 NEWSLETTER
NEWSLETTER
amazon SageMaker Ground Truth permite la creación de conjuntos de datos de entrenamiento a gran escala y de alta calidad, esenciales para realizar ajustes en una amplia gama de aplicaciones, incluidos modelos de lenguaje de gran tamaño (LLM) e IA generativa. Al integrar anotadores humanos con el aprendizaje automático, SageMaker Ground Truth reduce significativamente el costo y el tiempo necesarios para el etiquetado de datos. Ya sea anotando imágenes, videos o texto, SageMaker Ground Truth le permite crear conjuntos de datos precisos mientras mantiene la supervisión humana y la retroalimentación a escala. Este enfoque humano-in-the-loop es crucial para alinear los modelos básicos con las preferencias humanas, mejorando su capacidad para realizar tareas adaptadas a sus requisitos específicos.
Para satisfacer diversas necesidades de etiquetado, SageMaker Ground Truth proporciona flujos de trabajo integrados para tareas comunes como clasificación de imágenes, detección de objetos y segmentación semántica. Además, ofrece la flexibilidad de crear flujos de trabajo personalizados, lo que le permite diseñar sus propias plantillas de interfaz de usuario para tareas de etiquetado de datos especializadas, adaptadas a sus requisitos únicos.
Anteriormente, configurar un trabajo de etiquetado personalizado requería especificar dos funciones de AWS Lambda: una función de anotación previa, que se ejecuta en cada objeto del conjunto de datos antes de enviarse a los trabajadores, y una función de anotación posterior, que se ejecuta en las anotaciones de cada conjunto de datos. objeto y consolida múltiples anotaciones de trabajadores si es necesario. Aunque estas funciones ofrecen valiosas capacidades de personalización, también añaden complejidad para los usuarios que no requieren manipulación de datos adicional. En estos casos, tendría que escribir funciones que simplemente devolvieran su entrada sin cambios, lo que aumenta el esfuerzo de desarrollo y la posibilidad de errores al integrar las funciones Lambda con la plantilla de interfaz de usuario y el archivo de manifiesto de entrada.
Hoy, nos complace anunciar que ya no es necesario proporcionar funciones Lambda previas y posteriores a la anotación al crear trabajos de etiquetado personalizados de SageMaker Ground Truth. Estas funciones ahora son opcionales tanto en la consola de SageMaker como en la API CreateLabelingJob. Esto significa que puede crear flujos de trabajo de etiquetado personalizados de manera más eficiente cuando no requiere procesamiento de datos adicional.
En esta publicación, le mostramos cómo configurar un trabajo de etiquetado personalizado sin funciones Lambda usando SageMaker Ground Truth. Lo guiamos a través de la configuración del flujo de trabajo utilizando una plantilla de evaluación de contenido multimodal, explicamos cómo funciona sin funciones Lambda y destacamos los beneficios de esta nueva capacidad.
Descripción general de la solución
Cuando omite las funciones Lambda en un trabajo de etiquetado personalizado, el flujo de trabajo se simplifica:
- Sin función de preanotación – Los datos del archivo de manifiesto de entrada se insertan directamente en la plantilla de interfaz de usuario. Puede hacer referencia a los campos de objetos de datos en su plantilla sin necesidad de una función Lambda para asignarlos.
- Sin función de anotación posterior – La anotación de cada trabajador se guarda directamente en su depósito de amazon Simple Storage Service (amazon S3) especificado como un archivo JSON individual, y la anotación se almacena bajo una clave de respuesta del trabajador. Sin una función Lambda posterior a la anotación, el archivo de manifiesto de salida hace referencia a estos archivos de respuesta del trabajador en lugar de incluir todas las anotaciones directamente dentro del manifiesto.
En las siguientes secciones, explicamos cómo configurar un trabajo de etiquetado personalizado sin funciones Lambda usando un amazon-sagemaker-ground-truth-task-uis/blob/master/gen-ai/multi-modal-content-evaluation.liquid.html” target=”_blank” rel=”noopener”>plantilla de evaluación de contenido multimodalque le permite evaluar descripciones de imágenes generadas por modelos. Los anotadores pueden revisar una imagen, una indicación y la respuesta del modelo, y luego evaluar la respuesta en función de criterios como precisión, relevancia y claridad. Esto proporciona retroalimentación humana crucial para ajustar modelos utilizando el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) o la evaluación de LLM.
