 NEWSLETTER
NEWSLETTER

Image generated with the Segmind SSD-1B model
When you analyze data with Pandas, you'll use Pandas functions to filter and transform columns, join data from multiple data frames, and the like.
But it can often be useful to generate graphs (to visualize the data in the data frame) instead of just looking at the numbers.
Pandas has several plot functions that you can use for quick and easy data visualization. And we will go over them in this tutorial.
Link to Google Colab notebook (if you want to encode).
Let's create a sample data frame for analysis. We will create a data frame called df_employees containing employee records.
we will use faker and the NumPy random module to fill the data frame with 200 records.
Note: If you don't have Faker installed in your development environment, you can install it using pip: pip install Faker.
Run the following snippet to create and complete df_employees with records:
import pandas as pd
from faker import Faker
import numpy as np
# Instantiate Faker object
fake = Faker()
Faker.seed(27)
# Create a DataFrame for employees
num_employees = 200
departments = ('Engineering', 'Finance', 'HR', 'Marketing', 'Sales', 'IT')
years_with_company = np.random.randint(1, 10, size=num_employees)
salary = 40000 + 2000 * years_with_company * np.random.randn()
employee_data = {
'EmployeeID': np.arange(1, num_employees + 1),
'FirstName': (fake.first_name() for _ in range(num_employees)),
'LastName': (fake.last_name() for _ in range(num_employees)),
'Age': np.random.randint(22, 60, size=num_employees),
'Department': (fake.random_element(departments) for _ in range(num_employees)),
'Salary': np.round(salary),
'YearsWithCompany': years_with_company
}
df_employees = pd.DataFrame(employee_data)
# Display the head of the DataFrame
df_employees.head(10)We have laid the seed of reproducibility. So every time you run this code you will get the same logs.
Here are the first data frame view records:
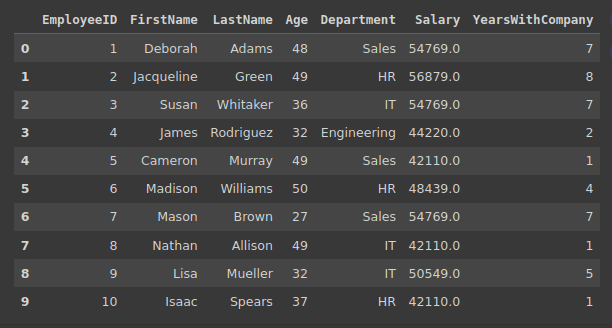
Output of df_employees.head(10)
Scatter plots are generally used to understand the relationship between any two variables in the data set.
For him df_employees data frame, let's create a scatterplot to visualize the relationship between employee age and salary. This will help us understand if there is any correlation between the ages of employees and their salaries.
To create a scatterplot, we can use plot.scatter() like:
# Scatter Plot: Age vs Salary
df_employees.plot.scatter(x='Age', y='Salary', title="Scatter Plot: Age vs Salary", xlabel="Age", ylabel="Salary", grid=True)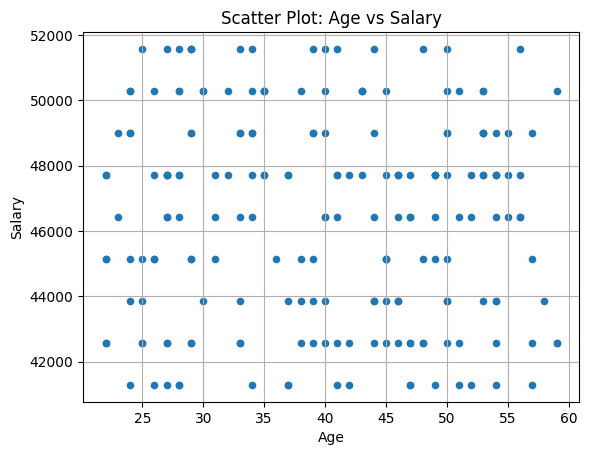
For this example data frame, we don't see any correlation between employee age and salaries.
A line chart is suitable for identifying trends and patterns in a continuous variable which is usually time or a similar scale.
When creating the df_employees data frame, we had defined a linear relationship between the number of years an employee has worked at the company and their salary. So let's look at the line graph that shows how average salaries vary with the number of years.
