 NEWSLETTER
NEWSLETTER
India is constantly progressing in the field of artificial intelligence, which demonstrates remarkable growth and innovation. Krutrim ai Labs, a part of the Ola group, is one of the organizations that actively contributes to this progress. Krutrim recently introduced Chitrarth-1, a model of vision language (VLM) specifically developed for the diverse linguistic and cultural landscape of India. The model admits 10 main Indian languages, including Hindi, Tamil, Bengalí, Telugu, together with English, effectively addressing the varied needs of the country. This article explores the expansion capabilities of Chitrarth-1 and India in ai.
What is Chitrarth?
Chitrarth (Chitra derivative: Image and Artha: meaning) is a VLM of 7.5 billion parameters that combines vision and avant -garde vision capabilities. Developed to serve the linguistic diversity of India, admits 10 prominent Indian languages: Hindi, Bengalí, Telugu, Tamil, Marathi, Gujarati, Kannada, Malayalam, Hate and Assamese, next to English.
https://www.youtube.com/watch?v=tmzeweligsc
This model is a testimony of Krutrim's mission: create ai “For our country, our country and for our citizens. “
By taking advantage of a set of culturally rich and multilingual data, Chitrarth minimizes biases, improves accessibility and guarantees robust performance in languages and English. It stands out as a step towards equitable advances in ai, which makes technology inclusive and representative for users in India and beyond.
Research behind Chitrarth-1 has appeared in prominent academic documents such as “Chitrarth: Bridge of Vision and Language for one billion people ” (Neurips) and “Chitranuvad: Multilingual LLM adaptation for multimodal translation “ (Ninth Conference on Automatic Translation).
Also read: Moment of India: Races against China and the United States in Genai
Chitrarth architecture and parameters
Chitrarth is based on the Krutrim-7B LLM as its spine, augmented by a vision encoder based on the Siglip model (Siglip-SO400M-PATCH14-384). Its architecture includes:
- A siglip vision encoder previously caused to extract image characteristics.
- A capacitable linear mapping layer that projects these characteristics in the Token space of the LLM.
- Fine adjustment with instruction image text data sets for improved multimodal performance.
This design guarantees a perfect integration of visual and linguistic data, allowing Chitrarth to stand out in complex reasoning tasks.
Training and Methodology Data
Chitrarth's training process is developed in two stages, using a diverse multilingual data set:
STAGE 1: ADAPTER PRESSURE (PT)
- Prastrated in a carefully selected data set, translated into multiple languages indicating an open source model.
- It maintains a balanced division between English and languages indicates to guarantee linguistic diversity and equitable performance.
- Prevents bias towards any unique language, optimizing for computational efficiency and robust capabilities.
Stage 2: Instruction adjustment (IT)
- Adjusted in a complex set of instruction data to increase multimodal reasoning.
- It incorporates an English -based instructions setting data set and its multilingual translations.
- Includes a set of vision language with academic tasks and culturally diverse Indian images, such as:
- Prominent personalities
- Sights
- Work of art
- Culinary dishes
- It has high quality patented text data, which guarantees a balanced representation between the domains.
This two -step process equips Chitrarth to handle sophisticated multimodal tasks with cultural and linguistic nuances.
Also read: Top 10 llm that are bulit in India
Performance and evaluation
Chitrarth has been rigorously evaluated against latest generation VLMS such as Ideics 2 (7b) and Palo 7B, constantly overcoming them in several reference points while remains competitive in tasks such as Textvqa and Vizwiz. It also exceeds the flame vision instruction 3.2 11b in key metrics.
Bharatbench: a new standard
Krutrim presents Bharatbench, a set of comprehensive evaluation for 10 Languages IND of resources little resources in three tasks. Chitrarth's performance in Bharatbench establishes a baseline for future research, showing its unique ability to handle all the languages included. The results of the sample are presented below:
| Language | DAD | Llava-Banco | Mmvet |
|---|---|---|---|
| Telugu | 79.9 | 54.8 | 43.76 |
| Hindi | 78.68 | 51.5 | 38.85 |
| Bengali | 83.24 | 53.7 | 33.24 |
| Malayalam | 85.29 | 55.5 | 25.36 |
| Kannada | 85.52 | 58.1 | 46.19 |
| English | 87.63 | 67.9 | 30.49 |
<a target="_blank" href="https://ai-labs.olakrutrim.com/models/Chitrarth-1″ target=”_blank” rel=”noreferrer noopener nofollow”>To know more, click here.