Prepare el archivo de manifiesto de entrada
Para configurar nuestro trabajo de etiquetado, comenzamos preparando el archivo de manifiesto de entrada que utilizará la plantilla. El manifiesto de entrada es un archivo de líneas JSON donde cada línea representa un elemento del conjunto de datos que se va a etiquetar. Cada línea contiene una source campo para datos incrustados o un source-ref campo para referencias a datos almacenados en amazon S3. Estos campos se utilizan para proporcionar los objetos de datos que etiquetarán los anotadores. Para obtener información detallada sobre la estructura del archivo de manifiesto de entrada, consulte Archivos de manifiesto de entrada.
Para nuestra tarea específica (evaluar descripciones de imágenes generadas por modelos), estructuramos el manifiesto de entrada para incluir los siguientes campos:
- “fuente” – El mensaje proporcionado al modelo.
- “imagen” – El URI de S3 de la imagen asociada con el mensaje
- “respuestamodelo” – La descripción de la imagen generada por el modelo.
Al incluir estos campos, podemos presentar tanto el mensaje como los datos relacionados directamente a los anotadores dentro de la plantilla de interfaz de usuario. Este enfoque elimina la necesidad de una función Lambda previa a la anotación porque se puede acceder fácilmente a toda la información necesaria en el archivo de manifiesto.
El siguiente código es un ejemplo de cómo se vería una línea en nuestro manifiesto de entrada:
Inserte el mensaje en la plantilla de UI
En su plantilla de interfaz de usuario, puede insertar el mensaje usando {{ task.input.source }}muestre la imagen usando un src="https://aws.amazon.com/blogs/machine-learning/accelerate-custom-labeling-workflows-in-amazon-sagemaker-ground-truth-without-using-aws-lambda/{{ task.input.image" grant_read_access }}" (el filtro Grant_read_access Liquid proporciona al trabajador acceso al objeto S3) y muestra la respuesta del modelo con {{ task.input.modelResponse }}. Luego, los anotadores pueden evaluar la respuesta del modelo basándose en criterios predefinidos, como precisión, relevancia y claridad, utilizando herramientas como controles deslizantes o campos de entrada de texto para comentarios adicionales. Puede encontrar la plantilla de interfaz de usuario completa para esta tarea en nuestro amazon-sagemaker-ground-truth-task-uis/blob/master/gen-ai/multi-modal-content-evaluation.liquid.html” target=”_blank” rel=”noopener”>repositorio de GitHub.
Cree el trabajo de etiquetado en la consola de SageMaker
Para configurar el trabajo de etiquetado mediante la Consola de administración de AWS, complete los siguientes pasos:
- En la consola de SageMaker, en Verdad fundamental en el panel de navegación, elija Trabajo de etiquetado.
- Elegir Crear trabajo de etiquetado.
- Especifique la ubicación del manifiesto de entrada y la ruta de salida.
- Seleccionar Costumbre como el tipo de tarea.
- Elegir Próximo.
- Introduzca un título y una descripción de la tarea.
- Bajo Plantillasube tu amazon-sagemaker-ground-truth-task-uis/blob/master/gen-ai/multi-modal-content-evaluation.liquid.html” target=”_blank” rel=”noopener”>plantilla de interfaz de usuario.
Las funciones Lambda de anotación ahora son una configuración opcional en Configuración adicional.