We find the average salary grouped by years at the company and then create a line graph with plot.line():
# Line Plot: Average Salary Trend Over Years of Experience
average_salary_by_experience = df_employees.groupby('YearsWithCompany')('Salary').mean()
df_employees('AverageSalaryByExperience') = df_employees('YearsWithCompany').map(average_salary_by_experience)
df_employees.plot.line(x='YearsWithCompany', y='AverageSalaryByExperience', marker="o", linestyle="-", title="Average Salary Trend Over Years of Experience", xlabel="Years With Company", ylabel="Average Salary", legend=False, grid=True)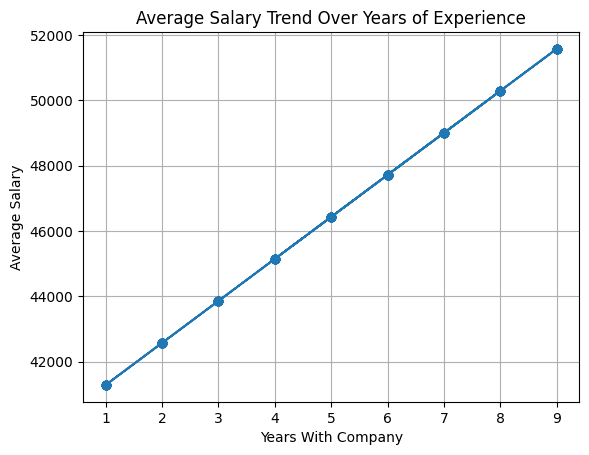
Because we chose to populate the salary field using a linear relationship with the number of years an employee has worked at the company, we see that the line chart reflects that.
You can use histograms to visualize the distribution of continuous variables (dividing the values into intervals or bins) and displaying the number of data points in each bin.
Let's understand the age distribution of employees using a histogram using plot.hist() as shown:
# Histogram: Distribution of Ages
df_employees('Age').plot.hist(title="Age Distribution", bins=15)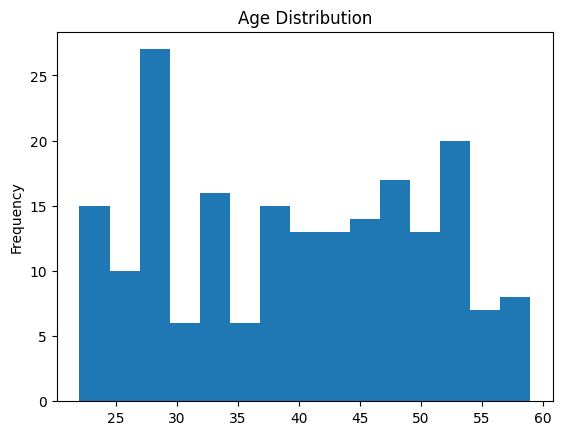
A boxplot is useful for understanding the distribution of a variable, its extent, and for identifying outliers.
Let's create a boxplot to compare the salary distribution between different departments, providing a high-level comparison of the salary distribution within the organization.
The boxplot will also help identify the salary range, as well as useful information such as the average salary and possible outliers for each department.
Here we use boxplot from the 'Salary' column grouped by 'Department':
# Box Plot: Salary distribution by Department
df_employees.boxplot(column='Salary', by='Department', grid=True, vert=False)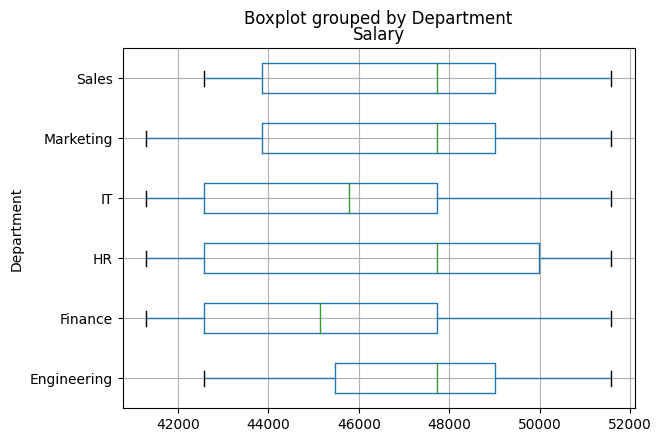
In the boxplot we see that some departments have a greater distribution of salaries than others.
When you want to understand the distribution of variables in terms of frequency of occurrence, you can use a bar chart.
