
Data annotation is the process of labeling data available in video, text, or images. Labeled datasets are required for supervised machine learning so that machines can clearly understand the input patterns. In autonomous mobility, annotated datasets are essential for training self-driving vehicles to recognize and respond to road conditions, traffic signs, and potential hazards. In the medical field, it helps improve diagnostic accuracy, with labeled medical imaging data enabling ai systems to identify potential health issues more effectively.
This growing demand underscores the importance of high-quality data annotation in advancing ai and ML applications across diverse sectors.
In this comprehensive guide, we’ll discuss everything you need to know about data annotation. We’ll start by examining the different types of data annotation, from text and image to video and audio, and even cutting-edge techniques like LiDAR annotation. Next, we’ll compare manual vs. automated annotation and help you navigate the build vs. buy decision for annotation tools.
Furthermore, we’ll delve into data annotation for large language models (LLMs) and its role in enterprise ai adoption. We’ll also walk you through the critical steps in the annotation process and share expert tips and best practices to help you avoid common pitfalls.
What is data annotation?
Data annotation is the process of labeling and categorizing data to make it usable for machine learning models. It involves adding meaningful metadata, tags, or labels to raw data, such as text, images, videos, or audio, to help machines understand and interpret the information accurately.
The primary goal of data annotation is to create high-quality, labeled datasets that can be used to train and validate machine learning algorithms. By providing machines with annotated data, data scientists and developers can build more accurate and efficient ai models that can learn from patterns and examples in the data.
Without properly annotated data, machines would struggle to understand and make sense of the vast amounts of unstructured data generated every day.
Types of data annotation
Data annotation is a versatile process that can be applied to various data types, each with its own techniques and applications. The data annotation market is primarily segmented into two main categories: Computer Vision Type and Natural Language Processing Type.
Computer Vision annotation focuses on labeling visual data, while Natural Language Processing annotation deals with textual and audio data.
In this section, we’ll explore the most common types of data annotation and their specific use cases.
1. Text annotation: It involves labeling and categorizing textual data to help machines understand and interpret human language. Everyday text annotation tasks include:
- Sentiment annotation: Identifying and categorizing the emotions and opinions expressed in a text.
- Intent annotation: Determining the purpose or goal behind a user’s message or query.
- Semantic annotation: Linking words or phrases to their corresponding meanings or concepts.
- Named entity annotation: Identifying and classifying named entities such as people, organizations, and locations within a text.
- Relation annotation: Establishing the relationships between different entities or concepts mentioned in a text.
2. Image annotation: It involves adding meaningful labels, tags, or bounding boxes to digital images to help machines interpret and understand visual content. This annotation type is crucial for developing computer vision applications like facial recognition, object detection, and image classification.
3. Video annotation: It extends the concepts of image annotation to video data, allowing machines to understand and analyze moving visual content. This annotation type is essential for autonomous vehicles, video surveillance, and gesture recognition applications.
4. Audio annotation: It focuses on labeling and transcribing audio data, such as speech, music, and environmental sounds. This annotation type is vital for developing speech recognition systems, voice assistants, and audio classification models.
5. LiDAR annotation: Light Detection and Ranging annotation involves labeling and categorizing 3D point cloud data generated by LiDAR sensors. This annotation type is increasingly essential for autonomous driving, robotics, and 3D mapping applications.
When comparing the different types of data annotation, it’s clear that each has its own unique challenges and requirements. Text annotation relies on linguistic expertise and context understanding, while image and video annotation requires visual perception skills. Audio annotation depends on accurate transcription and sound recognition, and LiDAR annotation demands spatial reasoning and 3D understanding.
The rapid growth of the Data Annotation and Labeling Market reflects the increasing importance of data annotation in ai and ML development. According to recent market research, the global market is projected to grow from USD 0.8 billion in 2022 to USD 3.6 billion by 2027 at a compound annual growth rate (CAGR) of 33.2%. This substantial growth underscores data annotation’s critical role in training and improving ai and ML models across various industries.
Data annotation techniques can be broadly categorized into manual and automated approaches. Each has its strengths and weaknesses, and the choice often depends on the project’s specific requirements.
Manual annotation: Manual annotation involves human annotators reviewing and labeling data by hand. This approach is often more accurate and can handle complex or ambiguous cases, but it is also time-consuming and expensive. Manual annotation is particularly useful for tasks that require human judgment, such as sentiment analysis or identifying subtle nuances in images or text.
