
We can view this as HTML as follows to see what it looks like.
display(Markdown(data(2).metadata('text_as_html')))OUTPUT
It does a pretty good job here in preserving the structure however some of the extractions are not correct but you can still get away with it when using a powerful LLM like GPT-4o which we will see later. One option here is to use a more powerful table extraction model. Let’s now look at how to convert this HTML table into Markdown. While we can use the HTML text and put it directly in prompts (LLMs understand HTML tables well) or even better convert HTML tables to Markdown tables as depicted below.
import htmltabletomd
md_table = htmltabletomd.convert_table(data(2).metadata('text_as_html'))
print(md_table)OUTPUT
| | 2018 | 2019 | 2020 | 2021 | 2022 |
| :--- | :--- | :--- | :--- | :--- | :--- |
| Number of Fires (thousands) |
| Federal | 12.5 | 10.9 | 14.4 | 14.0 | 11.7 |
| FS | 5.6 | 5.3 | 6.7 | 6.2 | 59 |
| Dol | 7.0 | 5.3 | 7.6 | 7.6 | 5.8 |
| Other | 0.1 | 0.2 | <0.1 | 0.2 | 0.1 |
| Nonfederal | 45.6 | 39.6 | 44.6 | 45.0 | $7.2 |
| Total | 58.1 | 50.5 | 59.0 | 59.0 | 69.0 |
| Acres Burned (millions) |
| Federal | 4.6 | 3.1 | 7.1 | 5.2 | 40 |
| FS | 2.3 | 0.6 | 48 | 41 | 19 |
| Dol | 2.3 | 2.3 | 2.3 | 1.0 | 2.1 |
| Other | <0.1 | <0.1 | <0.1 | <0.1 | <0.1 |
| Nonfederal | 4.1 | 1.6 | 3.1 | Lg | 3.6 |
| Total | 8.8 | 4.7 | 10.1 | 7.1 | 7.6 |
This looks great! Let’s now separate the text and table elements and convert all table elements from HTML to Markdown.
docs = ()
tables = ()
for doc in data:
if doc.metadata('category') == 'Table':
tables.append(doc)
elif doc.metadata('category') == 'CompositeElement':
docs.append(doc)
for table in tables:
table.page_content = htmltabletomd.convert_table(table.metadata('text_as_html'))
len(docs), len(tables)OUTPUT
(5, 2)
We can also validate the tables extracted and converted into Markdown.
for table in tables:
print(table.page_content)
print()OUTPUT

We can now view some of the extracted images from the document as shown below.
! ls -l ./figuresOUTPUT
total 144
-rw-r--r-- 1 root root 27929 Aug 18 10:10 figure-1-1.jpg
-rw-r--r-- 1 root root 27182 Aug 18 10:10 figure-1-2.jpg
-rw-r--r-- 1 root root 26589 Aug 18 10:10 figure-1-3.jpg
-rw-r--r-- 1 root root 26448 Aug 18 10:10 figure-2-4.jpg
-rw-r--r-- 1 root root 29260 Aug 18 10:10 figure-2-5.jpg
from IPython.display import Image
Image('./figures/figure-1-2.jpg')OUTPUT
Image('./figures/figure-1-3.jpg')OUTPUT
Everything looks to be in order, we can see that the images from the document which are mostly charts and graphs have been correctly extracted.
<h3 class="wp-block-heading" id="h-enter-open-ai-api-key”>Enter Open ai API Key
We enter our Open ai key using the getpass() function so we don’t accidentally expose our key in the code.
from getpass import getpass
OPENAI_KEY = getpass('Enter Open ai API Key: ')Setup Environment Variables
Next, we setup some system environment variables which will be used later when authenticating our LLM.
import os
os.environ('OPENAI_API_KEY') = OPENAI_KEYLoad Connection to Multimodal LLM
Next, we create a connection to GPT-4o, the multimodal LLM we will use in our system.
from langchain_openai import ChatOpenAI
chatgpt = ChatOpenAI(model_name="gpt-4o", temperature=0)Setup the Multi-vector Retriever
We will now build our multi-vector-retriever to index image, text chunk and table element summaries, create their embeddings and store in the vector database and the raw elements in a document store and connect them so that we can then retrieve the raw image, text and table elements for user queries.
Create Text and Table Summaries
We will use GPT-4o to produce table and text summaries. Text summaries are advised if using large chunk sizes (e.g., as set above, we use 4k token chunks). Summaries are used to retrieve raw tables and / or raw chunks of text later on using the multi-vector retriever. Creating summaries of text elements is optional.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# Prompt
prompt_text = """
You are an assistant tasked with summarizing tables and text particularly for semantic retrieval.
These summaries will be embedded and used to retrieve the raw text or table elements
Give a detailed summary of the table or text below that is well optimized for retrieval.
For any tables also add in a one line description of what the table is about besides the summary.
Do not add additional words like Summary: etc.
Table or text chunk:
{element}
"""
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
summarize_chain = (
{"element": RunnablePassthrough()}
|
prompt
|
chatgpt
|
StrOutputParser() # extracts response as text
)
# Initialize empty summaries
text_summaries = ()
table_summaries = ()
text_docs = (doc.page_content for doc in docs)
table_docs = (table.page_content for table in tables)
text_summaries = summarize_chain.batch(text_docs, {"max_concurrency": 5})
table_summaries = summarize_chain.batch(table_docs, {"max_concurrency": 5})The above snippet uses a LangChain chain to create a detailed summary of each text chunk and table and we can see the output for some of them below.
