 NEWSLETTER
NEWSLETTER
Predicting protein conformational changes remains a crucial challenge in computational biology and artificial intelligence. Advances made through deep learning, such as AlphaFold2, have moved the goal of predicting static structures, but do not address the dynamic conformational change that most proteins undertake to exert their biological functions. These transitions are fundamental to understanding a wide range of biological processes, from enzymatic activity to signal transduction. However, the lack of structural data for intermediate states makes it difficult to predict these transitions. Furthermore, existing models suffer from high free energy barriers of the transition states, making accurate predictions even more difficult. Catalyst for the advancement of a variety of fields, including drug design, synthetic biology and disease research, will be the
Existing models for describing protein conformational transitions include normal mode analysis based on elastic networks, as well as hybrid models that combine elastic networks with molecular dynamics simulations. These methods are appropriate for fairly simple conformational motions, but do not have the resolution to explain the vast, complex changes found in larger proteins. More recently, deep learning approaches, such as autoencoders, Boltzmann generators, and diffusion models, have been developed that map protein structures to low-dimensional latent spaces. However, these models rely on a linear path between two states, which does not apply in complex, nonlinear transitions such as fold change. More importantly, high data demands and low data efficiency, plus a computational cost that excludes scalable real-time applications, make these approaches themselves unsatisfactory.
The authors detail a new deep learning strategy using high-throughput biophysical sampling to avoid data scarcity related to protein conformational transition. Molecular dynamics simulations were combined with improved sampling methods to produce a library of 2635 proteins with two experimentally determined states. This data set uses a general deep learning model called PATHpre that predicts structural pathways that result in conformational transitions with high accuracy. Fundamentally, the innovation of the HESpre module in PATHpre concerns the predictive performance of the high energy state along the transition pathway. The proposed model does not make linear latent space assumptions that may be subject to criticism. It presents immense generalization towards proteins of diverse conformations. That would make a great contribution if it addresses dynamic behavior modeling within complex systems, applying scalability and data efficiency at one level of focus.
In a PATHpre approach, distance matrices are applied on a system of two conformational states by predicting a convolutional neural network to acquire a high-energy state between such conformational states; That's where HESpre stops: only the special or unique contacts it determines take place at high residue pair energy through each pathway, based on the pairwise distance matrix quantifies contact formation and breaking for the pathway taken and the general contact matrix established. It contains four classes of classified MS proteins representing inter- and intradomain movements, localized unfolding, and global fold changes in their conformational properties. Multi-protein cross-validation was performed for the model, achieving strong Pearson correlations and low mean absolute errors in all steps; Therefore, it is very versatile in all structural classes. Good performance generally establishes the general applicability of the model on proteins of different sequence lengths and structure complexities.
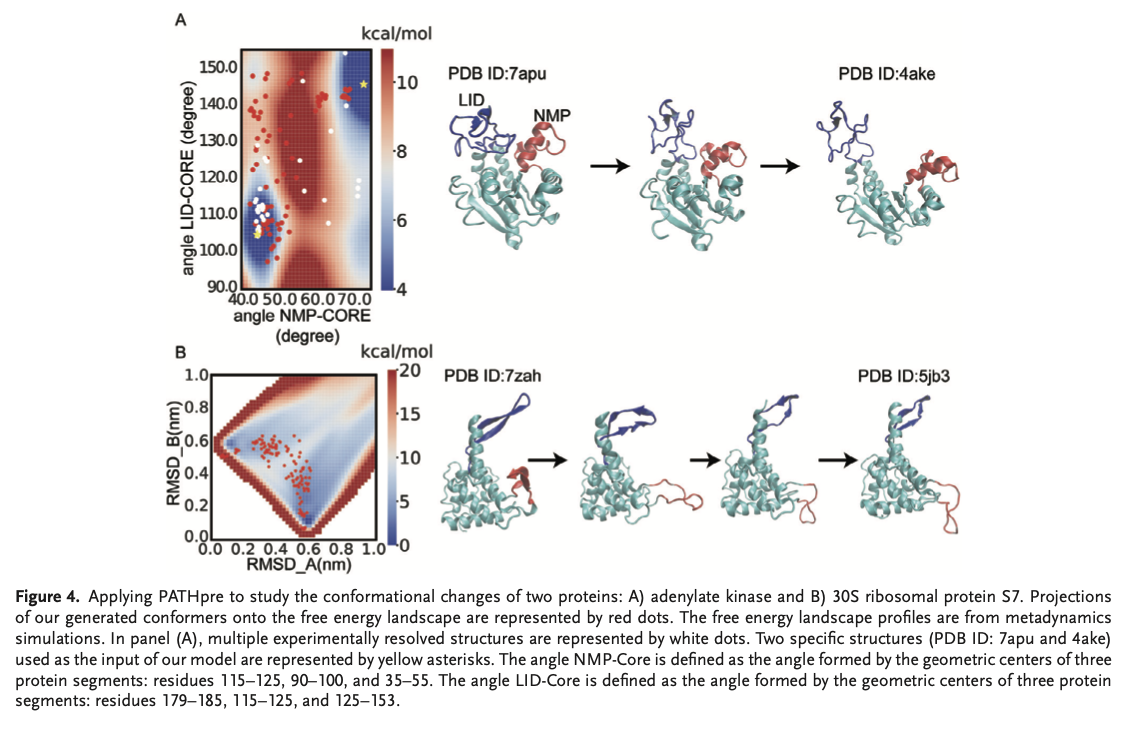
PATHpre is accurate at very high predictions of protein transition pathways by showing strong correlations with experimental and simulated data that exist on a variety of proteins. Evaluations also showed that PATHpre robustly captures simple to complex conformational changes and is consistent with different sequence lengths as well as structural complexity. Importantly, it accurately predicted transition pathways for individual proteins, such as adenylate kinase and 30S ribosomal protein S7, by matching experimental free energy landscapes and performed better than conventional hybrid approaches under challenging conditions. PATHpre's predictions aligned with known structures, and its mapping of fine intermediate states in fold change proteins confirmed its broad applicability and reliability in capturing the broad spectrum of protein conformational transitions.
This work marks significant progress in ai-driven protein modeling, providing a scalable and data-efficient approach to predict protein conformational transitions. Integrating large-scale biophysical sampling with deep learning in PATHpre addresses the more stringent challenge of limited data and captures nonlinear transitions in protein diversity. Indeed, this generalizable model will form the basis for greatly improved application of ai applications in computational biology, thus establishing a powerful tool to investigate the dynamic behavior of proteins in a variety of contexts, from drug discovery to biology. synthetic.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Sponsorship opportunity with us) Promote your research/product/webinar to over 1 million monthly readers and over 500,000 community members
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}