Automated annotation: Automated annotation relies on machine learning algorithms to automatically label data based on predefined rules or patterns. This method is faster and more cost-effective than manual annotation, but it may not be as accurate, particularly for edge cases or subjective tasks. Automated annotation is well-suited for large-scale projects with relatively straightforward labeling requirements.
Human-in-the-Loop (HITL) approach combines the efficiency of automated systems with human expertise and judgment. This approach is crucial for developing reliable, accurate, ethical ai and ML systems.
HITL techniques include:
- Iterative annotation: Humans annotate a small subset of data, which is then used to train an automated system. The system’s output is reviewed and corrected by humans, and the process repeats, gradually improving the model’s accuracy.
- Active learning: An intelligent system selects the most informative or challenging data samples for human annotation, optimizing the use of human effort.
- Expert guidance: Domain specialists provide clarifications and ensure annotations meet industry standards.
- Quality control and feedback: Regular human review and feedback help refine the automated annotation process and address emerging challenges.
Data annotation tools
There are plenty of data annotation tools available in the market. When selecting one, ensure that you consider features intuitive user interface, multi-format support, collaborative annotation, quality control mechanisms, ai-assisted annotation, scalability and performance, data security and privacy, and integration and API support.
Prioritizing these features allows for the selection of a data annotation tool that meets current needs and scales with future ai and ML projects.
Some of the leading commercial tools include:
- amazon SageMaker Ground Truth: A fully managed data labeling service that uses machine learning to label data automatically.
- Google Cloud Data Labeling Service: Offers a range of annotation tools for image, video, and text data.
- Labelbox: A collaborative platform supporting various data types and annotation tasks.
- Appen: Provides both manual and automated annotation services across multiple data types.
- SuperAnnotate: A comprehensive platform offering ai-assisted annotation, collaboration features, and quality control for various data types.
- Encord: End-to-end solution for developing ai systems with advanced annotation tools and model training capabilities.
- Dataloop: ai-powered platform streamlining data management, annotation, and model training with customizable workflows.
- V7: Automated annotation platform combining dataset management, image/video annotation, and autoML model training.
- Kili: Versatile labeling tool with customizable interfaces, powerful workflows, and quality control features for diverse data types.
- Nanonets: ai-based document processing platform specializing in automating data extraction with custom OCR models and pre-built solutions.
Open-source alternatives are also available, such as:
- CVAT (Computer Vision Annotation Tool): A web-based tool for annotating images and videos.
- Doccano: A text annotation tool supporting classification, sequence labeling, and named entity recognition.
- LabelMe: An image annotation tool allowing users to outline and label objects in images.
When choosing a data annotation tool, consider factors such as the type of data you’re working with, the scale of your project, your budget, and any specific requirements for integration with your existing systems.
Build vs. buy decision
Organizations must also decide whether to build their own annotation tools or purchase existing solutions. Building custom tools offers complete control over features and workflow but requires significant time and resources. Buying existing tools is often more cost-effective and allows for quicker implementation but may require compromises on customization.
Data annotation for large language models (LLMs)
Large Language Models (LLMs) have revolutionized natural language processing, enabling more sophisticated and human-like interactions with ai systems. Developing and fine-tuning these models require vast amounts of high-quality, annotated data. In this section, we’ll explore the unique challenges and techniques involved in data annotation for LLMs.
Role of RLHF (Reinforcement Learning from Human Feedback)
RLHF has emerged as a crucial technique in improving LLMs. This approach aims to align the model’s outputs with human preferences and values, making the ai system more useful and ethically aligned.
The RLHF process involves:
- Pre-training a language model on a large corpus of text data.
- Training a reward model based on human preferences.
- Fine-tuning the language model using reinforcement learning with the reward model.
Data annotation plays a vital role in the second step, where human annotators rank the language model’s results, providing feedback in the form of yes/no approval or more nuanced ratings. This process helps quantify human preferences, allowing the model to learn and align with human values and expectations.
Techniques and best practices for annotating LLM data
If the data is not annotated correctly or consistently, it may cause significant issues in model performance and reliability. To ensure high-quality annotations for LLMs, consider the following best practices:
- Diverse annotation teams: Ensure annotators come from varied backgrounds to reduce bias and improve the model’s ability to understand different perspectives and cultural contexts.
- Clear guidelines: Develop comprehensive annotation guidelines that cover a wide range of scenarios and edge cases to ensure consistency across annotators.
- Iterative refinement: Regularly review and update annotation guidelines based on emerging patterns and challenges identified during the annotation process.
- Quality control: Implement rigorous quality assurance processes, including cross-checking annotations and regular performance evaluations of annotators.
- Ethical considerations: Be mindful of the potential biases and ethical implications of annotated data, and strive to create datasets that promote fairness and inclusivity.