# Summary of a text chunk element
text_summaries(0)OUTPUT
Wildfires include lightning-caused, unauthorized human-caused, and escaped
prescribed burns. States handle wildfires on nonfederal lands, while federal
agencies manage those on federal lands. The Forest Service oversees 193
million acres of the National Forest System, ...... In 2022, 68,988
wildfires burned 7.6 million acres, with over 40% of the acreage in Alaska.
As of June 1, 2023, 18,300 wildfires have burned over 511,000 acres.
#Summary of a table element
table_summaries(0)OUTPUT
This table provides data on the number of fires and acres burned from 2018 to
2022, categorized by federal and nonfederal sources. \n\nNumber of Fires
(thousands):\n- Federal: Ranges from 10.9K to 14.4K, peaking in 2020.\n- FS
(Forest Service): Ranges from 5.3K to 6.7K, with an anomaly of 59K in
2022.\n- Dol (Department of the Interior): Ranges from 5.3K to 7.6K.\n-
Other: Consistently low, mostly around 0.1K.\n- ....... Other: Consistently
less than 0.1M.\n- Nonfederal: Ranges from 1.6M to 4.1M, with an anomaly of
"Lg" in 2021.\n- Total: Ranges from 4.7M to 10.1M.
This looks pretty good and the summaries are quite informative and should generate good embeddings for retrieval later on.
Create Image Summaries
We will use GPT-4o to produce the image summaries. However since images cannot be passed directly, we will base64 encode the images as strings and then pass it to them. We start by creating a few utility functions to encode images and generate a summary for any input image by passing it to GPT-4o.
import base64
import os
from langchain_core.messages import HumanMessage
# create a function to encode images
def encode_image(image_path):
"""Getting the base64 string"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# create a function to summarize the image by passing a prompt to GPT-4o
def image_summarize(img_base64, prompt):
"""Make image summary"""
chat = ChatOpenAI(model="gpt-4o", temperature=0)
msg = chat.invoke(
(
HumanMessage(
content=(
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url":
f"data:image/jpeg;base64,{img_base64}"},
},
)
)
)
)
return msg.contentThe above functions serve the following purpose:
- encode_image(image_path): Reads an image file from the provided path, converts it to a binary stream, and then encodes it to a base64 string. This string can be used to send the image over to GPT-4o.
- image_summarize(img_base64, prompt): Sends a base64-encoded image along with a text prompt to the GPT-4o model. It returns a summary of the image based on the given prompt by invoking a prompt where both text and image inputs are processed.
We now use the above utilities to summarize each of our images using the following function.
def generate_img_summaries(path):
"""
Generate summaries and base64 encoded strings for images
path: Path to list of .jpg files extracted by Unstructured
"""
# Store base64 encoded images
img_base64_list = ()
# Store image summaries
image_summaries = ()
# Prompt
prompt = """You are an assistant tasked with summarizing images for retrieval.
Remember these images could potentially contain graphs, charts or
tables also.
These summaries will be embedded and used to retrieve the raw image
for question answering.
Give a detailed summary of the image that is well optimized for
retrieval.
Do not add additional words like Summary: etc.
"""
# Apply to images
for img_file in sorted(os.listdir(path)):
if img_file.endswith(".jpg"):
img_path = os.path.join(path, img_file)
base64_image = encode_image(img_path)
img_base64_list.append(base64_image)
image_summaries.append(image_summarize(base64_image, prompt))
return img_base64_list, image_summaries
# Image summaries
IMG_PATH = './figures'
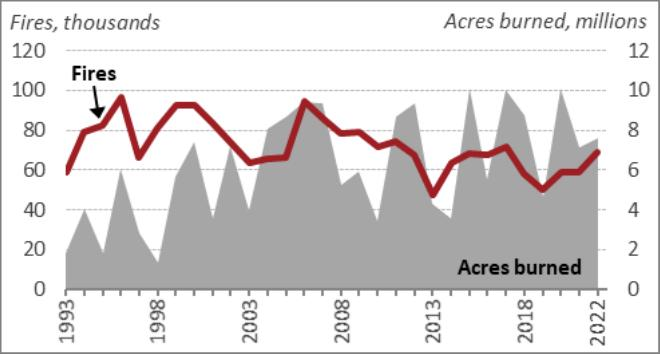
imgs_base64, image_summaries = generate_img_summaries(IMG_PATH) We can now look at one of the images and its summary just to get an idea of how GPT-4o has generated the image summaries.
# View one of the images
display(Image('./figures/figure-1-2.jpg'))OUTPUT
# View the image summary generated by GPT-4o
image_summaries(1)OUTPUT
Line graph showing the number of fires (in thousands) and the acres burned
(in millions) from 1993 to 2022. The left y-axis represents the number of
fires, peaking around 100,000 in the mid-1990s and fluctuating between
50,000 and 100,000 thereafter. The right y-axis represents acres burned,
with peaks reaching up to 10 million acres. The x-axis shows the years from
1993 to 2022. The graph uses a red line to depict the number of fires and a
grey shaded area to represent the acres burned.
Overall looks to be quite descriptive and we can use these summaries and embed them into a vector database soon.
Index Documents and Summaries in the Multi-Vector Retriever
We are now going to add the raw text, table and image elements and their summaries to a Multi Vector Retriever using the following strategy:
- Store the raw texts, tables, and images in the docstore (here we are using Redis).
- Embed the text summaries (or text elements directly), table summaries, and image summaries using an embedder model and store the summaries and embeddings in the vectorstore (here we are using Chroma) for efficient semantic retrieval.
- Connect the two using a common doc_id identifier in the multi-vector retriever
Start Redis Server for Docstore
The first step is to get the docstore ready, for this we use the following code to download the open-source version of Redis and start a Redis server locally as a background process.
