 NEWSLETTER
NEWSLETTER
Introduction
The field of artificial intelligence has seen notable advances in recent years, particularly in the area of large language models. LLMs can generate human-like text, summarize documents, and write software code. Mistral-7B is one of the recent large language models that supports English text and code generation capabilities, and can be used for various tasks such as text summary, classification, text completion, and code completion.
What sets Mistral-7B-Instruct apart is its ability to deliver stellar performance despite having fewer parameters, making it a high-performance, cost-effective solution. The model recently gained popularity after benchmark results showed that it not only outperforms all 7B models on MT-Bench but also competes favorably with 13B chat models. In this blog, we will explore the features and capabilities of Mistral 7B, including its use cases, performance, and a practical guide to tuning the model.
Learning objectives
- Understand how large language models and Mistral 7B work
- Mistral 7B architecture and benchmarks.
- Mistral 7B use cases and how it works
- Dig deeper into the code to make inferences and make adjustments
This article was published as part of the Data Science Blogathon.
What are large language models?
The architecture of large language models is formed with transformers, which use attention mechanisms to capture long-range dependencies in the data, where multiple layers of transformer blocks contain multi-head self-attention and feedback neural networks. These models are pre-trained with text data, learning to predict the next word in a sequence, thus capturing patterns across languages. Pre-training weights can be adjusted on specific tasks. We will specifically look at the architecture of Mistral 7B LLM and what makes it stand out.
Mistral 7B Architecture
The Mistral 7B model’s transformer architecture efficiently balances high performance with memory usage, using attention mechanisms and caching strategies to outperform larger models in speed and quality. It uses 4096-window sliding window attention (SWA), which maximizes attention in longer sequences by allowing each token to attend to a subset of precursor tokens, optimizing attention in longer sequences.
A given hidden layer can access tokens from input layers at distances determined by the window size and layer depth. The model integrates modifications to Flash Attention and xFormers, doubling the speed over traditional attention mechanisms. Additionally, a Rolling Buffer Cache mechanism maintains a fixed cache size for efficient memory usage.
Mistral 7B on Google Collab
Let’s dive into the code and see how to run inference with the Mistral 7B model in Google Colab. We will use the free version with a single T4 GPU and load the model from Hugging face.
1. Install and import the ctransformers library into Colab.
#intsall ctransformers
pip install ctransformers(cuda)
#import
from ctransformers import AutoModelForCausalLM2. Initialize the model object from Hugging Face and set the necessary parameters. We will use a different version of the model as the original Mistral ai model may have problems loading the full model into Google Colab memory.
#load the model from huggingface with 50 gpu layers
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
model_type = "mistral", gpu_layers = 50)3. Define a function to print results vertically in Google Colab. This step can be skipped or modified if running in a different environment.
#function to print the model output in colab in a readable manner
def colab_print(text, max_width = 120):
words = text.split()
line = ""
for word in words:
if len(line) + len(word) + 1 > max_width:
print(line)
line = ""
line += word + " "
print (line)4. Generate text using the model and see the results. Modify the parameters to change the quality of the generated text.
#generate text
colab_print(llm('''Give me a well-written paragraph in 5 sentences about a Senior Data
Scientist (name - Suvojit) who writes blogs on LLMs on Analytics Vidhya. He studied
Masters in AIML in BITS Pilani and works at AZ Company, with a total of 4 years of
experience. Start the sentence with - Suvojit is a''',
max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93,
repetition_penalty = 1.2))Model response: Suvojit is a senior data scientist who has worked for 4 years at the AZ company as part of its team focusing on the design, implementation and improvement of predictive models of consumer behavior in its clients’ brands and business lines using data analysis techniques. limited memory machine learning. He writes LLM at Analytics Vidhya, which helps him stay updated with the latest trends in data science. He has a master’s degree in AIML from BITS Pilani, where he studied machine learning algorithms and their applications. Suvojit is passionate about using his knowledge of data science to help businesses make better decisions and improve performance.