- Contextual understanding: Encourage annotators to consider the broader context when evaluating responses, ensuring that annotations reflect nuanced understanding rather than surface-level judgments. This approach helps LLMs develop a more sophisticated grasp of language and context.
These practices are helping LLMs show significant improvements. These models are now being applied across various fields, including chatbots, virtual assistants, content generation, sentiment analysis, and language translation. As LLMs progress, it becomes increasingly important to ensure high-quality data annotation, which presents a challenge in balancing large-scale annotation with nuanced, context-aware human judgment.
Data annotation in an enterprise context
For large organizations, data annotation is not just a task but a strategic imperative that underpins ai and machine learning initiatives. Enterprises face unique challenges and requirements when implementing data annotation at scale, necessitating a thoughtful approach to tool selection and process implementation.
Scale and complexity: Enterprises face unique challenges with data annotation due to their massive, diverse datasets. They need robust tools that can handle high volumes across various data types without compromising performance. Features like active learning, model-assisted labeling, and ai model integration are becoming crucial for managing complex enterprise data effectively.
Customization and workflow integration: One-size-fits-all solutions rarely meet enterprise needs. Organizations require highly customizable annotation tools that can adapt to specific workflows, ontologies, and data structures. Seamless integration with existing systems through well-documented APIs is crucial, allowing enterprises to incorporate annotation processes into their broader data and ai pipelines.
Quality control and consistency: To meet enterpise-level needs, you need advanced quality assurance features, including automated checks, inter-annotator agreement metrics, and customizable review workflows. These features ensure consistency and reliability in the annotated data, which is critical for training high-performance ai models.
Security and compliance: Data security is paramount for enterprises, especially those in regulated industries. Annotation tools must offer enterprise-grade security features, including encryption, access controls, and audit trails. Compliance with regulations like GDPR and HIPAA is non-negotiable, making tools with built-in compliance features highly attractive.
Implementing these strategies can help enterprises harness the power of data annotation to drive ai innovation and gain a competitive edge in their respective industries. As the ai landscape evolves, companies that excel in data annotation will be better positioned to leverage new technologies and respond to changing market demands.
How to do data annotation?
The goal of the data annotation process should be not just to label data, but to create valuable, accurate training sets that enable ai systems to perform at their best. Now each business will have unique requirements for data annotation, but there are some general steps that can guide the process:
Step 1: Data collection
Before annotation begins, you need to gather all relevant data, including images, videos, audio recordings, or text data, in one place. This step is crucial as the quality and diversity of your initial dataset will significantly impact the performance of your ai models.
Step 2: Data preprocessing
Preprocessing involves standardizing and enhancing the collected data. This step may include:
- Deskewing images
- Enhancing data quality
- Formatting text
- Transcribing video or audio content
- Removing duplicates or irrelevant data
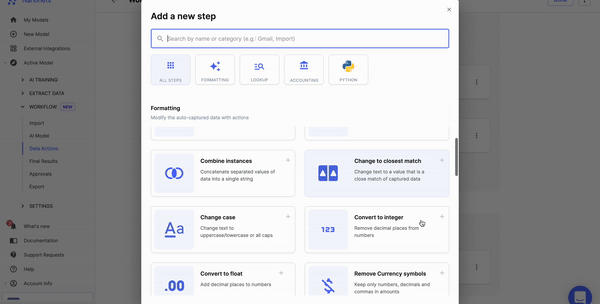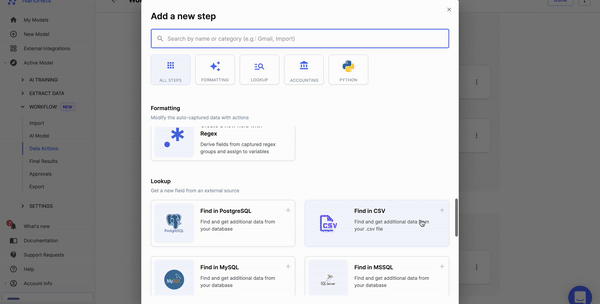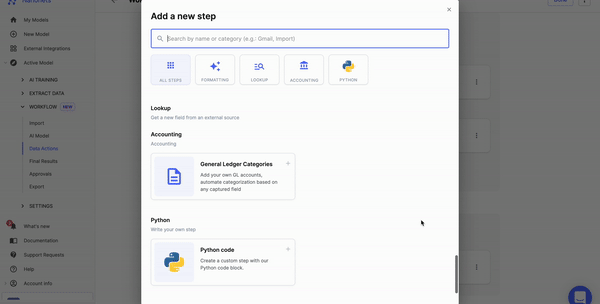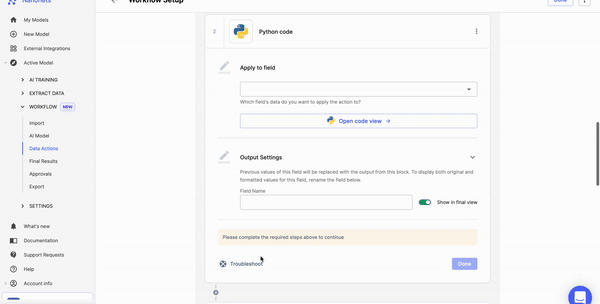
Nanonets can automate data pre-processing with no-code workflows. You can choose from a variety of options, such as date formatting, data matching, and data verification.