%%sh
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb (signed-by=/usr/share/keyrings/redis-archive-keyring.gpg) https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get update > /dev/null 2>&1
sudo apt-get install redis-stack-server > /dev/null 2>&1
redis-stack-server --daemonize yesOUTPUT
deb (signed-by=/usr/share/keyrings/redis-archive-keyring.gpg)
https://packages.redis.io/deb jammy main
Starting redis-stack-server, database path /var/lib/redis-stack
Open ai Embedding Models
LangChain enables us to access Open ai embedding models which include the newest models: a smaller and highly efficient text-embedding-3-small model, and a larger and more powerful text-embedding-3-large model. We need an embedding model to convert our document chunks into embeddings before storing in our vector database.
from langchain_openai import OpenAIEmbeddings
# details here: https://openai.com/blog/new-embedding-models-and-api-updates
openai_embed_model = OpenAIEmbeddings(model="text-embedding-3-small")Implement the Multi-Vector Retriever Function
We now create a function that will help us connect our vector store and doctors and index the documents, summaries, and embeddings using the following function.
import uuid
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_community.storage import RedisStore
from langchain_community.utilities.redis import get_client
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
def create_multi_vector_retriever(
docstore, vectorstore, text_summaries, texts, table_summaries, tables,
image_summaries, images
):
"""
Create retriever that indexes summaries, but returns raw images or texts
"""
id_key = "doc_id"
# Create the multi-vector retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=docstore,
id_key=id_key,
)
# Helper function to add documents to the vectorstore and docstore
def add_documents(retriever, doc_summaries, doc_contents):
doc_ids = (str(uuid.uuid4()) for _ in doc_contents)
summary_docs = (
Document(page_content=s, metadata={id_key: doc_ids(i)})
for i, s in enumerate(doc_summaries)
)
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, doc_contents)))
# Add texts, tables, and images
# Check that text_summaries is not empty before adding
if text_summaries:
add_documents(retriever, text_summaries, texts)
# Check that table_summaries is not empty before adding
if table_summaries:
add_documents(retriever, table_summaries, tables)
# Check that image_summaries is not empty before adding
if image_summaries:
add_documents(retriever, image_summaries, images)
return retrieverFollowing are the key components in the above function and their role:
- create_multi_vector_retriever(…): This function sets up a retriever that indexes text, table, and image summaries but retrieves raw data (texts, tables, or images) based on the indexed summaries.
- add_documents(retriever, doc_summaries, doc_contents): A helper function that generates unique IDs for the documents, adds the summarized documents to the vectorstore, and stores the full content (raw text, tables, or images) in the docstore.
- retriever.vectorstore.add_documents(…): Adds the summaries and embeddings to the vectorstore, where the retrieval will be performed based on the summary embeddings.
- retriever.docstore.mset(…): Stores the actual raw document content (texts, tables, or images) in the docstore, which will be returned when a matching summary is retrieved.
Create the vector database
We will now create our vectorstore using Chroma as the vector database so we can index summaries and their embeddings shortly.
# The vectorstore to use to index the summaries and their embeddings
chroma_db = Chroma(
collection_name="mm_rag",
embedding_function=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
)Create the document database
We will now create our docstore using Redis as the database platform so we can index the actual document elements which are the raw text chunks, tables and images shortly. Here we just connect to the Redis server we started earlier.
# Initialize the storage layer - to store raw images, text and tables
client = get_client('redis://localhost:6379')
redis_store = RedisStore(client=client) # you can use filestore, memorystore, any other DB store alsoCreate the multi-vector retriever
We will now index our document raw elements, their summaries and embeddings in the document and vectorstore and build the multi-vector retriever.
# Create retriever
retriever_multi_vector = create_multi_vector_retriever(
redis_store, chroma_db,
text_summaries, text_docs,
table_summaries, table_docs,
image_summaries, imgs_base64,
)Test the Multi-vector Retriever
We will now test the retrieval aspect in our RAG pipeline to see if our multi-vector retriever is able to return the right text, table and image elements based on user queries. Before we check it out, let’s create a utility to be able to visualize any images retrieved as we need to convert them back from their encoded base64 format into the raw image element to be able to view it.
from IPython.display import HTML, display, Image
from PIL import Image
import base64
from io import BytesIO
def plt_img_base64(img_base64):
"""Disply base64 encoded string as image"""
# Decode the base64 string
img_data = base64.b64decode(img_base64)
# Create a BytesIO object
img_buffer = BytesIO(img_data)
# Open the image using PIL
img = Image.open(img_buffer)
display(img)This function will help in taking in any base64 encoded string representation of an image, convert it back into an image and display it. Now let’s test our retriever.
