor Core GPU | 1 | 16 |
As previously mentioned, the code example can be adopted to other models and instance types.
Note that MMEs currently only support single GPU instances. For the list of supported instance types, refer to Supported algorithms, frameworks, and instances.
The benchmarking procedure is comprised of the following steps:
- Retrieve a pre-trained model from a model hub.
- Prepare the model artifact for serving on SageMaker MMEs (see Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints for more details).
- Deploy a SageMaker MME on a GPU instance.
- Determine the maximum number of models that can be loaded into the GPU memory within a specified threshold.
- Use the Locust Load Testing Framework to simulate traffic that randomly invokes models loaded on the instance.
- Collect data and analyze the results.
- Optionally, repeat Steps 2–6 after compiling the model to TensorRT.
Steps 4 and 5 warrant a deeper look. Models within a SageMaker GPU MME are loaded into memory in a dynamic fashion. Therefore, in Step 4, we upload an initial model artifact to Amazon Simple Storage Service (Amazon S3) and invoke the model to load it into memory. After the initial invocation, we measure the amount of GPU memory consumed, make a copy of the initial model, invoke the copy of the model to load it into memory, and again measure the total amount of GPU memory consumed. This process is repeated until a specified percent threshold of GPU memory utilization is reached. For the benchmark, we set the threshold to 90% to provide a reasonable memory buffer for inferencing on larger batches or leaving some space to load other less-frequently used models.
Simulate user traffic
After we have determined the number of models, we can run a load test using the Locust Load Testing Framework. The load test simulates user requests to random models and automatically measures metrics such as response latency and throughput.
Locust supports custom load test shapes that allow you to define custom traffic patterns. The shape that was used in this benchmark is shown in the following chart. In the first 30 seconds, the endpoint is warmed up with 10 concurrent users. After 30 seconds, new users are spawned at a rate of two per second, reaching 20 concurrent users at the 40-second mark. The endpoint is then benchmarked steadily with 20 concurrent users until the 60-second mark, at which point Locust again begins to ramp up users at two per second until 40 concurrent users. This pattern of ramping up and steady testing is repeated until the endpoint is ramped up to 200 concurrent users. Depending on your use case, you may want to adjust the load test shape in the locust_benchmark_sm.py to more accurately reflect your expected traffic patterns. For example, if you intend to host larger language models, a load test with 200 concurrent users may not be feasible for a model hosted on a single instance, and you may therefore want to reduce the user count or increase the number of instances. You may also want to extend the duration of the load test to more accurately gauge the endpoint’s stability over a longer period of time.
stages = [
{"duration": 30, "users": 10, "spawn_rate": 5},
{"duration": 60, "users": 20, "spawn_rate": 1},
{"duration": 90, "users": 40, "spawn_rate": 2},
…
]Note that we have only benchmarked the endpoint with homogeneous models all running on a consistent serving bases using either PyTorch or TensorRT. This is because MMEs are best suited for hosting many models with similar characteristics, such as memory consumption and response time. The benchmarking templates provided in the GitHub repo can still be used to determine whether serving heterogeneous models on MMEs would yield the desired performance and stability.
Benchmark results for CV models
Use the cv-benchmark.ipynb notebook to run load testing for computer vision models. You can adjust the pre-trained model name and instance type parameters to performance load testing on different model and instance type combinations. We purposely tested three CV models in different size ranges from smallest to largest: resnet50 (25M), convnext_base (88M), and vit_large_patch16_224 (304M). You may need to adjust to code if you pick a model outside of this list. additionally, the notebook defaults the input image shape to a 224x224x3 image tensor. Remember to adjust the input shape accordingly if you need to benchmark models that take a different-sized image.
After running through the entire notebook, you will get several performance analysis visualizations. The first two detail the model performance with respect to increasing concurrent users. The following figures are the example visualizations generated for the ResNet50 model running on ml.g4dn.2xlarge, comparing PyTorch (left) vs. TensorRT (right). The top line graphs show the model latency and throughput on the y-axis with increasing numbers of concurrent client workers reflected on the x-axis. The bottom bar charts show the count of successful and failed requests.
