 NEWSLETTER
NEWSLETTER
*Equal taxpayers
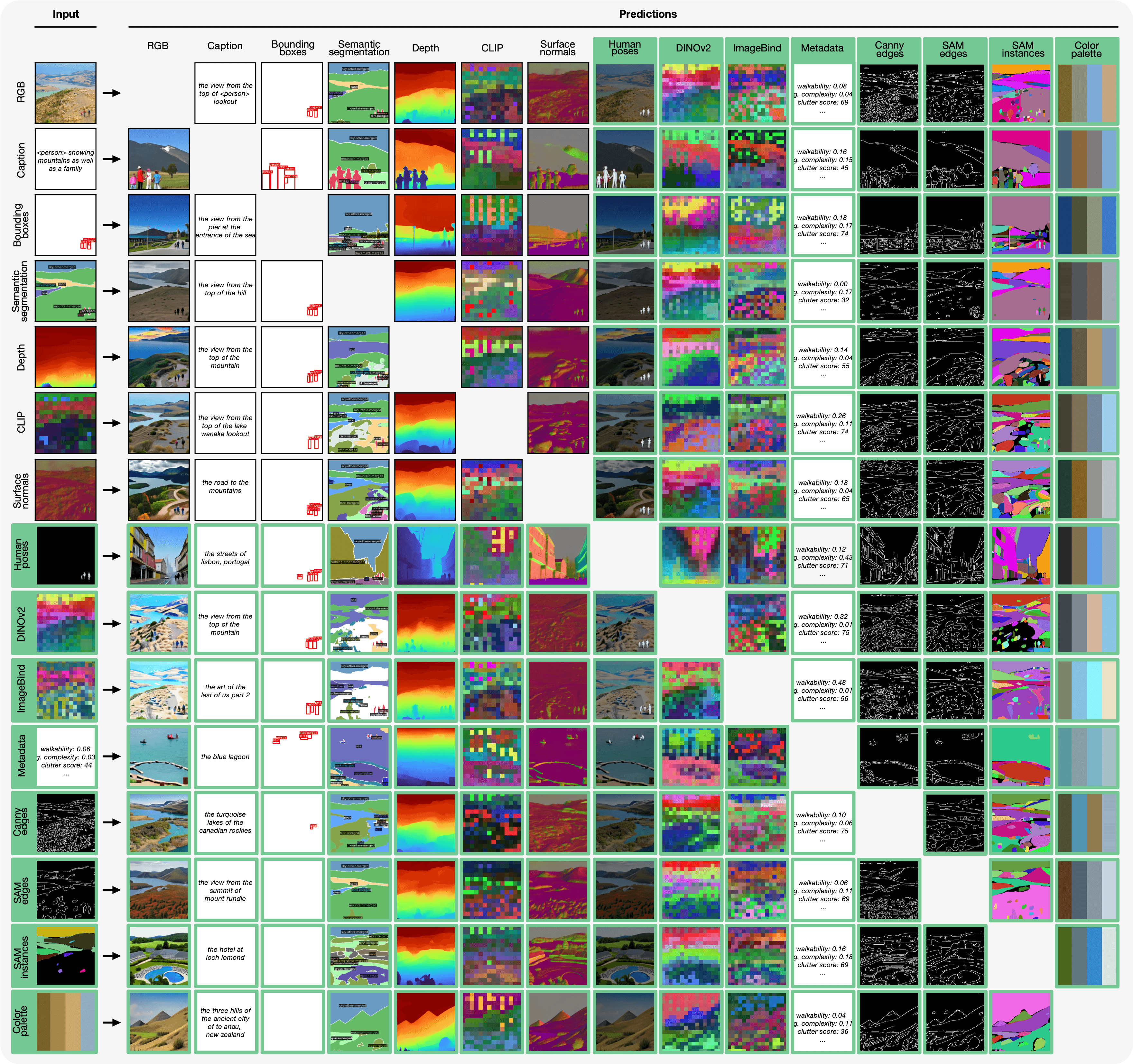
Current basic multimodal and multitasking models, such as 4M or UnifiedIO, show promising results, but in practice their innovative capabilities to accept various inputs and perform various tasks are limited by the (usually quite small) number of modalities and tasks they perform. trained in. In this paper, we significantly expand the capabilities of 4M by training it on dozens of highly diverse modalities and performing co-training on multimodal datasets and large-scale text corpora. This includes training on various semantic and geometric modalities, feature maps from recent state-of-the-art models such as DINOv2 and ImageBind, pseudotags from specialized models such as SAM and 4DHumans, and a variety of new modalities that enable novel ways to interact with the model. and direct the generation of, for example, image metadata or color palettes.
A crucial step in this process is to perform tokenization in various modalities, whether image-like neural network feature maps, vectors, structured data such as instance segmentation or human poses, or data that can be represented as text.
Through this, we can expand the out-of-the-box capabilities of multimodal models. This enables more detailed and controllable multimodal generation capabilities and allows us to study the distillation of models trained on various data and targets into a unified model. We successfully scaled training to a three billion parameter model using dozens of modalities and different data sets, observing promising scaling trends.



{kind=link}