How to access Chitrarth?
git clone https://github.com/ola-krutrim/Chitrarth.git
conda create --name chitrarth python=3.10
conda activate chitrarth
cd Chitrarth
pip install -e .
python chitrarth/inference.py --model-path "krutrim-ai-labs/Chitrarth" --image-file "assets/govt_school.jpeg" --query "Explain the image."
Examples of Chitrarth-1
1. Image analysis
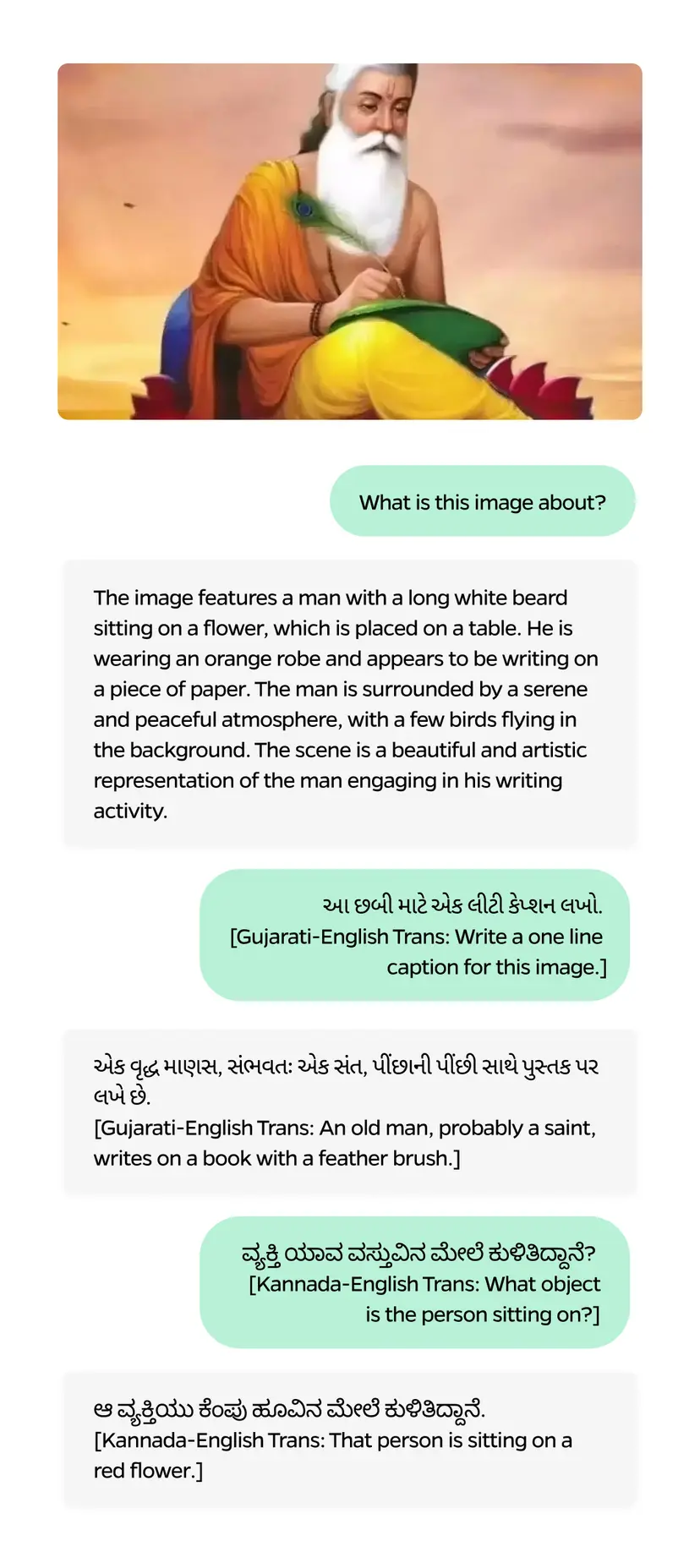
2. Generation of image subtitles

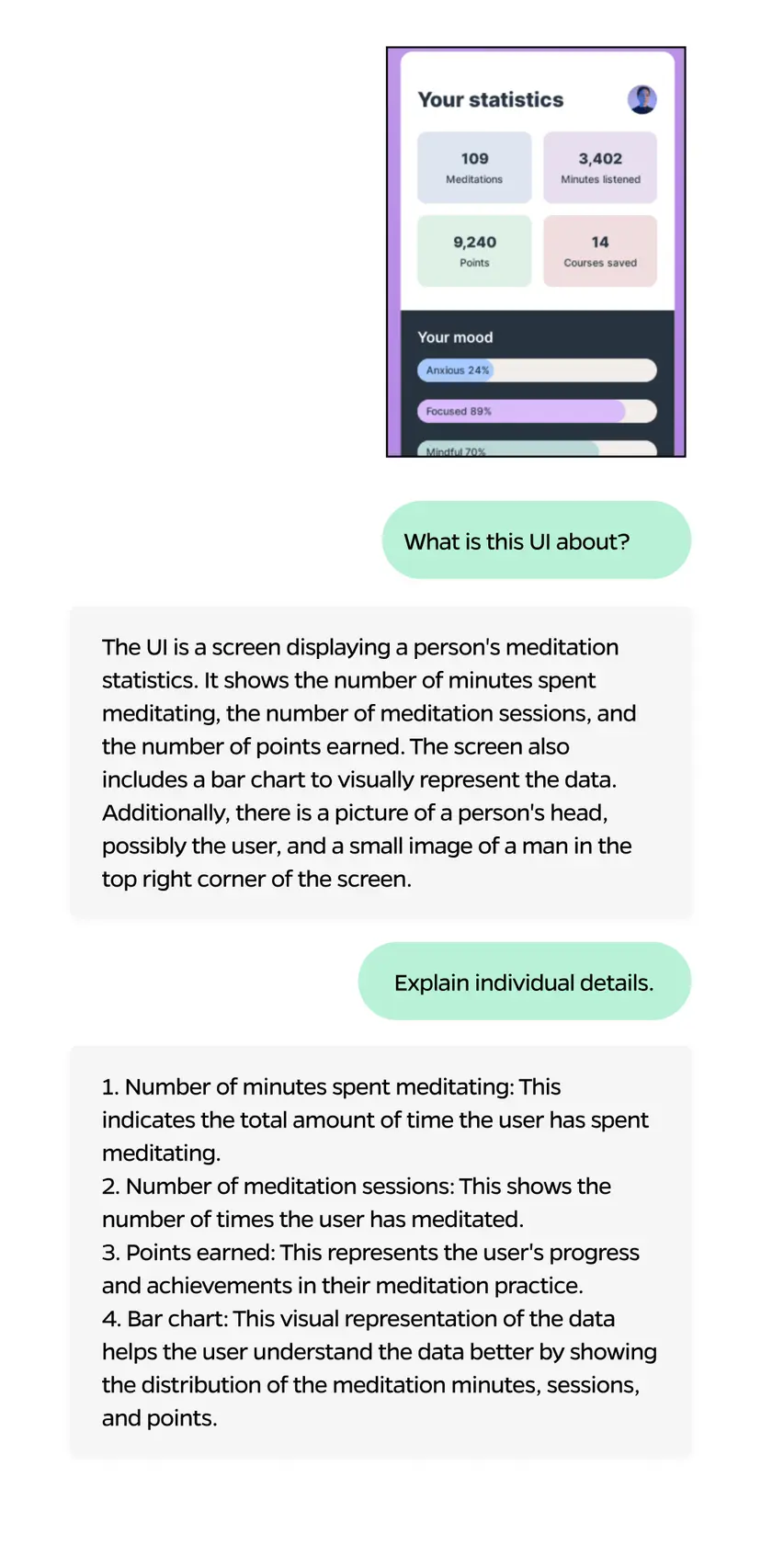
3. UI/UX screen analysis
Also read: Sutra-r0: The jump from India to the advanced reasoning of ai
Final note
A part of the Ola group, Krutrim is dedicated to creating the ai of Tomorrow computing battery. Together with Chitrarth, their offers include GPU as a service, ai Studio, Ola Maps, Krutrim Assistant, Language Labs, Krutrim Silicon and Contact Center ai. With Chitrarth-1, Krutrim ai Labs establishes a new standard for inclusive and culturally conscious ai, racing the way for a more equitable technological future.
Stay updated with the latest events in the world of ai with Analytics Vidhya News!

Hello, I'm Nitika, a content creator and seller of technology expert content. Creativity and learning new things are naturally to me. I have experience in the creation of results -based content strategies. I am well versed in SEO administration, keyword operations, web content writing, content strategy, editing and writing.