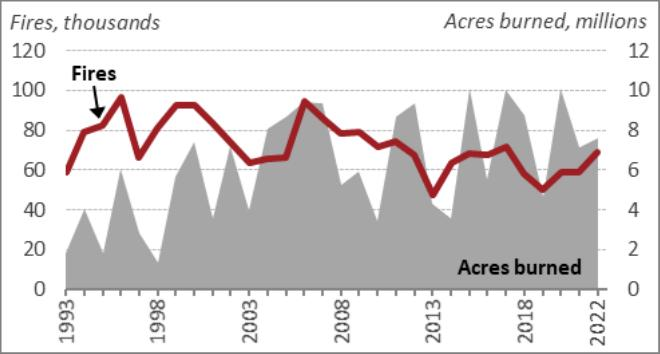
# Check retrieval
query = "Tell me about the annual wildfires trend with acres burned"
docs = retriever_multi_vector.invoke(query, limit=5)
# We get 3 relevant docs
len(docs)OUTPUT
3
We can check out the documents retrieved as follows:
docs(b'a. aa = Informing the legislative debate since 1914 Congressional Research
Service\n\nUpdated June 1, 2023\n\nWildfire Statistics\n\nWildfires are
unplanned fires, including lightning-caused fires, unauthorized human-caused
fires, and escaped fires from prescribed burn projects ...... and an average
of 7.2 million acres impacted annually. In 2022, 68,988 wildfires burned 7.6
million acres. Over 40% of those acres were in Alaska (3.1 million
acres).\n\nAs of June 1, 2023, around 18,300 wildfires have impacted over
511,000 acres this year.',b'| | 2018 | 2019 | 2020 | 2021 | 2022 |\n| :--- | :--- | :--- | :--- | :--
- | :--- |\n| Number of Fires (thousands) |\n| Federal | 12.5 | 10.9 | 14.4 |
14.0 | 11.7 |\n| FS | 5.6 | 5.3 | 6.7 | 6.2 | 59 |\n| Dol | 7.0 | 5.3 | 7.6
| 7.6 | 5.8 |\n| Other | 0.1 | 0.2 | <0.1 | 0.2 | 0.1 |\n| Nonfederal |
45.6 | 39.6 | 44.6 | 45.0 | $7.2 |\n| Total | 58.1 | 50.5 | 59.0 | 59.0 |
69.0 |\n| Acres Burned (millions) |\n| Federal | 4.6 | 3.1 | 7.1 | 5.2 | 40
|\n| FS | 2.3 | 0.6 | 48 | 41 | 19 |\n| Dol | 2.3 | 2.3 | 2.3 | 1.0 | 2.1
|\n| Other | <0.1 | <0.1 | <0.1 | <0.1 | <0.1 |\n| Nonfederal
| 4.1 | 1.6 | 3.1 | Lg | 3.6 |\n| Total | 8.8 | 4.7 | 10.1 | 7.1 | 7.6 |\n',
b'/9j/4AAQSkZJRgABAQAAAQABAAD/......RXQv+gZB+RrYooAx/')
It is clear that the first retrieved element is a text chunk, the second retrieved element is a table and the last retrieved element is an image for our given query. We can also use the utility function from above to view the retrieved image.
# view retrieved image
plt_img_base64(docs(2))OUTPUT
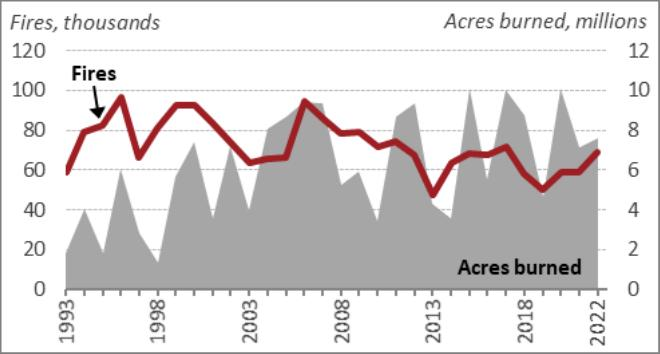
We can definitely see the right context being retrieved based on the user question. Let’s try one more and validate this again.
# Check retrieval
query = "Tell me about the percentage of residences burned by wildfires in 2022"
docs = retriever_multi_vector.invoke(query, limit=5)
# We get 2 docs
docsOUTPUT
(b'Source: National Interagency Coordination Center (NICC) Wildland Fire
Summary and Statistics annual reports. Notes: FS = Forest Service; DOI =
Department of the Interior. Column totals may not sum precisely due to
rounding.\n\n2022\n\nYear Acres burned (millions) Number of Fires 2015 2020
2017 2006 2007\n\nSource: NICC Wildland Fire Summary and Statistics annual
reports. ...... and structures (residential, commercial, and other)
destroyed. For example, in 2022, over 2,700 structures were burned in
wildfires; the majority of the damage occurred in California (see Table 2).',b'| | 2019 | 2020 | 2021 | 2022 |\n| :--- | :--- | :--- | :--- | :--- |\n|
Structures Burned | 963 | 17,904 | 5,972 | 2,717 |\n| % Residences | 46% |
54% | 60% | 46% |\n')
This definitely shows that our multi-vector retriever is working quite well and is able to retrieve multimodal contextual data based on user queries!
import re
import base64
# helps in detecting base64 encoded strings
def looks_like_base64(sb):
"""Check if the string looks like base64"""
return re.match("^(A-Za-z0-9+/)+(=){0,2}$", sb) is not None
# helps in checking if the base64 encoded image is actually an image
def is_image_data(b64data):
"""
Check if the base64 data is an image by looking at the start of the data
"""
image_signatures = {
b"\xff\xd8\xff": "jpg",
b"\x89\x50\x4e\x47\x0d\x0a\x1a\x0a": "png",
b"\x47\x49\x46\x38": "gif",
b"\x52\x49\x46\x46": "webp",
}
try:
header = base64.b64decode(b64data)(:8) # Decode and get the first 8 bytes
for sig, format in image_signatures.items():
if header.startswith(sig):
return True
return False
except Exception:
return False
# returns a dictionary separating images and text (with table) elements
def split_image_text_types(docs):
"""
Split base64-encoded images and texts (with tables)
"""
b64_images = ()
texts = ()
for doc in docs:
# Check if the document is of type Document and extract page_content if so
if isinstance(doc, Document):
doc = doc.page_content.decode('utf-8')
else:
doc = doc.decode('utf-8')
if looks_like_base64(doc) and is_image_data(doc):
b64_images.append(doc)
else:
texts.append(doc)
return {"images": b64_images, "texts": texts}These utility functions mentioned above help us in separating the text (with table) elements and image elements separately from the retrieved context documents. Their functionality is explained in a bit more detail as follows:
- looks_like_base64(sb): Uses a regular expression to check if the input string follows the typical pattern of base64 encoding. This helps identify whether a given string might be base64-encoded.