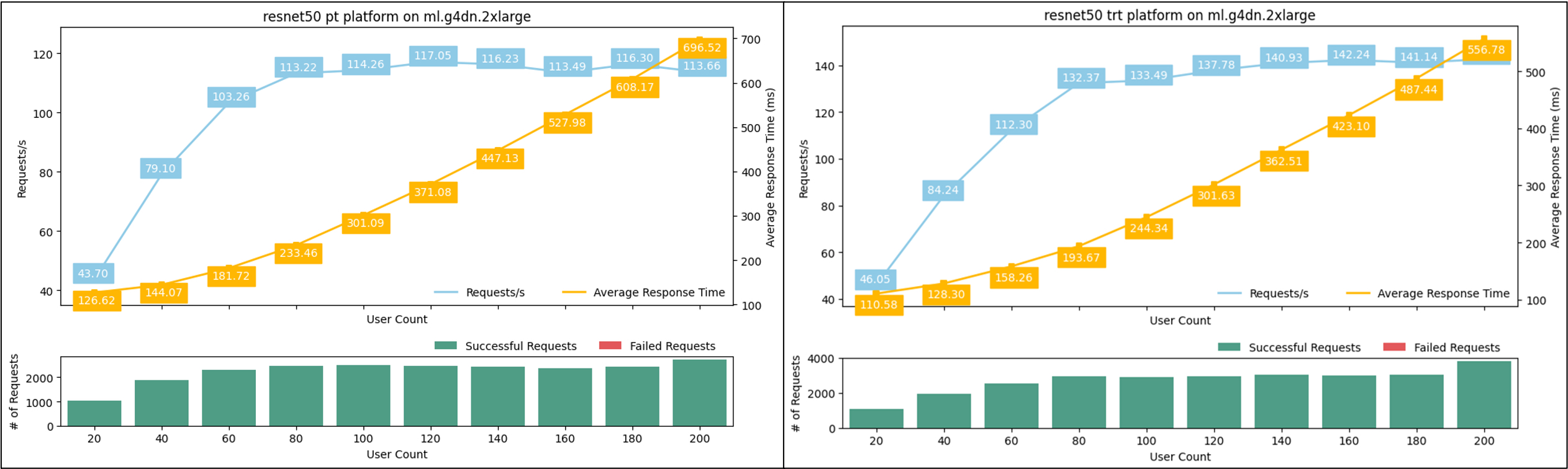
Looking across all the computer vision models we tested, we observed the following:
- Latency (in milliseconds) is higher, and throughput (requests per second) is lower for bigger models (
resnet50 > convnext_base > vit_large_patch16_224). - Latency increase is proportional with the number of users as more requests are queued up on the inference server.
- Large models consume more compute resources and can reach their maximum throughput limits with fewer users than a smaller model. This is observed with the
vit_large_patch16_224model, which recorded the first failed request at 140 concurrent users. Being significantly larger than the other two models tested, it had the most overall failed requests at higher concurrency as well. This is a clear signal that the endpoint would need to scale beyond a single instance if the intent is to support more than 140 concurrent users.
