

Image by author
Quite a bold statement! Claiming that I can guarantee someone that you will get a job, of course.
Okay, the truth is that nothing in life is guaranteed, especially finding a job. Not even in data science. But what will get you very close to the guarantee is having data projects in your portfolio.
Why do I think projects are so decisive? Because, if chosen wisely, they more effectively showcase the breadth and depth of your technical data science skills. What counts is the quality of the projects, not their number. They should cover as many data science skills as possible.
So which projects guarantee you that in the fewest number of projects? If I limited myself to only doing three projects, I would select these.
But don’t take it too literally. The message here is not that you should stick strictly to those three. I selected them because they cover most of the technical skills required in data science. If you want to do other data science projects, feel free to do so. But if you have limited time or a limited number of projects, choose them wisely and select those that will test the widest range of data science skills.
Speaking of which, let’s be clear about what they are.
There are five fundamental skills in data science.
- Piton
- Data dispute
- Statistic analysis
- Machine learning
- Data visualization
This is a checklist to consider when trying to get the most out of the data science projects you choose.
Below is an overview of what these skills encompass.
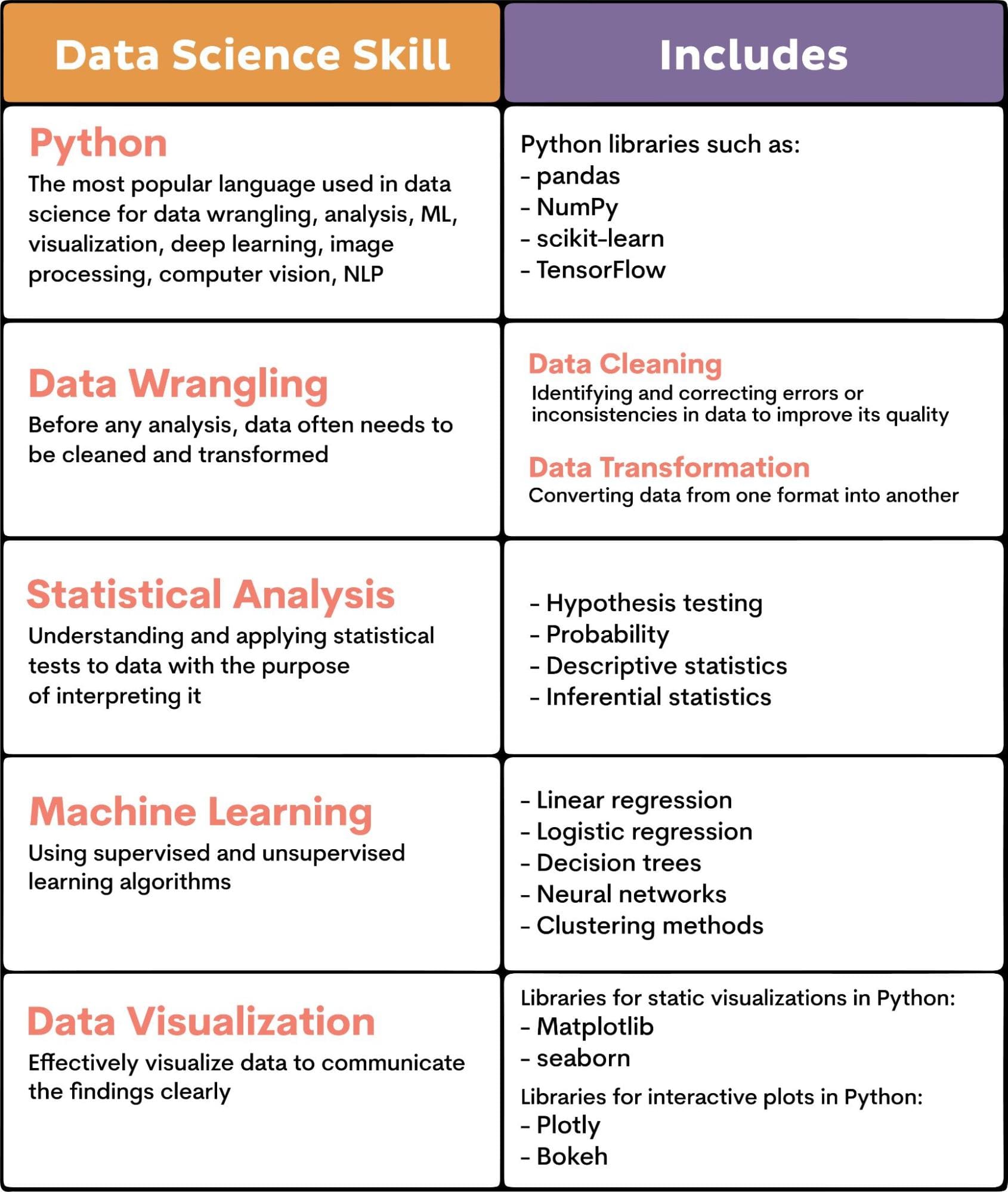
Of course, there is much more to data science skills. They also include knowledge of SQL and R, big data technologies, deep learning, natural language processing, and cloud computing.