- is_image_data(b64data): Decodes the base64 string and checks the first few bytes of the data against known image file signatures (JPEG, PNG, GIF, WebP). It returns True if the base64 string represents an image, helping verify the type of base64-encoded data.
- split_image_text_types(docs): Processes a list of documents, differentiating between base64-encoded images and regular text (which could include tables). It checks each document using the looks_like_base64 and is_image_data functions and then splits the documents into two categories: images (base64-encoded images) and texts (non-image documents). The result is returned as a dictionary with two lists.
We can quickly test this function on any retrieval output from our multi-vector retriever as shown below with an example.
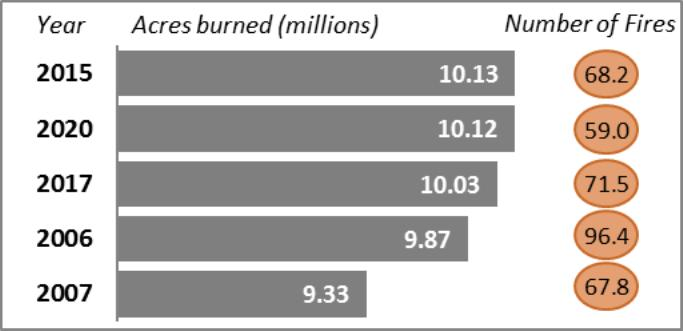
# Check retrieval
query = "Tell me detailed statistics of the top 5 years with largest wildfire
acres burned"
docs = retriever_multi_vector.invoke(query, limit=5)
r = split_image_text_types(docs)
r OUTPUT
{'images': ('/9j/4AAQSkZJRgABAQAh......30aAPda8Kn/wCPiT/eP86PPl/56v8A99GpURSgJGTQB//Z'),'texts': ('Figure 2. Top Five Years with Largest Wildfire Acreage Burned
Since 1960\n\nTable 1. Annual Wildfires and Acres Burned',
'Source: NICC Wildland Fire Summary and Statistics annual reports.\n\nConflagrations Of the 1.6 million wildfires that have occurred
since 2000, 254 exceeded 100,000 acres burned and 16 exceeded 500,000 acres
burned. A small fraction of wildfires become .......')}
Looks like our function is working perfectly and separating out the retrieved context elements as desired.
Build End-to-End Multimodal RAG Pipeline
Now let’s connect our multi-vector retriever, prompt instructions and build a multimodal RAG chain. To start with, we create a multimodal prompt function which will take the context text, tables and images and structure a proper prompt in the right format which can then be passed into GPT-4o.
from operator import itemgetter
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_core.messages import HumanMessage
def multimodal_prompt_function(data_dict):
"""
Create a multimodal prompt with both text and image context.
This function formats the provided context from `data_dict`, which contains
text, tables, and base64-encoded images. It joins the text (with table) portions
and prepares the image(s) in a base64-encoded format to be included in a
message.
The formatted text and images (context) along with the user question are used to
construct a prompt for GPT-4o
"""
formatted_texts = "\n".join(data_dict("context")("texts"))
messages = ()
# Adding image(s) to the messages if present
if data_dict("context")("images"):
for image in data_dict("context")("images"):
image_message = {
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image}"},
}
messages.append(image_message)
# Adding the text for analysis
text_message = {
"type": "text",
"text": (
f"""You are an analyst tasked with understanding detailed information
and trends from text documents,
data tables, and charts and graphs in images.
You will be given context information below which will be a mix of
text, tables, and images usually of charts or graphs.
Use this information to provide answers related to the user
question.
Do not make up answers, use the provided context documents below and
answer the question to the best of your ability.
User question:
{data_dict('question')}
Context documents:
{formatted_texts}
Answer:
"""
),
}
messages.append(text_message)
return (HumanMessage(content=messages))This function helps in structuring the prompt to be sent to GPT-4o as explained here:
- multimodal_prompt_function(data_dict): creates a multimodal prompt by combining text and image data from a dictionary. The function formats text context (with tables), appends base64-encoded images (if available), and constructs a HumanMessage to send to GPT-4o for analysis along with the user question.
We now construct our multimodal RAG chain using the following code snippet.
# Create RAG chain
multimodal_rag = (
{
"context": itemgetter('context'),
"question": itemgetter('input'),
}
|
RunnableLambda(multimodal_prompt_function)
|
chatgpt
|
StrOutputParser()
)
# Pass input query to retriever and get context document elements
retrieve_docs = (itemgetter('input')
|
retriever_multi_vector
|
RunnableLambda(split_image_text_types))
# Below, we chain `.assign` calls. This takes a dict and successively
# adds keys-- "context" and "answer"-- where the value for each key
# is determined by a Runnable (function or chain executing at runtime).
# This helps in having the retrieved context along with the answer generated by GPT-4o
multimodal_rag_w_sources = (RunnablePassthrough.assign(context=retrieve_docs)
.assign(answer=multimodal_rag)
)The chains create above work as follows:
- multimodal_rag_w_sources: This chain, chains the assignments of context and answer. It assigns the context from the documents retrieved using retrieve_docs and assigns the answer generated by the multimodal RAG chain using multimodal_rag. This setup ensures that both the retrieved context and the final answer are available and structured together as part of the output.
