
Image by author
In the ever-evolving technology landscape, the emergence of large language models (LLMs) has been nothing short of a revolution. Tools like ChatGPT and Google BARD are at the forefront and show the art of the possible in digital interaction and application development.
The success of models like ChatGPT has led to a surge in interest from companies eager to leverage the capabilities of these advanced language models.
However, the true power of LLMs does not lie solely in their independent skills.
Their potential is amplified when integrated with additional computational resources and knowledge bases, creating applications that are not only intelligent and linguistically adept, but also richly informed by data and processing power.
And this integration is exactly what LangChain is trying to evaluate.
Langchain is an innovative framework designed to unleash the full capabilities of LLMs, enabling fluid symbiosis with other systems and resources. It is a tool that gives data professionals the keys to building applications that are as intelligent as they are contextually aware, taking advantage of the vast sea of information and computational variety available today.
It is not just a tool, it is a transformative force that is reshaping the technological landscape.
This raises the following question:
How will LangChain redefine the boundaries of what LLMs can achieve?
Stay with me and let’s try to discover it all together.
LangChain is an open source framework built around LLM. It provides developers with an arsenal of tools, components, and interfaces that streamline the architecture of LLM-based applications.
However, it is not just another tool.
Working with LLM can sometimes feel like trying to fit a square peg into a round hole.
There are some common problems that I bet most of you have already experienced:
- How to standardize notice structures.
- How to ensure that other modules or libraries can use the output of LLM.
- How to easily switch from one LLM model to another.
- How to keep some memory record when necessary.
- How to deal with data.
All these problems lead us to the following question:
How to develop a completely complex application while ensuring that the LLM model will behave as expected.
The prompts are riddled with repetitive structures and text, the answers are as unstructured as a toddler’s playroom, and the memory of these models? Let’s say it’s not exactly an elephant.
So… how can we work with them?
Trying to develop complex applications with ai and LLM can be a complete headache.
And this is where LangChain steps in as a problem solver.
At its core, LangChain is made up of several nifty components that allow you to easily integrate LLM into any development.
