
En los últimos años, los avances en la visión por computadora han permitido a los investigadores, socorristas y gobiernos abordar el desafiante problema del procesamiento de imágenes satelitales globales para comprender nuestro planeta y nuestro impacto en él. AWS lanzó recientemente las capacidades geoespaciales de Amazon SageMaker para brindarle imágenes satelitales y modelos de aprendizaje automático (ML) geoespaciales de última generación, lo que reduce las barreras para este tipo de casos de uso. Para obtener más información, consulte Vista previa: uso de Amazon SageMaker para crear, entrenar e implementar modelos de aprendizaje automático mediante datos geoespaciales.
Muchas agencias, incluidos los primeros en responder, están utilizando estas ofertas para obtener una conciencia situacional a gran escala y priorizar los esfuerzos de socorro en áreas geográficas que han sido golpeadas por desastres naturales. A menudo, estas agencias manejan imágenes de desastres de baja altitud y fuentes satelitales, y estos datos a menudo no están etiquetados y son difíciles de usar. Los modelos de visión por computadora de última generación a menudo tienen un rendimiento inferior al mirar imágenes satelitales de una ciudad que ha sido azotada por un huracán o un incendio forestal. Dada la falta de estos conjuntos de datos, incluso los modelos de ML de última generación a menudo no pueden brindar la precisión y precisión necesarias para predecir las clasificaciones estándar de desastres de FEMA.
Los conjuntos de datos geoespaciales contienen metadatos útiles, como coordenadas de latitud y longitud, y marcas de tiempo, que pueden proporcionar contexto para estas imágenes. Esto es especialmente útil para mejorar la precisión de ML geoespacial para escenas de desastres, porque estas imágenes son intrínsecamente desordenadas y caóticas. Los edificios son menos rectangulares, la vegetación ha sufrido daños y los caminos lineales han sido interrumpidos por inundaciones o deslizamientos de tierra. Debido a que etiquetar estos conjuntos de datos masivos es costoso, manual y requiere mucho tiempo, el desarrollo de modelos ML que puedan automatizar el etiquetado y la anotación de imágenes es fundamental.
Para entrenar este modelo, necesitamos un subconjunto de verdad de tierra etiquetado del Conjunto de datos de imágenes de desastres a baja altitud (LADI). Este conjunto de datos consta de imágenes aéreas anotadas por humanos y máquinas recopiladas por la Patrulla Aérea Civil en apoyo de varias respuestas a desastres de 2015-2019. Estos conjuntos de datos LADI se centran en las temporadas de huracanes del Atlántico y los estados costeros a lo largo del Océano Atlántico y el Golfo de México. Dos distinciones clave son la baja altitud, la perspectiva oblicua de las imágenes y las características relacionadas con desastres, que rara vez se presentan en los puntos de referencia y conjuntos de datos de visión por computadora. Los equipos utilizaron las categorías existentes de FEMA para daños como inundaciones, escombros, incendios y humo o deslizamientos de tierra, que estandarizaron las categorías de las etiquetas. Luego, la solución puede hacer predicciones sobre el resto de los datos de entrenamiento y enrutar los resultados de menor confianza para la revisión humana.
En esta publicación, describimos nuestro diseño e implementación de la solución, las mejores prácticas y los componentes clave de la arquitectura del sistema.
Descripción general de la solución
En resumen, la solución involucró la construcción de tres tuberías:
- canalización de datos – Extrae los metadatos de las imágenes
- Canalización de aprendizaje automático – Clasifica y etiqueta imágenes
- Tubería de revisión Human-in-the-loop – Utiliza un equipo humano para revisar los resultados
El siguiente diagrama ilustra la arquitectura de la solución.