- retrieve_docs: This chain retrieves the context documents related to the input query. It starts by extracting the user’s input , passes the query through our multi-vector retriever to fetch relevant documents, and then calls the split_image_text_types function we defined earlier via RunnableLambda to separate base64-encoded images and text (with table) elements.
- multimodal_rag: This chain is the final step which creates a RAG (Retrieval-Augmented Generation) chain, where it uses the user input and retrieved context obtained from the previous two chains, processes them using the multimodal_prompt_function we defined earlier, through a RunnableLambda, and passes the prompt to GPT-4o to generate the final response. The pipeline ensures multimodal inputs (text, tables and images) are processed by GPT-4o to give us the response.
Test the Multimodal RAG Pipeline
Everything is set up and ready to go; let’s test out our multimodal RAG pipeline!
# Run multimodal RAG chain
query = "Tell me detailed statistics of the top 5 years with largest wildfire acres
burned"
response = multimodal_rag_w_sources.invoke({'input': query})
responseOUTPUT
{'input': 'Tell me detailed statistics of the top 5 years with largest
wildfire acres burned',
'context': {'images': ('/9j/4AAQSkZJRgABAa.......30aAPda8Kn/wCPiT/eP86PPl/56v8A99GpURSgJGTQB//Z'),
'texts': ('Figure 2. Top Five Years with Largest Wildfire Acreage Burned
Since 1960\n\nTable 1. Annual Wildfires and Acres Burned',
'Source: NICC Wildland Fire Summary and Statistics annual
reports.\n\nConflagrations Of the 1.6 million wildfires that have occurred
since 2000, 254 exceeded 100,000 acres burned and 16 exceeded 500,000 acres
burned. A small fraction of wildfires become catastrophic, and a small
percentage of fires accounts for the vast majority of acres burned. For
example, about 1% of wildfires become conflagrations—raging, destructive
fires—but predicting which fires will “blow up” into conflagrations is
challenging and depends on a multitude of factors, such as weather and
geography. There have been 1,041 large or significant fires annually on
average from 2018 through 2022. In 2022, 2% of wildfires were classified as
large or significant (1,289); 45 exceeded 40,000 acres in size, and 17