- Elegir Avance para mostrar la plantilla de interfaz de usuario para su revisión.
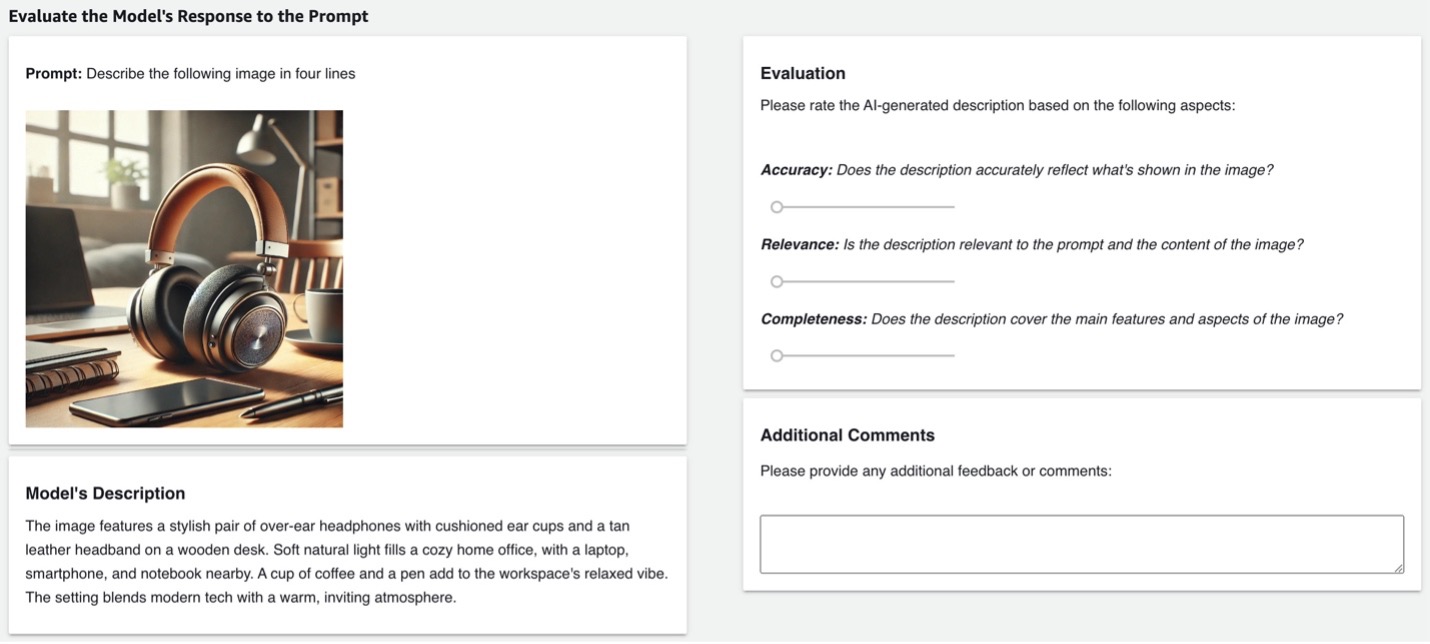
- Elegir Crear para crear el trabajo de etiquetado.
Cree el trabajo de etiquetado utilizando la API CreateLabelingJob
También puede crear el trabajo de etiquetado personalizado mediante programación utilizando el SDK de AWS para invocar el CreateLabelingJob API. Después de cargar los archivos de manifiesto de entrada en un depósito de S3 y configurar un equipo de trabajo, puede definir su trabajo de etiquetado en código, omitiendo los parámetros de la función Lambda si no son necesarios. El siguiente ejemplo demuestra cómo hacer esto usando Python y Boto3.
En la API, la función Lambda previa a la anotación se especifica mediante el PreHumanTaskLambdaArn parámetro dentro del HumanTaskConfig estructura. La función Lambda posterior a la anotación se especifica mediante el AnnotationConsolidationLambdaArn parámetro dentro del AnnotationConsolidationConfig estructura. Con la reciente actualización, ambos PreHumanTaskLambdaArn y AnnotationConsolidationConfig ahora son opcionales. Esto significa que puede omitirlos si su flujo de trabajo de etiquetado no requiere preprocesamiento o posprocesamiento de datos adicionales.
El siguiente código es un ejemplo de cómo crear un trabajo de etiquetado sin especificar las funciones Lambda:
Cuando los anotadores envían sus evaluaciones, sus respuestas se guardan directamente en su depósito S3 especificado. El archivo de manifiesto de salida incluye los campos de datos originales y un worker-response-ref que apunta a un archivo de respuesta del trabajador en S3. Este archivo de respuestas del trabajador contiene todas las anotaciones para ese objeto de datos. Si varios anotadores han trabajado en el mismo objeto de datos, sus anotaciones individuales se incluyen dentro de este archivo bajo un answers clave, que es una serie de respuestas. Cada respuesta incluye la entrada y los metadatos del anotador, como el tiempo de aceptación, el tiempo de envío y la identificación del trabajador.
Esto significa que todas las anotaciones para un objeto de datos determinado se recopilan en un solo lugar, lo que le permite procesarlas o analizarlas más tarde según sus requisitos específicos, sin necesidad de una función Lambda posterior a la anotación. Tiene acceso a todas las anotaciones sin procesar y puede realizar cualquier consolidación o agregación necesaria como parte de su flujo de trabajo de posprocesamiento.
Beneficios de etiquetar trabajos sin funciones Lambda
La creación de trabajos de etiquetado personalizados sin funciones Lambda ofrece varios beneficios:
- Configuración simplificada – Puede crear trabajos de etiquetado personalizados más rápidamente omitiendo la creación y configuración de funciones Lambda cuando no sean necesarias.
- Ahorro de tiempo – Reducir la cantidad de componentes en su flujo de trabajo de etiquetado ahorra tiempo de desarrollo y depuración.
- Complejidad reducida – Menos piezas móviles significan una menor probabilidad de encontrar errores de configuración o problemas de integración.
- Reducción de costos – Al no utilizar funciones Lambda, se reducen los costos asociados de implementar e invocar estos recursos.