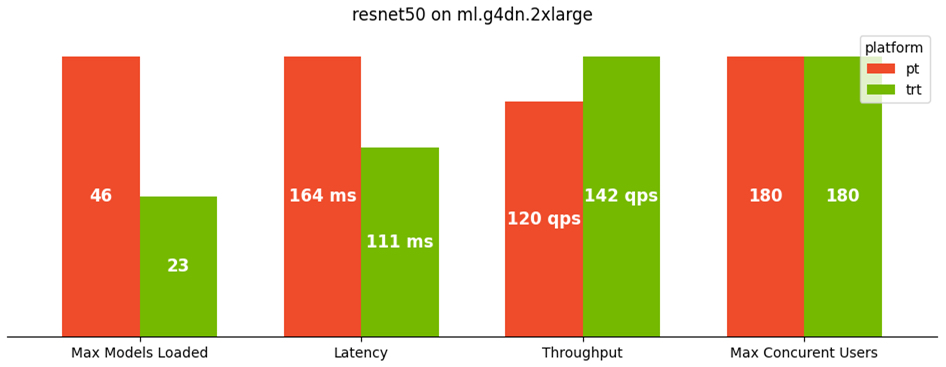
At the end of the notebook run, you also get a summary comparison of PyTorch vs. TensorRT models for each of the four key metrics. From our benchmark testing, the CV models all saw a boost in model performance after TensorRT compilation. Taking our ResNet50 model as the example again, latency decreased by 32% while throughput increased by 18%. Although the maximum number of concurrent users stayed the same for ResNet50, the other two models both saw a 14% improvement in the number of concurrent users that they can support. The TensorRT performance improvement, however, came at the expense of higher memory utilization, resulting in fewer models loaded by MMEs. The impact is more for models using a convolutional neural network (CNN). In fact, our ResNet50 model consumed approximately twice the GPU memory going from PyTorch to TensorRT, resulting in 50% fewer models loaded (46 vs. 23). We diagnose this behavior further in the following section.
Benchmark results for NLP models
For the NLP models, use the nlp-benchmark.ipynb notebook to run the load test. The setup of the notebook should look very similar. We tested two NLP models: bert-base-uncased (109M) and roberta-large (335M). The pre-trained model and the tokenizer are both downloaded from the Hugging Face hub, and the test payload is generated from the tokenizer using a sample string. Max sequence length is defaulted at 128. If you need to test longer strings, remember to adjust that parameter. Running through the NLP notebook generates the same set of visualizations: Pytorch (left) vs TensorRT (right).
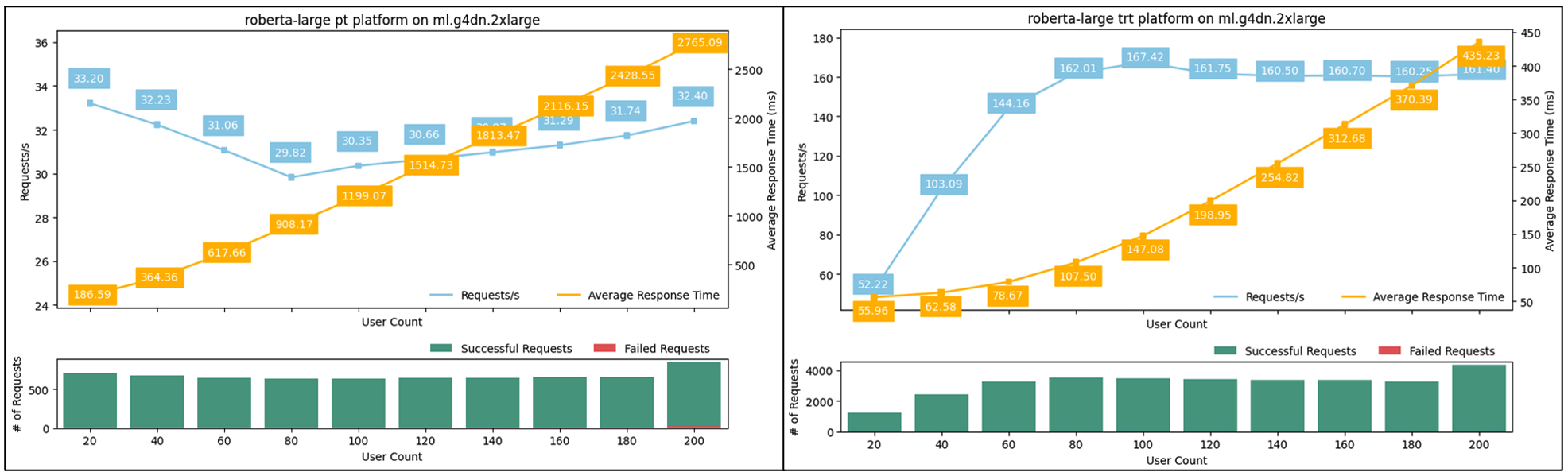
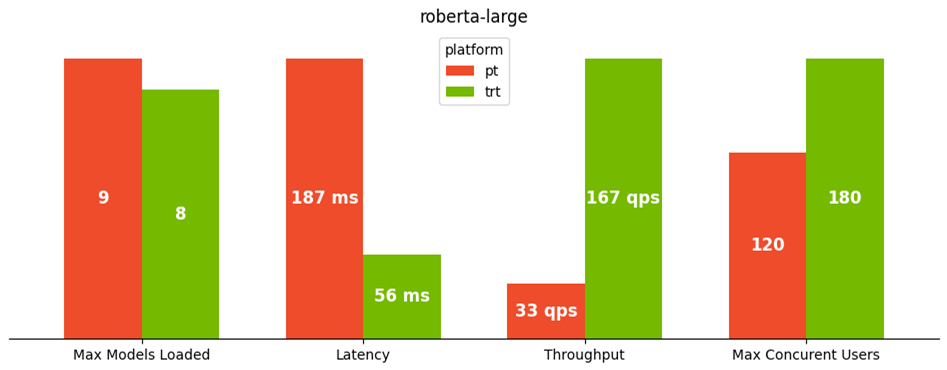
From these, we observed even more performance benefit of TensorRT for NLP models. Taking the roberta-large model on an ml.g4dn.2xlarge instance for example, inference latency decreased dramatically from 180 milliseconds to 56 milliseconds (a 70% improvement), while throughput improved by 406% from 33 requests per second to 167. Additionally, the maximum number of concurrent users increased by 50%; failed requests were not observed until we reached 180 concurrent users, compared to 120 for the original PyTorch model. In terms of memory utilization, we saw one fewer model loaded for TensorRT (from nine models to eight). However, the negative impact is much smaller compared to what we observed with the CNN-based models.
Analysis on memory utilization