exceeded 100,000 acres. For context, there were fewer large or significant
wildfires in 2021 (943)......')},
'answer': 'Based on the provided context and the image, here are the
detailed statistics for the top 5 years with the largest wildfire acres
burned:\n\n1. **2015**\n - **Acres burned:** 10.13 million\n - **Number
of fires:** 68.2 thousand\n\n2. **2020**\n - **Acres burned:** 10.12
million\n - **Number of fires:** 59.0 thousand\n\n3. **2017**\n -
**Acres burned:** 10.03 million\n - **Number of fires:** 71.5
thousand\n\n4. **2006**\n - **Acres burned:** 9.87 million\n - **Number
of fires:** 96.4 thousand\n\n5. **2007**\n - **Acres burned:** 9.33
million\n - **Number of fires:** 67.8 thousand\n\nThese statistics
highlight the years with the most significant wildfire activity in terms of
acreage burned, showing a trend of large-scale wildfires over the past few
decades.'}
Looks like we are above to get the answer as well as the source context documents used to answer the question! Let’s create a function now to format these results and display them in a better way!
def multimodal_rag_qa(query):
response = multimodal_rag_w_sources.invoke({'input': query})
print('=='*50)
print('Answer:')
display(Markdown(response('answer')))
print('--'*50)
print('Sources:')
text_sources = response('context')('texts')
img_sources = response('context')('images')
for text in text_sources:
display(Markdown(text))
print()
for img in img_sources:
plt_img_base64(img)
print()
print('=='*50)This is a simple function which just takes the dictionary output from our multimodal RAG pipeline and displays the results in a nice format. Time to put this to the test!
query = "Tell me detailed statistics of the top 5 years with largest wildfire acres
burned"
multimodal_rag_qa(query)OUTPUT
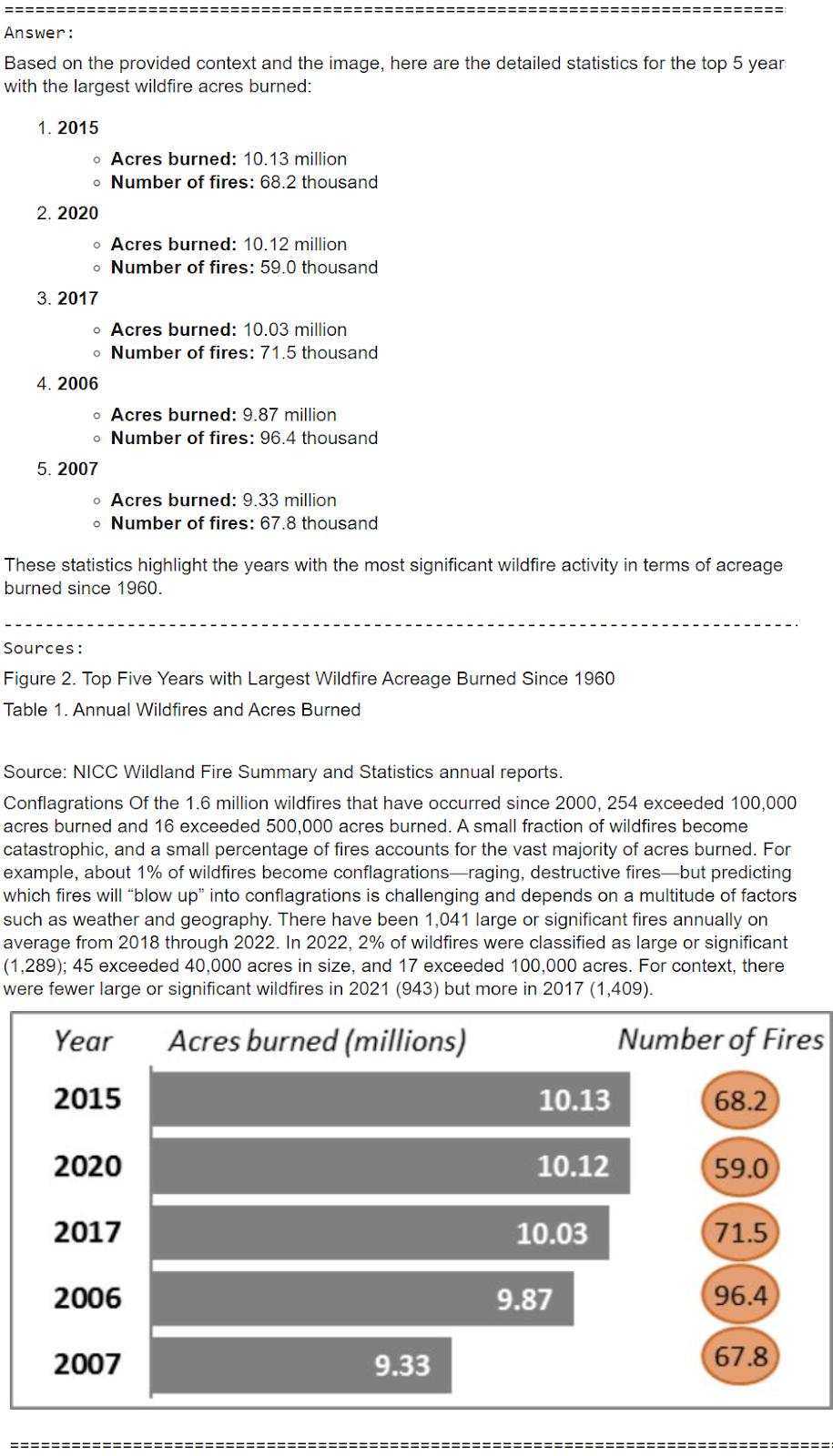
It does a pretty good job, leveraging text and image context documents here to answer the question correct;y! Let’s try another one.
# Run RAG chain
query = "Tell me about the annual wildfires trend with acres burned"
multimodal_rag_qa(query)OUTPUT
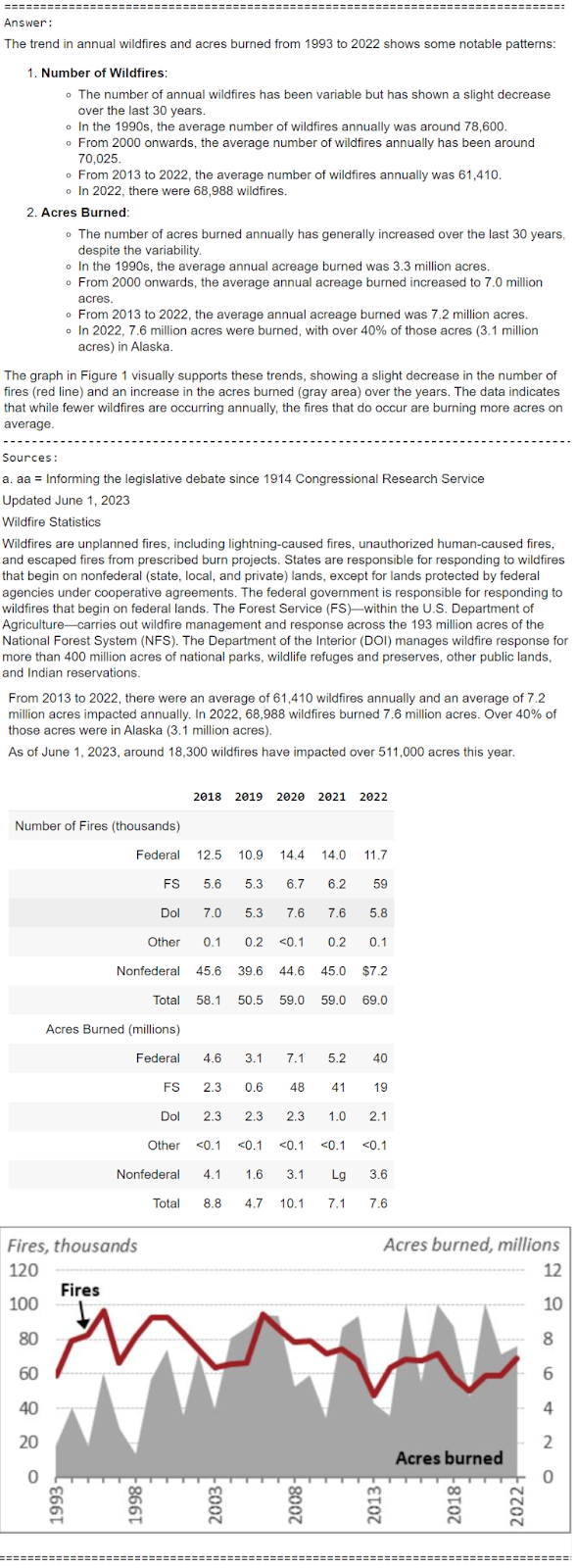
It does a pretty good job here analyzing tables, images and text context documents to answer the user question with a detailed report. Let’s look at one more example of a very specific query.