- Flexibilidad – Conserva la capacidad de utilizar funciones Lambda para el preprocesamiento y la consolidación de anotaciones cuando su proyecto requiera estas capacidades. Esta actualización ofrece simplicidad para tareas sencillas y flexibilidad para requisitos más complejos.
Esta característica está actualmente disponible en todas las regiones de AWS que admiten SageMaker Ground Truth. En el futuro, busque tipos de tareas integradas que no requieran funciones Lambda de anotación, lo que brindará una experiencia simplificada para SageMaker Ground Truth en todos los ámbitos.
Conclusión
La introducción de flujos de trabajo para trabajos de etiquetado personalizados en SageMaker Ground Truth sin funciones Lambda simplifica significativamente el proceso de etiquetado de datos. Al hacer que las funciones Lambda sean opcionales, simplificamos y agilizamos la configuración de trabajos de etiquetado personalizados, lo que reduce los posibles errores y ahorra un tiempo valioso.
Esta actualización mantiene la flexibilidad de los flujos de trabajo personalizados y al mismo tiempo elimina pasos innecesarios para aquellos que no requieren procesamiento de datos especializado. Ya sea que esté realizando tareas de etiquetado simples o anotaciones complejas de varias etapas, SageMaker Ground Truth ahora ofrece una ruta más ágil hacia datos etiquetados de alta calidad.
Le animamos a explorar esta nueva función y ver cómo puede mejorar sus flujos de trabajo de etiquetado de datos. Para comenzar, consulte los siguientes recursos:
Acerca de los autores
 Sundar Raghavan es un arquitecto de soluciones especializado en IA/ML en AWS y ayuda a los clientes a aprovechar SageMaker y Bedrock para crear canales escalables y rentables para aplicaciones de visión por computadora, procesamiento de lenguaje natural e IA generativa. En su tiempo libre, a Sundar le encanta explorar nuevos lugares, probar restaurantes locales y disfrutar del aire libre.
Sundar Raghavan es un arquitecto de soluciones especializado en IA/ML en AWS y ayuda a los clientes a aprovechar SageMaker y Bedrock para crear canales escalables y rentables para aplicaciones de visión por computadora, procesamiento de lenguaje natural e IA generativa. En su tiempo libre, a Sundar le encanta explorar nuevos lugares, probar restaurantes locales y disfrutar del aire libre.
 Alan Ismael es ingeniero de software en AWS con sede en la ciudad de Nueva York. Se centra en la creación y el mantenimiento de productos de IA/ML escalables, como amazon SageMaker Ground Truth y amazon Bedrock Model Assessment. Fuera del trabajo, Alan está aprendiendo a jugar pickleball, con resultados mixtos.
Alan Ismael es ingeniero de software en AWS con sede en la ciudad de Nueva York. Se centra en la creación y el mantenimiento de productos de IA/ML escalables, como amazon SageMaker Ground Truth y amazon Bedrock Model Assessment. Fuera del trabajo, Alan está aprendiendo a jugar pickleball, con resultados mixtos.
 Yinan Lang es ingeniero de software en AWS GroundTruth. Trabajó en la infraestructura de GroundTruth, MechanicalTurk y Bedrock, así como en proyectos de atención al cliente para GroundTruth Plus. También se centra en la seguridad del producto y trabajó en la solución de riesgos y la creación de pruebas de seguridad. En su tiempo libre es un audiófilo y le encanta practicar composiciones para teclado de Bach.
Yinan Lang es ingeniero de software en AWS GroundTruth. Trabajó en la infraestructura de GroundTruth, MechanicalTurk y Bedrock, así como en proyectos de atención al cliente para GroundTruth Plus. También se centra en la seguridad del producto y trabajó en la solución de riesgos y la creación de pruebas de seguridad. En su tiempo libre es un audiófilo y le encanta practicar composiciones para teclado de Bach.
 jorge rey es pasante del verano de 2024 en amazon ai. Estudia Ciencias de la Computación y Matemáticas en la Universidad de Washington y actualmente cursa entre segundo y tercer año. A George le encanta estar al aire libre, jugar (ajedrez y todo tipo de juegos de cartas) y explorar Seattle, donde ha vivido toda su vida.
jorge rey es pasante del verano de 2024 en amazon ai. Estudia Ciencias de la Computación y Matemáticas en la Universidad de Washington y actualmente cursa entre segundo y tercer año. A George le encanta estar al aire libre, jugar (ajedrez y todo tipo de juegos de cartas) y explorar Seattle, donde ha vivido toda su vida.






{kind=link}