Step 3: Select the data annotation tool
Choose an appropriate annotation tool based on your specific requirements. Consider factors such as the type of data you’re working with, the scale of your project, and any specific annotation features you need.
Here are some options:
- Data Annotation – Nanonets
- Image Annotation – V7
- Video Annotation – Appen
- Document Annotation – Nanonets
Step 4: Establish annotation guidelines
Develop clear, comprehensive guidelines for annotators or annotation tools. These guidelines should cover:
- Definitions of labels or categories
- Examples of correct and incorrect annotations
- Instructions for handling edge cases or ambiguous data
- Ethical considerations, especially when dealing with potentially sensitive content
Step 5: Annotation
After establishing guidelines, the data can be labeled and tagged by human annotators or using data annotation software. Consider implementing a Human-in-the-Loop (HITL) approach, which combines the efficiency of automated systems with human expertise and judgment.
Step 6: Quality control
Quality assurance is crucial for maintaining high standards. Implement a robust quality control process, which may include:
- Multiple annotators reviewing the same data
- Expert review of a sample of annotations
- Automated checks for common errors or inconsistencies
- Regular updates to annotation guidelines based on quality control findings
You can perform multiple blind annotations to ensure that results are accurate.
Step 7: Data export
Once data annotation is complete and has passed quality checks, export it in the required format. You can use platforms like Nanonets to seamlessly export data in the format of your choice to 5000+ business software.
The entire data annotation process can take anywhere from a few days to several weeks, depending on the size and complexity of the data and the resources available. It’s important to note that data annotation is often an iterative process, with continuous refinement based on model performance and evolving project needs.
Real-world examples and use cases
Recent reports indicate that GPT-4, developed by OpenAI, can accurately identify and label cell types. This was achieved by analyzing marker gene data in single-cell RNA sequencing. It just goes to show how powerful ai models can become when trained on accurately annotated data.
In other industries, we see similar trends of ai augmenting human annotation efforts:
Autonomous Vehicles: Companies are using annotated video data to train self-driving cars to recognize road elements. Annotators label objects like pedestrians, traffic signs, and other vehicles in video frames. This process trains ai systems to recognize and respond to road elements.
Healthcare: Medical imaging annotation is growing in popularity for improving diagnostic accuracy. Annotated datasets are used to train ai models that can detect abnormalities in x-rays, MRIs, and CT scans. This application has the potential to enhance early disease detection and improve patient outcomes.
Natural Language Processing: Annotators label text data to help ai understand context, intent, and sentiment. This process enhances the ability of chatbots and virtual assistants to engage in more natural and helpful conversations.
Financial services: The financial industry uses data annotation to enhance fraud detection capabilities. Experts label transaction data to identify patterns associated with fraudulent activity. This helps train ai models to detect and prevent financial fraud more effectively.
These examples underscore the growing importance of high-quality annotated data across various industries. However, as we embrace these technological advancements, it’s crucial to address the ethical challenges in data annotation practices, ensuring fair compensation for annotators and maintaining data privacy and security.
Final thoughts
In the same way data continues to evolve, data annotation procedures are becoming more advanced. Just a few years ago, simply labeling a few points on a face was enough to build an ai prototype. Now, as many as twenty dots can be placed on the lips alone.
As we look to the future, we can expect even more precise and detailed annotation techniques to emerge. These advancements will likely lead to ai models with unprecedented accuracy and capabilities. However, this progress also brings new challenges, such as the need for more skilled annotators and increased computational resources.
If you are on the lookout for a simple and reliable data annotation solution, consider exploring Nanonets. Schedule a demo to see how Nanonets can streamline your data annotation process. Learn how the platform automates data extraction from documents and annotates documents easily to automate any document tasks.






{kind=link}