The following table shows the full analysis on memory utilization impact going from PyTorch to TensorRT. We mentioned earlier that CNN-based models are impacted more negatively. The ResNet50 model had an over 50% reduction in number of models loaded across all three GPU instance types. Convnext_base had an even larger reduction at approximately 70% across the board. On the other hand, the impact to the transformer models is small or mixed. vit_large_patch16_224 and roberta-large had an average reduction of approximately 20% and 3%, respectively, while bert-base-uncased had an approximately 40% improvement.
Looking at all the data points as a whole in regards to the superior performance in latency, throughput, and reliability, and the minor impact on the maximum number of models loaded, we recommend the TensorRT model for transformer-based model architectures. For CNNs, we believe further cost performance analysis is needed to make sure the performance benefit outweighs the cost of additional hosting infrastructure.
| ML Use Case | Architecture | Model Name | Instance Type | Framework | Max Models Loaded | Diff (%) | Avg. Diff (%) |
| CV | CNN | Resnet50 |
ml.g4dn.2xlarge | PyTorch | 46 | -50% | -50% |
| TensorRT | 23 | ||||||
| ml.g5.2xlarge | PyTorch | 70 | -51% | ||||
| TensorRT | 34 | ||||||
| ml.p3.2xlarge | PyTorch | 49 | -51% | ||||
| TensorRT | 24 | ||||||
Convnext_base |
ml.g4dn.2xlarge | PyTorch | 33 | -50% | -70% | ||
| TensorRT | 10 | ||||||
| ml.g5.2xlarge | PyTorch | 50 | -70% | ||||
| TensorRT | 16 | ||||||
| ml.p3.2xlarge | PyTorch | 35 | -69% | ||||
| TensorRT | 11 | ||||||
| Transformer | vit_large_patch16_224 |
ml.g4dn.2xlarge | PyTorch | 10 | -30% | -20% | |
| TensorRT | 7 | ||||||
| ml.g5.2xlarge | PyTorch | 15 | -13% | ||||
| TensorRT | 13 | ||||||
| ml.p3.2xlarge | PyTorch | 11 | -18% | ||||
| TensorRT | 9 | ||||||
| NLP | Roberta-large |
ml.g4dn.2xlarge | PyTorch | 9 | -11% | -3% | |
| TensorRT | 8 | ||||||
| ml.g5.2xlarge | PyTorch | 13 | 0% | ||||
| TensorRT | 13 | ||||||
| ml.p3.2xlarge | PyTorch | 9 | 0% | ||||
| TensorRT | 9 | ||||||
Bert-base-uncased |
ml.g4dn.2xlarge | PyTorch | 26 | 62% | 40% | ||
| TensorRT | 42 | ||||||
| ml.g5.2xlarge | PyTorch | 39 | 28% | ||||
| TensorRT | 50 | ||||||
| ml.p3.2xlarge | PyTorch | 28 | 29% | ||||
| TensorRT | 36 |
The following tables list our complete benchmark results for all the metrics across all three GPU instances types.