LangChain is generating excitement for its ability to amplify the capabilities of powerful large language models by endowing them with memory and context. This addition allows the simulation of “reasoning” processes, allowing more complex tasks to be tackled with greater precision.
For developers, LangChain’s appeal lies in its innovative approach to creating user interfaces. Instead of relying on traditional methods like drag and drop or coding, users can articulate their needs directly and the interface is designed to accommodate those requests.
It is a framework designed to empower software developers and data engineers with the ability to seamlessly integrate LLMs into their applications and data workflows.
So this brings us to the next question…
Knowing that current LLMs present 6 main problems, we can now see how LangChain is trying to evaluate them.
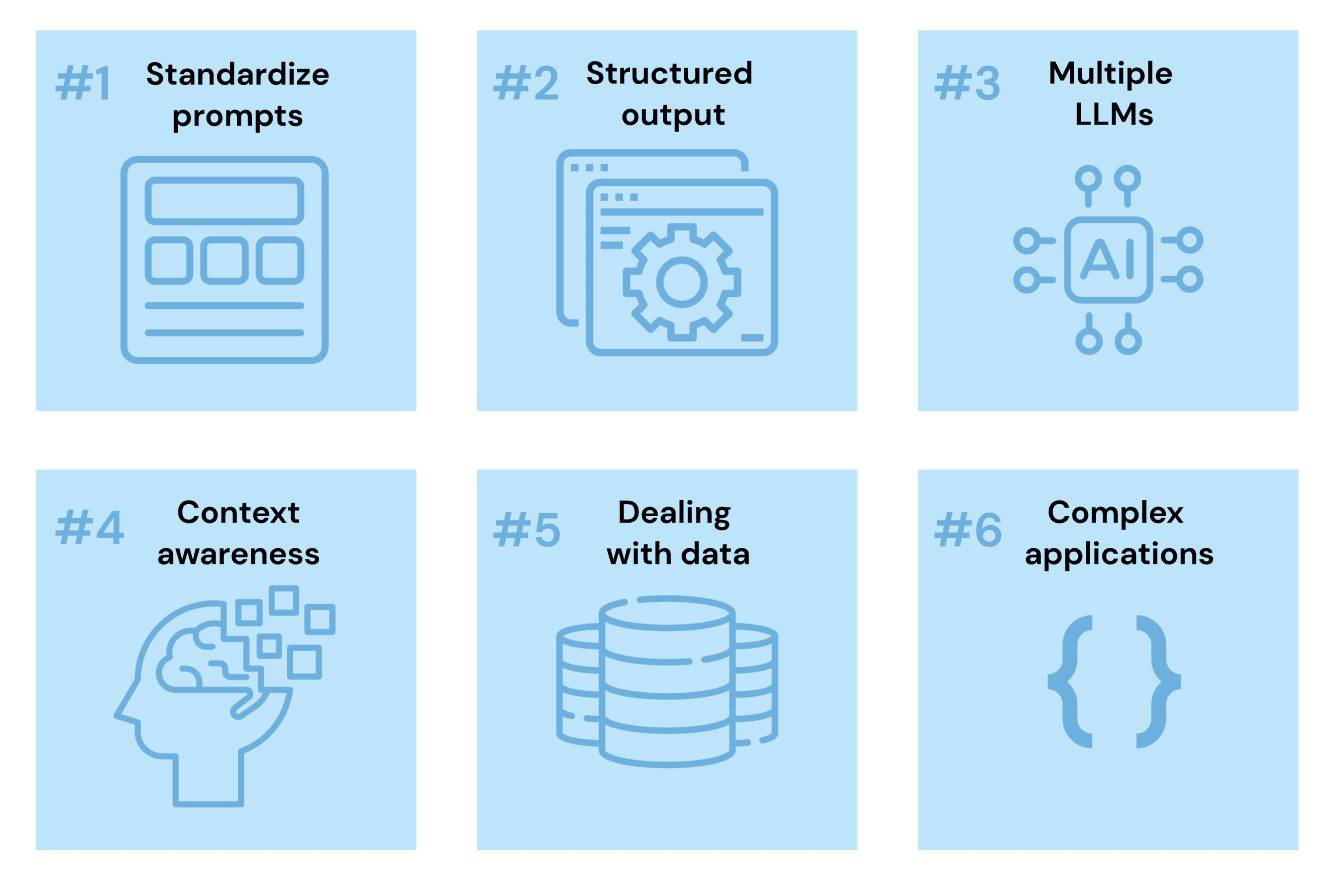
Image by author
1. The prompts are too complex now
Let’s try to remember how quickly the concept of notice has evolved over the past few months.
It all started with a simple string that described an easy task to perform:
Hey ChatGPT, can you please explain to me how to plot a scatter chart in Python?However, over time people realized that this was too simple. We were not providing LLMs with enough context to understand their primary task.
Nowadays we need to tell any LLM much more than simply describing the main task to be fulfilled. We have to describe the high-level behavior of the ai, the writing style, and include instructions to make sure the answer is accurate. And any other details to give a more contextualized instruction to our model.
So today, instead of using the first message, we’ll send something more similar to:
Hey ChatGPT, imagine you are a data scientist. You are good at analyzing data and visualizing it using Python.
Can you please explain to me how to generate a scatter chart using the Seaborn library in PythonGood?
However, as most of you may have already realized, I can ask for a different task but still maintain the same high-level behavior of the LLM. This means that most parts of the message can remain the same.
That’s why we should be able to write this part just once and then add it to any message you need.
LangChain solves this text repetition problem by offering prompt templates.
These templates combine the specific details you need for your task (asking for exactly the scatterplot) with the usual text (such as describing the high-level behavior of the model).
So our final message template would be:
Hey ChatGPT, imagine you are a data scientist. You are good at analyzing data and visualizing it using Python.
Can you please explain to me how to generate a using the library in Python?With two main input variables:
- chart type
- python library
2. Responses are unstructured in nature
Humans interpret text easily. That’s why when we chat with any ai-powered chatbot like ChatGPT, we can easily handle plain text.