However, the need for them depends largely on the job description. But you can’t do without the five fundamental skills I mentioned.
Let’s now look at how the three data science projects I chose challenge these skills.
Some of these projects may be too advanced for some. In that case, give them these 19 data science projects for beginners a try.
1. Understanding city supply and demand: business analysis
Fountain: Insights into city supply and demand data
Issue: Business analysis
Short description: Cities are centers of supply and demand interactions for Uber. Analyzing them can offer information about the company’s business and planning. Uber gives you a data set with details about the trips. You must answer eleven questions to provide business insight into trips, their time, demand for drivers, etc.
Project execution: You will receive eleven questions that must be answered in the order shown. Answering them will involve tasks such as
- Filling in the missing values,
- Adding data,
- Find the largest values,
- Analysis time interval,
- Calculate percentages,
- Calculate weighted averages,
- Find differences,
- Data visualization, etc.
Skills displayed: Exploratory Data Analysis (EDA) to select necessary columns and fill in missing values, obtain useful information about completed trips (different periods, weighted average proportion of trips per driver, find busiest hours to help draft a driver schedule , the relationship between supply and demand, etc.), visualizing the relationship between supply and demand.
2. Predicting customer churn: a classification task
Fountain: Customer churn prediction
Issue: Supervised learning (classification)
Short description: In this data science project, Sony Research provides you with a set of data from a telecom company’s customers. They expect you to perform exploratory analysis and extract information. Next, you’ll need to create a churn prediction model, evaluate it, and discuss issues when deploying the model to production.
Project execution: The project must be approached in these large phases.
- Exploratory analysis and knowledge extraction
-
- Verify data fundamentals (null, uniqueness)
- Choose the data you need and form your data set
- View data to check the distribution of values.
- Form a correlation matrix
- Check the importance of features
-
- Wear learned split the data set into training and testing using the ratio of 80% to 20%
-
- Apply classifiers and choose one to use in production based on performance.
-
- Use precision and F1 score when comparing the performance of different algorithms
-
- Use classic machine learning models
- Visualize the decision tree and see how tree-based algorithms work
-
- Try artificial neural network (ANN) to solve this problem
-
- Monitor model performance to prevent data drift and concept drift.
Skills displayed: Exploratory data analysis (EDA) and data manipulation to check for nulls, uniqueness of data, gain insights into data distribution, positive and negative correlations; visualization of data in histograms and correlation matrix; apply ML classifiers using the sklearn library, measure the accuracy of the algorithms and F1 score, compare the algorithms and visualize the decision tree; use artificial neural networks to see how deep learning works; Implementation of models where it is necessary to be aware of data and concept drift problems in the MLOps cycle.
3. Predictive policing: examining the implications
Fountain: The dangers of predictive policing
Issue: Supervised learning (regression)
Short description: This predictive policing uses algorithms and data analysis to predict where crimes are likely to occur. The approach you choose can have profound ethical and social implications. Uses 2016 San Francisco city crime data from your open data initiative. The project will attempt to predict the number of crime incidents in a given zip code on a given day of the week and time of day.
Project execution: Below are the main steps that the author of the project has undertaken.
- Select the variables and calculate the total number of crimes per year per zip code per hour
- Train/test data split chronologically
- Testing five regression algorithms:
-
- Linear regression
- Random forest
- K-nearest neighbors
- XGBoost
- Multilayer perceptron
Skills displayed: Exploratory data analysis (EDA) and data discussion where you end up with data on crimes, time, day of the week and zip code; ML (supervised learning/regression) where the performance of linear regression, random forest regressor, K-nearest neighbor and XGBoost are tested; deep learning in which a multilayer perceptron is used to try to explain the results obtained; gain insights into crime prediction and its potential for misuse; Implementation of the model in an interactive map.
If you want to do more projects using similar skills, here are 30+ ML project ideas.
By completing these data science projects, you will test and acquire essential data science skills such as data manipulation, data visualization, statistical analysis, building and deploying machine learning models.
Speaking of ML, I focused here on supervised learning as it is most commonly used in data science. I can almost guarantee you that these data science projects will be enough to get you the job you want.
But you should read the job description carefully. If you see that you require unsupervised learning, NLP, or something else that I didn’t cover here, include one or two such projects in your portfolio.
No matter what, you’re still not stuck with just three projects. They are here to guide you on how to choose. his projects that will guarantee you get a job. Consider the complexity of the projects, as they should broadly cover fundamental data science skills.
Now go get that job!
Nate Rosidi He is a data scientist and in product strategy. He is also an adjunct professor of analysis and is the founder of StrataScratch, a platform that helps data scientists prepare for their interviews with real questions from top companies. Connect with him on Twitter: StrataScratch either LinkedIn.






{kind=link}