# Run RAG chain
query = "Tell me about the number of acres burned by wildfires for the forest service in 2021"
multimodal_rag_qa(query)OUTPUT
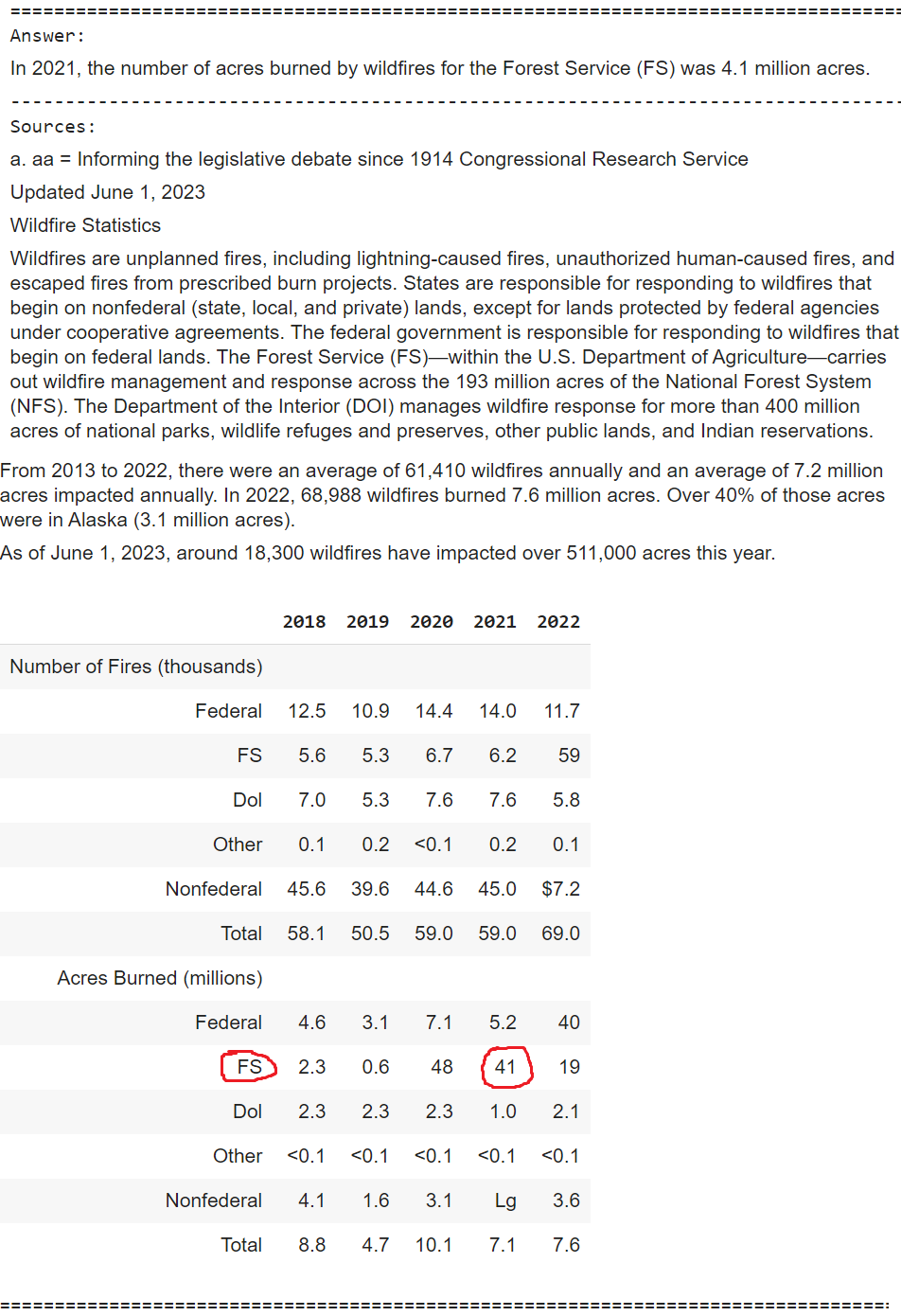
Here you can clearly see that even though the table elements were wrongly extracted for some of the rows, especially the one being used to answer the question, GPT-4o is intelligent enough to look at the surrounding table elements and the text chunks retrieved to give the right answer of 4.1 million instead of 41 million. Of course this may not always work and that is where you might need to focus on improving your extraction pipelines.
Conclusion
If you are reading this, I commend your efforts in staying right till the end in this massive guide! Here, we went through an in-depth understanding of the current challenges in traditional RAG systems especially in handling multimodal data. We then talked about what is multimodal data as well as multimodal large language models (LLMs). We discussed at length a detailed system architecture and workflow for a Multimodal RAG system with GPT-4o. Last but not the least, we implemented this Multimodal RAG system with LangChain and tested it on various scenarios. Do check out this Colab notebook for easy access to the code and try improving this system by adding more capabilities like support for audio, video and more!
Frequently Asked Questions
Ans. A Retrieval Augmented Generation (RAG) system is an ai framework that combines data retrieval with language generation, enabling more contextual and accurate responses without the need for fine-tuning large language models (LLMs).
Ans. Traditional RAG systems primarily handle text data, cannot process multimodal data (like images or tables), and are limited by the quality of the stored data in the vector database.
Ans. Multimodal data consists of multiple types of data formats such as text, images, tables, audio, video, and more, allowing ai systems to process a combination of these modalities.
Ans. A multimodal Large Language Model (LLM) is an ai model capable of processing and understanding various data types (text, images, tables) to generate relevant responses or summaries.
Ans. Some popular multimodal LLMs include GPT-4o (OpenAI), Gemini (Google), Claude (Anthropic), and open-source models like LLaVA-NeXT and Pixtral 12B.
Frequently Asked Questions
Lorem ipsum dolor sit amet, consectetur adipiscing elit,
Privacy & Cookies Policy






{kind=link}