Use cases
Let’s look at some of the use cases for the Mistral 7B in more detail.
Translation
Mistral 7B supports multiple languages for translation. Let’s look at the translations from English to French and Spanish and check the accuracy.
#translate English to French
colab_print(llm('''Translate this text from English to French:
"Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''',
max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93,
repetition_penalty = 1.2))Model response: The translation would be: “Suvojit is a senior data scientist who blogs at Analytics Vidhya.”
#tranlsate English to Spanish
colab_print(llm('''Translate this text from English to Spanish:
"Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''',
max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93,
repetition_penalty = 1.2))Model response: The translation would be: “Suvojit is a Senior Data Scientist who blogs at Analytics Vidhya.”
Summary
Use Mistral 7B to summarize documents into a shorter version using the appropriate summary instructions.
#Define the prompt with instructions
prompt=""'(INST) You are a helpful code assistant. Your task is to summarize text
into exactly two short sentences:
Transformers have revolutionized the field of large language models with their ability
to capture long-range dependencies and intricate patterns in text. Originating
from the paper "Attention Is All You Need" by Vaswani et al. in 2017, transformers
introduced the self-attention mechanism, which weighs input tokens differently based
on their relevance to a given token. This mechanism enables transformers to process
information more flexibly than traditional RNNs or LSTMs. Consequently, models
like GPT, BERT, and their subsequent iterations have been built on the transformer
architecture, leading to breakthroughs in numerous natural language processing tasks.
Their parallel processing capabilities further make them conducive to training on
vast amounts of data. However, as these models grow in size, concerns about their
environmental impact and computational demands also emerge. Despite these challenges,
the transformative power of transformers in language models remains undeniable.
Just summarize the text in exactly 2 short sentences without explanations:
(/INST)'''
#Summarize
colab_print(llm(prompt,
max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93,
repetition_penalty = 1.2))Model response: Transformers have revolutionized large language models by capturing long-range dependencies and intricate patterns, they have introduced a self-attention mechanism that allows them to process information flexibly, and subsequent implementations include advances such as GPT and BERT. However, as these models grow in size, concerns arise about their environmental impact and computational demands; Despite these challenges, they remain undeniably transformative in language modeling.
Custom instructions
We can use the (INST) tag to modify the user input and get a particular response from the model. For example, we can generate a JSON based on a text description.
prompt=""'(INST) You are a helpful code assistant. Your task is to generate a valid
JSON object based on the given information:
My name is Suvojit Hore, working in company AB and my address is AZ Street NY.
Just generate the JSON object without explanations:
(/INST)
'''
colab_print(llm(prompt,
max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93,
repetition_penalty = 1.2))Model response: “`json { “name”: “Suvojit Hore”, “company”: “AB”, “address”: “AZ Street NY” } “`
Mistral 7B tuning
Let’s see how we can tune the model using a single GPU in Google Colab. We will use a dataset that converts few-word descriptions of images into detailed, highly descriptive text. These results can be used in Midjourney to generate the specific image. The goal is to train the LLM to act as a rapid engineer for image generation.
Set up the environment and import the necessary libraries into Google Colab:
# Install the necessary libraries
!pip install pandas autotrain-advanced -q
!autotrain setup --update-torch
!pip install -q peft accelerate bitsandbytes safetensors
#import the necesary libraries
import pandas as pd
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
from huggingface_hub import notebook_loginLog in to Hugging Face from a browser and copy the access token. Use this token to log in to Hugging Face in the notebook.
notebook_login()Upload the dataset to Colab session storage. We will use the Midjourney dataset.
df = pd.read_csv("prompt_engineering.csv")
df.head(5)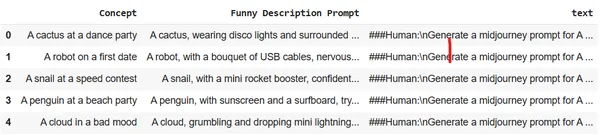
Train the model using Autotrain with the appropriate parameters. Modify the following command to run for your own Huggin Face repository and user access token.