Now let's create a bar chart using plot.bar() To view the number of employees:
# Bar Plot: Department-wise employee count
df_employees('Department').value_counts().plot.bar(title="Employee Count by Department")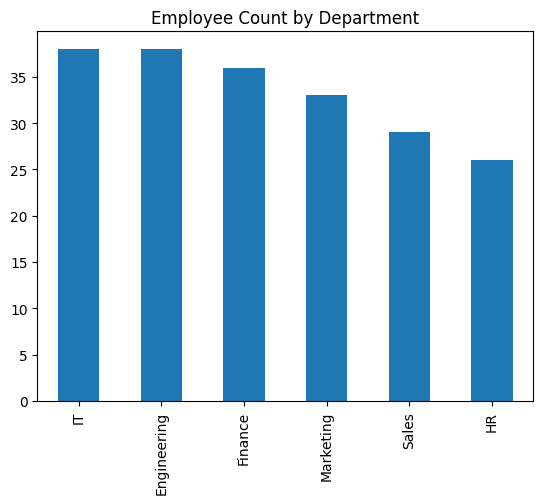
Area charts are generally used to display the cumulative distribution of a variable on the continuous or categorical axis.
For the employee data frame, we can plot the cumulative salary distribution in different age groups. To assign employees into containers based on age group, we use pd.cut().
Then we find the cumulative sum of salaries by grouping the salary by 'Age Group'. To obtain the area graph, we use plot.area():
# Area Plot: Cumulative Salary Distribution Over Age Groups
df_employees('AgeGroup') = pd.cut(df_employees('Age'), bins=(20, 30, 40, 50, 60), labels=('20-29', '30-39', '40-49', '50-59'))
cumulative_salary_by_age_group = df_employees.groupby('AgeGroup')('Salary').cumsum()
df_employees('CumulativeSalaryByAgeGroup') = cumulative_salary_by_age_group
df_employees.plot.area(x='AgeGroup', y='CumulativeSalaryByAgeGroup', title="Cumulative Salary Distribution Over Age Groups", xlabel="Age Group", ylabel="Cumulative Salary", legend=False, grid=True)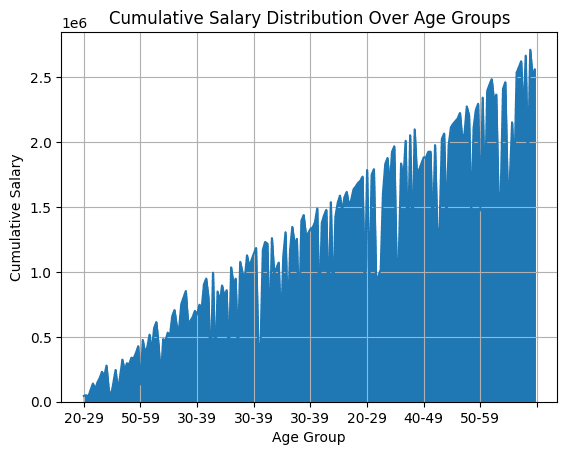
Pie charts are useful when you want to visualize the proportion of each of the categories within a whole.
For our example, it makes sense to create a pie chart that shows the distribution of salaries between departments in the organization.
We find the total salary of employees grouped by department. and then use plot.pie() To plot the pie chart:
# Pie Chart: Department-wise Salary distribution
df_employees.groupby('Department')('Salary').sum().plot.pie(title="Department-wise Salary Distribution", autopct="%1.1f%%")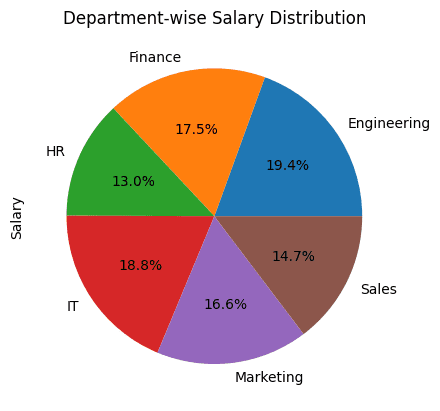
I hope you found some useful plot functions that you can use in pandas.
Yes, you can generate much nicer plots with matplotlib and seaborn. But for quick data visualization, these features can be very useful.
What are some of the other pandas plotting functions you use frequently? Let us know in the comments.
Bala Priya C. is a developer and technical writer from India. He enjoys working at the intersection of mathematics, programming, data science, and content creation. His areas of interest and expertise include DevOps, data science, and natural language processing. He likes to read, write, code and drink coffee! Currently, he is working to learn and share his knowledge with the developer community by creating tutorials, how-to guides, opinion pieces, and more.






{kind=link}