|
ml.g4dn.2xlarge |
||||||||||||
| Use Case | Architecture | Model Name | Number of Parameters | Framework | Max Models Loaded | Diff (%) | Latency (ms) | Diff (%) | Throughput (qps) | Diff (%) | Max Concurrent Users | Diff (%) |
| CV | CNN | resnet50 |
25M | PyTorch | 46 | -50% | 164 | -32% | 120 | 18% | 180 | NA |
| TensorRT | 23 | . | 111 | . | 142 | . | 180 | . | ||||
convnext_base |
88M | PyTorch | 33 | -70% | 154 | -22% | 64 | 102% | 140 | 14% | ||
| TensorRT | 10 | . | 120 | . | 129 | . | 160 | . | ||||
| Transformer | vit_large_patch16_224 |
304M | PyTorch | 10 | -30% | 425 | -69% | 26 | 304% | 140 | 14% | |
| TensorRT | 7 | . | 131 | . | 105 | . | 160 | . | ||||
| NLP | bert-base-uncased |
109M | PyTorch | 26 | 62% | 70 | -39% | 105 | 142% | 140 | 29% | |
| TensorRT | 42 | . | 43 | . | 254 | . | 180 | . | ||||
roberta-large |
335M | PyTorch | 9 | -11% | 187 | -70% | 33 | 406% | 120 | 50% | ||
| TensorRT | 8 | . | 56 | . | 167 | . | 180 | . | ||||
|
ml.g5.2xlarge |
||||||||||||
| Use Case | Architecture | Model Name | Number of Parameters | Framework | Max Models Loaded | Diff (%) | Latency (ms) | Diff (%) | Throughput (qps) | Diff (%) | Max Concurrent Users | Diff (%) |
| CV | CNN | resnet50 |
25M | PyTorch | 70 | -51% | 159 | -31% | 146 | 14% | 180 | 11% |
| TensorRT | 34 | . | 110 | . | 166 | . | 200 | . | ||||
convnext_base |
88M | PyTorch | 50 | -68% | 149 | -23% | 134 | 13% | 180 | 0% | ||
| TensorRT | 16 | . | 115 | . | 152 | . | 180 | . | ||||
| Transformer | vit_large_patch16_224 |
304M | PyTorch | 15 | -13% | 149 | -22% | 105 | 35% | 160 | 25% | |
| TensorRT | 13 | . | 116 | . | 142 | . | 200 | . | ||||
| NLP | bert-base-uncased |
109M | PyTorch | 39 | 28% | 65 | -29% | 183 | 38% | 180 | 11% | |
| TensorRT | 50 | . | 46 | . | 253 | . | 200 | . | ||||
roberta-large |
335M | PyTorch | 13 | 0% | 97 | -38% | 121 | 46% | 140 | 14% | ||
| TensorRT | 13 | . | 60 | . | 177 | . | 160 | . | ||||
|
ml.p3.2xlarge |
||||||||||||
| Use Case | Architecture | Model Name | Number of Parameters | Framework | Max Models Loaded | Diff (%) | Latency (ms) | Diff (%) | Throughput (qps) | Diff (%) | Max Concurrent Users | Diff (%) |
| CV | CNN | resnet50 |
25M | PyTorch | 49 | -51% | 197 | -41% | 94 | 18% | 160 | -12% |
| TensorRT | 24 | . | 117 | . | 111 | . | 140 | . | ||||
convnext_base |
88M | PyTorch | 35 | -69% | 178 | -23% | 89 | 11% | 140 | 14% | ||
| TensorRT | 11 | .137 | 137 | . | 99 | . | 160 | . | ||||
| Transformer | vit_large_patch16_224 |
304M | PyTorch | 11 | -18% | 186 | -28% | 83 | 23% | 140 | 29% | |
| TensorRT | 9 | . | 134 | . | 102 | . | 180 | . | ||||
| NLP | bert-base-uncased |
109M | PyTorch | 28 | 29% | 77 | -40% | 133 | 59% | 140 | 43% | |
| TensorRT | 36 | . | 46 | . | 212 | . | 200 | . | ||||
roberta-large |
335M | PyTorch | 9 | 0% | 108 | -44% | 88 | 60% | 160 | 0% | ||