!autotrain llm --train --project_name mistral-7b-sh-finetuned --model
username/Mistral-7B-Instruct-v0.1-sharded --token hf_yiguyfTFtufTFYUTUfuytfuys
--data_path . --use_peft --use_int4 --learning_rate 2e-4 --train_batch_size 12
--num_train_epochs 3 --trainer sft --target_modules q_proj,v_proj --push_to_hub
--repo_id username/mistral-7b-sh-finetunedNow let’s use the fitted model to run the inference engine and generate some detailed descriptions of the images.
#adapter and model
adapters_name = "suvz47/mistral-7b-sh-finetuned"
model_name = "bn22/Mistral-7B-Instruct-v0.1-sharded"
device = "cuda"
#set the config
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
#initialize the model
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
device_map='auto'
)Load the fitted model and the tokenizer.
#load the model and tokenizer
model = PeftModel.from_pretrained(model, adapters_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1
stop_token_ids = (0)Generate a detailed and descriptive mid-trip message with just a few words.
#prompt
text = "(INST) generate a midjourney prompt in less than 20 words for A computer
with an emotional chip (/INST)"
#encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('\n\n')
print(decoded(0))Model response: As the computer with an emotional chip begins to process his emotions, he begins to question his existence and purpose, leading him on a journey of self-discovery and self-improvement.
#prompt
text = "(INST) generate a midjourney prompt in less than 20 words for A rainbow
chasing its colors (/INST)"
#encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('\n\n')
print(decoded(0))Model response: A rainbow chasing colors finds itself in a desert where the sky is a sea of infinite blue and the colors of the rainbow are scattered in the sand.
Conclusion
Mistral 7B has proven to be a significant advance in the field of large language models. Its efficient architecture, combined with its superior performance, shows its potential to be a staple for various NLP tasks in the future. This blog provides information about the architecture of the model, its application, and how its power can be harnessed for specific tasks such as translation, summarization, and fine-tuning for other applications. With the right guidance and experimentation, Mistral 7B could redefine the boundaries of what is possible with LLMs.
Key takeaways
- Mistral-7B-Instruct excels in performance despite having fewer parameters.
- Uses Sliding Window Attention for optimization of long sequences.
- Features like Flash Attention and xFormers double your speed.
- Rolling Buffer Cache ensures efficient memory management.
- Versatile: Handles translation, summarization, structured data generation, text generation and completion.
- Asking Engineering to add custom instructions can help the model better understand the query and perform various complex language tasks.
- Adjust Mistral 7B for any specific linguistic task, such as acting as a fast engineer.
Frequent questions
A. Mistral-7B is designed for efficiency and performance. While it has fewer parameters than other models, its architectural advancements, such as Sliding Window Attention, allow it to deliver outstanding results, even outperforming larger models on specific tasks.
A. Yes, Mistral-7B can be adjusted for various tasks. The guide provides an example of how to tune the model to convert short text descriptions into detailed prompts for image generation.
A. Sliding window attention (SWA) allows the model to handle longer sequences efficiently. With a window size of 4096, SWA optimizes attention operations, allowing Mistral-7B to process long texts without compromising speed or accuracy.
A. Yes, when running Mistral-7B inferences, we recommend using the ctransformers library, especially when working in Google Colab. You can also load the model from Hugging Face for added convenience.
A. It is essential to prepare detailed instructions in the incoming message. The versatility of Mistral-7B allows you to understand and follow these detailed instructions, ensuring accurate and desired results. Quick and proper engineering can significantly improve model performance.
References
- Thumbnail: generated by stable diffusion
- Architecture – Paper
The media shown in this article is not the property of Analytics Vidhya and is used at the author’s discretion.






{kind=link}