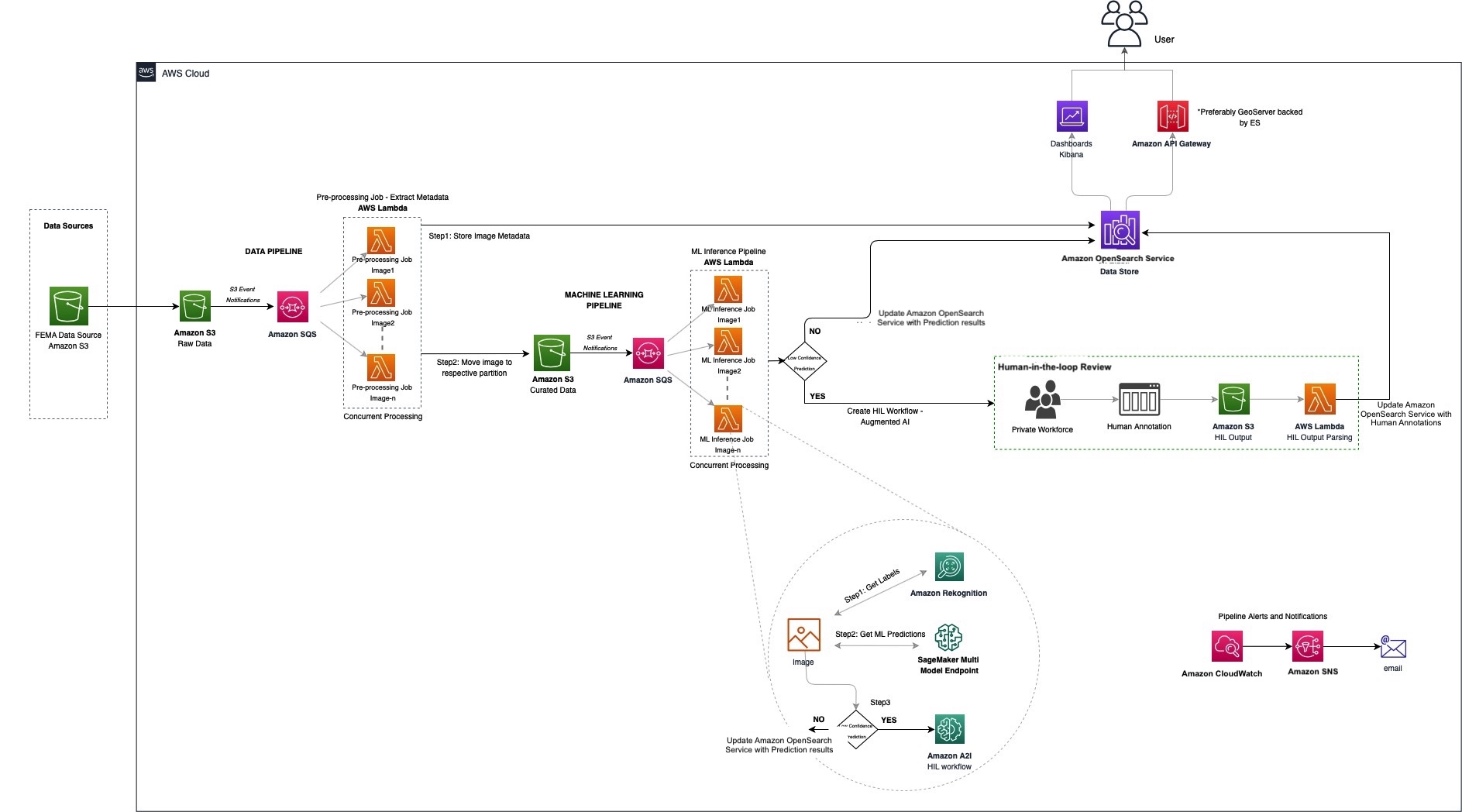
Dada la naturaleza de un sistema de etiquetado como este, diseñamos una arquitectura escalable horizontalmente que manejaría picos de ingesta sin aprovisionamiento excesivo mediante el uso de una arquitectura sin servidor. Utilizamos un patrón de uno a muchos desde Amazon Simple Queue Service (Amazon SQS) hasta AWS Lambda en varios puntos para respaldar estos picos de consumo y ofrecer resiliencia.
El uso de una cola de SQS para procesar eventos de Amazon Simple Storage Service (Amazon S3) nos ayuda a controlar la concurrencia del procesamiento posterior (funciones Lambda, en este caso) y manejar los picos de datos entrantes. Poner en cola los mensajes entrantes también actúa como un almacenamiento intermedio en caso de fallas posteriores.
Dadas las necesidades altamente paralelas, elegimos Lambda para procesar nuestras imágenes. Lambda es un servicio informático sin servidor que nos permite ejecutar código sin aprovisionar ni administrar servidores, creando una lógica de escalado de clústeres consciente de la carga de trabajo, manteniendo integraciones de eventos y administrando tiempos de ejecución.