However, when these same ai algorithms are used for applications or programs, these responses must be provided in an established format, such as CSV or JSON files.
Again, we can try to craft sophisticated prompts that ask for specific structured results. But we cannot be 100% sure that this result will be generated in a structure that is useful to us.
This is where LangChain’s output parsers come into play.
This class allows us to parse any LLM response and generate a structured variable that can be easily used. Forget asking ChatGPT to respond to you in a JSON, LangChain now allows you to parse its output and generate your own JSON.
3. LLMs do not have memory, but some applications may require it.
Now imagine that you are talking to a company’s Q&A chatbot. You send a detailed description of what you need, the chatbot responds correctly and after a second iteration… everything disappears!
This is pretty much what happens when calling any LLM via API. When using GPT or any other UI chatbot, the ai model forgets any part of the conversation the moment we move on to the next turn.
They don’t have much or any memory.
And this can lead to confusing or wrong answers.
As most of you may have already guessed, LangChain is once again ready to help us.
LangChain offers a class called memory. It allows us to keep the model context-aware, either keeping the entire chat history or just a summary so you don’t get incorrect responses.
4. Why choose just one LLM when you can have them all?
We all know that OpenAI GPT models are still in the realm of LLMs. However… There are many other options, such as the open source models Llama, Claude or Meta’s Hugging Face Hub.
If you only design your program for a company’s language model, you’ll be stuck with their tools and rules.
Using the native API of a single model directly makes you completely dependent on them.
Imagine if you built your app’s ai functions with GPT, but then discovered that you needed to incorporate a function that is best evaluated using Meta’s Llama.
You will be forced to start from scratch… which is not a good thing.
LangChain offers something called LLM class. Think of it as a special tool that makes it easy to switch from one language model to another, or even use multiple models at once in your application.
That’s why developing directly with LangChain allows you to consider multiple models at once.
5. Passing data to the LLM is complicated
Language models like GPT-4 are trained on large volumes of text. That’s why they work with text by nature. However, they often have difficulties when working with data.
Because? You could ask.
Two main issues can be differentiated:
- When we work with data, we must first know how to store it and how to effectively select the data we want to display to the model. LangChain helps with this problem by using something called indexes. These allow you to bring in data from different places, such as databases or spreadsheets, and configure it so that it is ready to be sent to the ai piece by piece.
- On the other hand, we must decide how to put that data in the message that it gives to the model. The easiest way is to just put all the data directly into the message, but there are smarter ways to do it as well.
In this second case, LangChain has some special tools that use different methods to provide data to the ai. Whether using direct message padding, which allows you to put the entire data set directly into the message, or using more advanced options like Map-reduce, Refine or Map-rerank, LangChain makes it easy for us to send data to any LLM. .
6. Standardization of development interfaces
It is always difficult to adapt LLMs to larger systems or workflows. For example, you may need to get information from a database, give it to the ai, and then use the ai‘s response elsewhere in your system.
LangChain has special features for these types of setups.
- Chains are like threads that join different steps into a simple, straight line.
- Agents are smarter and can make decisions about what to do next based on what the ai says.
LangChain also simplifies this by providing standardized interfaces that streamline the development process, making it easier to integrate and chain calls to LLM and other utilities, improving the overall development experience.
At its core, LangChain offers a set of tools and features that facilitate application development with LLM by addressing the complexities of rapid elaboration, response structuring, and model integration.
LangChain is more than just a framework, it is a game changer in the world of data engineering and LLMs.
It is the bridge between the complex and often chaotic world of ai and the structured and systematic approach needed in data applications.
As we conclude this exploration, one thing is clear:
LangChain is not only shaping the future of LLMs, it is also shaping the future of technology itself.
Joseph Ferrer He is an analytical engineer from Barcelona. He graduated in physical engineering and currently works in the field of Data Science applied to human mobility. He is a part-time content creator focused on data science and technology. You can contact him at LinkedIn, Twitter either Half.






{kind=link}