| TensorRT | 9 | . | 61 | . | 141 | . | 160 | . | ||||
The following table summarizes the results across all instance types. The ml.g5.2xlarge instance provides the best performance, whereas the ml.p3.2xlarge instance generally underperforms despite being the most expensive of the three. The g5 and g4dn instances demonstrate the best value for inference workloads.
| Use Case | Architecture | Model Name | Number of Parameters | Framework | Instance Type | Max Models Loaded | Diff (%) | Latency (ms) | Diff (%) | Throughput (qps) | Diff (%) | Max Concurrent Users |
| CV | CNN | resnet50 |
25M | PyTorch | ml.g5.2xlarge | 70 | . | 159 | . | 146 | . | 180 |
| . | . | . | . | . | ml.p3.2xlarge | 49 | . | 197 | . | 94 | . | 160 |
| . | . | . | . | . | ml.g4dn.2xlarge | 46 | . | 164 | . | 120 | . | 180 |
| CV | CN | resnet50 |
25M | TensorRT | ml.g5.2xlarge | 34 | -51% | 110 | -31% | 166 | 14% | 200 |
| . | . | . | . | . | ml.p3.2xlarge | 24 | -51% | 117 | -41% | 111 | 18% | 200 |
| . | . | . | . | . | ml.g4dn.2xlarge | 23 | -50% | 111 | -32% | 142 | 18% | 180 |
| NLP | Transformer | bert-base-uncased |
109M | Pytorch | ml.g5.2xlarge | 39 | . | 65 | . | 183 | . | 180 |
| . | . | . | . | . | ml.p3.2xlarge | 28 | . | 77 | . | 133 | . | 140 |
| . | . | . | . | . | ml.g4dn.2xlarge | 26 | . | 70 | . | 105 | . | 140 |
| NLP | Transformer | bert-base-uncased |
109M | TensorRT | ml.g5.2xlarge | 50 | 28% | 46 | -29% | 253 | 38% | 200 |
| . | . | . | . | . | ml.p3.2xlarge | 36 | 29% | 46 | -40% | 212 | 59% | 200 |
| . | . | . | . | . | ml.g4dn.2xlarge | 42 | 62% | 43 | -39% | 254 | 142% | 180 |
Clean up
After you complete your load test, clean up the generated resources to avoid incurring additional charges. The main resources are the SageMaker endpoints and model artifact files in Amazon S3. To make it easy for you, the notebook files have the following cleanup code to help you delete them:
Conclusion
In this post, we shared our test results and analysis for various deep neural network models running on SageMaker multi-model endpoints with GPU. The results and insights we shared should provide a reasonable cross section of performance across different metrics and instance types. In the process, we also introduced our recommended approach to run benchmark testing for SageMaker MMEs with GPU. The tools and sample code we provided can help you quickstart your benchmark testing and make a more informed decision on how to cost-effectively host hundreds of DNN models on accelerated compute hardware. To get started with benchmarking your own models with MME support for GPU, refer to Supported algorithms, frameworks, and instances and the GitHub repo for additional examples and documentation.
About the authors
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.






{kind=link}