Utilizamos Amazon OpenSearch Service como nuestro almacén de datos central para aprovechar sus búsquedas rápidas y altamente escalables y su herramienta de visualización integrada, OpenSearch Dashboards. Nos permite agregar iterativamente contexto a la imagen, sin tener que volver a compilar o cambiar la escala, y manejar la evolución del esquema.
Amazon Rekognition facilita la incorporación de análisis de imágenes y videos a nuestras aplicaciones mediante el uso de tecnología de aprendizaje profundo comprobada y altamente escalable. Con Amazon Rekognition, obtenemos una buena línea de base de los objetos detectados.
En las siguientes secciones, nos sumergimos en cada canalización con más detalle.
canalización de datos
El siguiente diagrama muestra el flujo de trabajo de la canalización de datos.
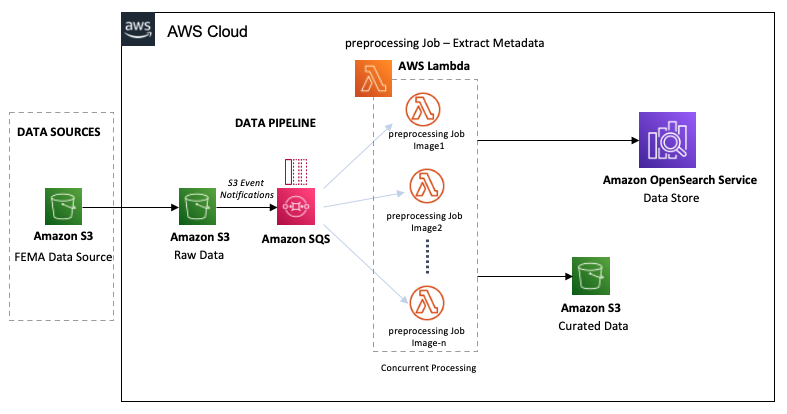
La canalización de datos LADI comienza con la ingestión de imágenes de datos sin procesar de la Protocolo Común de Alerta (CAP) de FEMA en un cubo S3. A medida que ingerimos las imágenes en el depósito de datos sin procesar, se procesan casi en tiempo real en dos pasos:
- El depósito de S3 desencadena notificaciones de eventos para todas las creaciones de objetos, creando mensajes en la cola de SQS para cada imagen ingerida.
- La cola de SQS invoca simultáneamente las funciones Lambda de preprocesamiento en la imagen.
Las funciones de Lambda realizan los siguientes pasos de preprocesamiento:
- Calcule el UUID para cada imagen, proporcionando un identificador único para cada imagen. Este ID identificará la imagen durante todo su ciclo de vida.
- Extraiga metadatos como las coordenadas GPS, el tamaño de la imagen, la información GIS y la ubicación S3 de la imagen y consérvelos en OpenSearch.
- En función de una búsqueda en los códigos FIPS, la función mueve la imagen al depósito S3 de datos seleccionados. Dividimos los datos por el código FIPS-State-code/FIPS-County-code/Year/Month de la imagen.
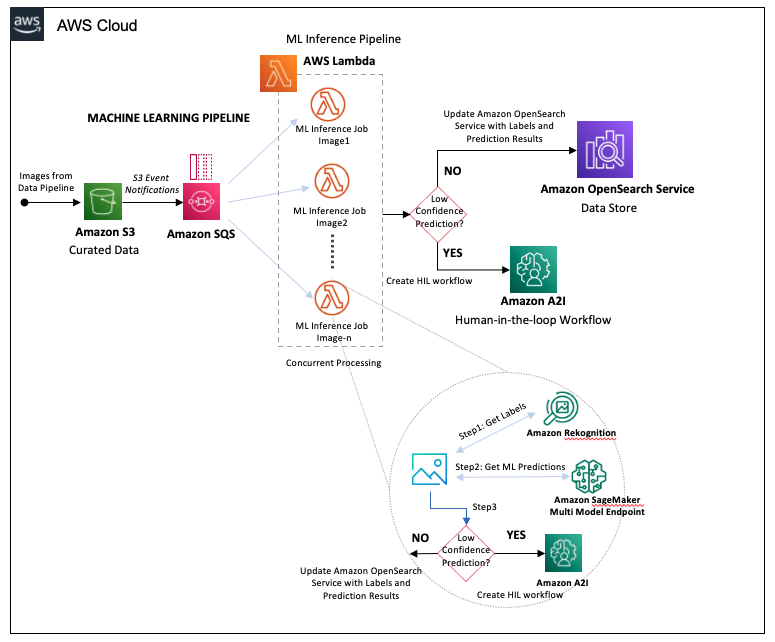
Canalización de aprendizaje automático
La canalización de ML comienza con las imágenes que aterrizan en el depósito S3 de datos seleccionados en el paso de la canalización de datos, lo que desencadena los siguientes pasos:
- Amazon S3 genera un mensaje en otra cola de SQS para cada objeto creado en el depósito de S3 de datos seleccionados.
- La cola de SQS activa simultáneamente funciones de Lambda para ejecutar el trabajo de inferencia de ML en la imagen.
Las funciones de Lambda realizan las siguientes acciones:
- Envíe cada imagen a Amazon Rekognition para la detección de objetos, almacenando las etiquetas devueltas y las respectivas puntuaciones de confianza.
- Componga la salida de Amazon Rekognition en parámetros de entrada para nuestro punto de enlace multimodelo de Amazon SageMaker. Este punto final aloja nuestro conjunto de clasificadores, que están capacitados para conjuntos específicos de etiquetas de daño.
- Pase los resultados del punto final de SageMaker a Amazon Augmented AI (Amazon A2I).
El siguiente diagrama ilustra el flujo de trabajo de canalización.
Tubería de revisión Human-in-the-loop
El siguiente diagrama ilustra la canalización humana en el bucle (HIL).
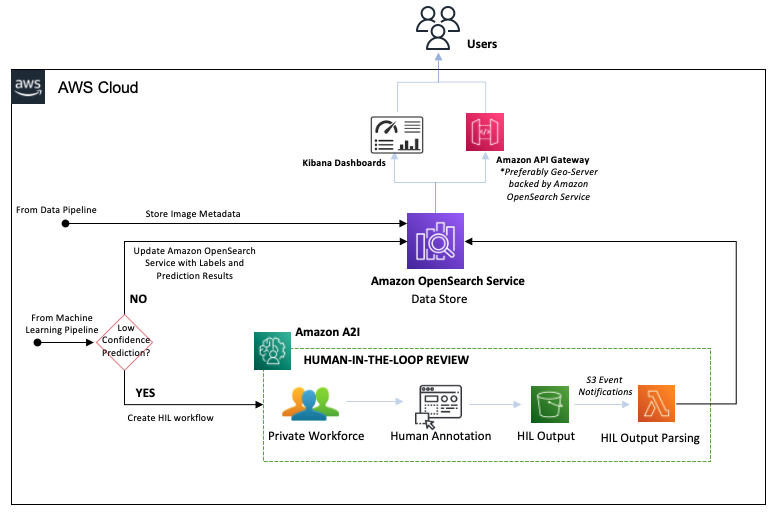
Con Amazon A2I, podemos configurar umbrales que activarán una revisión humana por parte de un equipo privado cuando un modelo produzca una predicción de baja confianza. También podemos usar Amazon A2I para proporcionar una auditoría continua de las predicciones de nuestro modelo. Los pasos del flujo de trabajo son los siguientes:
- Amazon A2I enruta predicciones de alta confianza a OpenSearch Service, actualizando los datos de la etiqueta de la imagen.
- Amazon A2I enruta las predicciones de baja confianza al equipo privado para anotar las imágenes manualmente.
- El revisor humano completa la anotación, generando un archivo de salida de anotación humana que se almacena en el depósito HIL Output S3.
- El depósito HIL Output S3 activa una función Lambda que analiza la salida de anotaciones humanas y actualiza los datos de la imagen en OpenSearch Service.
Al enrutar los resultados de las anotaciones humanas de vuelta al almacén de datos, podemos volver a entrenar los modelos de conjunto y mejorar iterativamente la precisión del modelo.
Con nuestros resultados de alta calidad ahora almacenados en OpenSearch Service, podemos realizar búsquedas geoespaciales y temporales a través de una API REST, utilizando Amazon API Gateway y Geoserver. OpenSearch Dashboard también permite a los usuarios buscar y ejecutar análisis con este conjunto de datos.
Resultados
El siguiente código muestra un ejemplo de nuestros resultados.

Con esta nueva canalización, creamos un respaldo humano para los modelos que aún no tienen un rendimiento completo. Esta nueva canalización de ML se ha puesto en producción para su uso con un Microservicio de filtro de imagen de Patrulla aérea civil que permite filtrar imágenes de la Patrulla Aérea Civil en Puerto Rico. Esto permite a los socorristas ver el alcance de los daños y ver imágenes asociadas con esos daños después de los huracanes. El laboratorio de datos de AWS, el programa de datos abiertos de AWS, el equipo de respuesta ante desastres de Amazon y el equipo humano en el circuito de AWS trabajaron con los clientes para desarrollar una canalización de código abierto que se puede usar para analizar los datos de Civil Air Patrol almacenados en Open Data. Registro de programas a pedido después de cualquier desastre natural. Para obtener más información sobre la arquitectura de canalización y una descripción general de la colaboración y el impacto, consulte el video Centrarse en la respuesta ante desastres con Amazon Augmented AI, el programa de datos abiertos de AWS y AWS Snowball.
Conclusión
A medida que el cambio climático continúa aumentando la frecuencia y la intensidad de las tormentas y los incendios forestales, seguimos viendo la importancia de usar ML para comprender el impacto de estos eventos en las comunidades locales. Estas nuevas herramientas pueden acelerar los esfuerzos de respuesta ante desastres y permitirnos usar los datos de estos análisis posteriores al evento para mejorar la precisión de predicción de estos modelos con aprendizaje activo. Estos nuevos modelos ML pueden automatizar la anotación de datos, lo que nos permite inferir el alcance del daño de cada uno de estos eventos a medida que superponemos etiquetas de daños con datos de mapas. Esos datos acumulativos también pueden ayudar a mejorar nuestra capacidad de predecir daños para futuros desastres, lo que puede informar estrategias de mitigación. Esto, a su vez, puede mejorar la resiliencia de las comunidades, las economías y los ecosistemas al brindarles a los tomadores de decisiones la información que necesitan para desarrollar políticas basadas en datos para abordar estas amenazas ambientales emergentes.
En esta publicación de blog, discutimos el uso de visión por computadora en imágenes satelitales. Esta solución pretende ser una arquitectura de referencia o una guía de inicio rápido que puede personalizar según sus propias necesidades.
Pruébelo y háganos saber cómo resolvió su caso de uso dejando sus comentarios en la sección de comentarios. Para obtener más información, consulte Capacidades geoespaciales de Amazon SageMaker.
Sobre los autores
 Vamshi Krishna Enabothala es Arquitecto Sr. Especialista en IA Aplicada en AWS. Trabaja con clientes de diferentes sectores para acelerar iniciativas de datos, análisis y aprendizaje automático de alto impacto. Le apasionan los sistemas de recomendación, la PNL y las áreas de visión por computadora en IA y ML. Fuera del trabajo, Vamshi es un entusiasta de RC, construye equipos de RC (aviones, automóviles y drones) y también disfruta de la jardinería.
Vamshi Krishna Enabothala es Arquitecto Sr. Especialista en IA Aplicada en AWS. Trabaja con clientes de diferentes sectores para acelerar iniciativas de datos, análisis y aprendizaje automático de alto impacto. Le apasionan los sistemas de recomendación, la PNL y las áreas de visión por computadora en IA y ML. Fuera del trabajo, Vamshi es un entusiasta de RC, construye equipos de RC (aviones, automóviles y drones) y también disfruta de la jardinería.
 morgan duton es gerente sénior de programas técnicos en el equipo de Amazon Augmented AI y Amazon SageMaker Ground Truth. Trabaja con clientes empresariales, académicos y del sector público para acelerar la adopción de aprendizaje automático y servicios de ML human-in-the-loop.
morgan duton es gerente sénior de programas técnicos en el equipo de Amazon Augmented AI y Amazon SageMaker Ground Truth. Trabaja con clientes empresariales, académicos y del sector público para acelerar la adopción de aprendizaje automático y servicios de ML human-in-the-loop.
 Sandeep Verma es Arquitecto sénior de creación de prototipos en AWS. Le gusta profundizar en los desafíos de los clientes y crear prototipos para que los clientes aceleren la innovación. Tiene experiencia en IA/ML, es fundador de New Knowledge y, en general, es un apasionado de la tecnología. En su tiempo libre le encanta viajar y esquiar con su familia.
Sandeep Verma es Arquitecto sénior de creación de prototipos en AWS. Le gusta profundizar en los desafíos de los clientes y crear prototipos para que los clientes aceleren la innovación. Tiene experiencia en IA/ML, es fundador de New Knowledge y, en general, es un apasionado de la tecnología. En su tiempo libre le encanta viajar y esquiar con su familia.





{kind=link}