 NEWSLETTER
NEWSLETTER
Data science has emerged as one of the most impactful fields in technology, transforming industries and driving innovation across the globe. Python, a versatile and powerful programming language renowned for its simplicity and extensive ecosystem, is at the heart of this revolution. Python’s dominance in the data science landscape is largely attributed to its rich library collection that caters to every stage of the data science workflow, from data manipulation and data visualization to machine learning and deep learning.
This article will explore the top 20 Python libraries indispensable for data science professionals and enthusiasts. Whether you’re cleaning datasets, building predictive models, or visualizing results, these libraries provide the tools to streamline your processes and achieve outstanding results. Let’s dive into the world of Python libraries that are shaping the future of data science!

Python has become the leading language in the data science domain and is a top priority for recruiters seeking data science professionals. Its consistent ranking at the top of global data science surveys and ever-growing popularity underscore its importance in the field. But the question is
Why is Python so Popular among Data Scientists?
Just as the human body relies on various organs for specific functions and the heart to keep everything running, Python is the foundation with its simple, object-oriented, high-level language—acting as the “heart.” Complementing this core are numerous specialized Python libraries, or “organs,” designed to tackle specific tasks such as mathematics, data mining, data exploration, and visualization.
In this article, we will explore essential Python libraries for data science. These libraries will enhance your skills and help you prepare for interviews, resolve doubts, and achieve your career goals in data science.
Numpy
NumPy (Numerical Python) is a powerful Python library used for numerical computing. It supports working with arrays (both one-dimensional and multi-dimensional) and matrices, along with various mathematical functions, to operate on these data structures.
Key Features
- N-dimensional array object (ndarray): Efficient storage and operations for large data arrays.
- Broadcasting: Perform operations between arrays of different shapes.
- Mathematical and Statistical Functions: Offers a wide range of functions for computations.
- Integration with Other Libraries: Seamless integration with libraries like Pandas, SciPy, Matplotlib, and TensorFlow.
- Performance: Highly optimized, written in C for speed, and supports vectorized operations.
Advantages of NumPy
- Efficiency: NumPy is faster than traditional Python lists due to its optimized C-based backend and support for vectorization.
- Convenience: Easy manipulation of large datasets with a simple syntax for indexing, slicing, and broadcasting.
- Memory Optimization: Consumes less memory than Python lists because of fixed data types.
- Interoperability: Easily works with other libraries and file formats, making it ideal for scientific computing.
- Built-in Functions: This program provides many mathematical and logical operations, such as linear algebra, random sampling, and Fourier transforms.
Disadvantages of NumPy
- Learning Curve: Understanding the differences between NumPy arrays and Python lists can be challenging for beginners.
- Lack of High-Level Abstraction: While it excels in array manipulation, it lacks advanced functionalities for specialized tasks compared to libraries like Pandas.
- Error Handling: Errors due to mismatched shapes or incompatible data types can be tricky for new users.
- Requires Understanding of Broadcasting: Effective usage often depends on understanding NumPy’s broadcasting rules, which might be non-intuitive.
Applications of NumPy
- Scientific Computing: Widely used for performing mathematical and statistical operations in research and data analysis.
- Data Processing: Essential for preprocessing data in machine learning and deep learning workflows.
- Image Processing: Useful for manipulating and analyzing pixel data.
- Finance: Helps in numerical computations like portfolio analysis, risk management, and financial modelling.
- Engineering and Physics Simulations: Facilitates solving differential equations, performing matrix operations, and simulating physical systems.
- Big Data: Powers efficient numerical calculations for handling large-scale datasets.
import numpy as np
# Creating arrays
array = np.array((1, 2, 3, 4, 5))
print("Array:", array)
# Perform mathematical operations
squared = array ** 2
print("Squared:", squared)
# Creating a 2D array and computing mean
matrix = np.array(((1, 2), (3, 4)))
print("Mean:", np.mean(matrix))
Pandas
Pandas is a powerful and flexible Python library for data manipulation, analysis, and visualization. It provides data structures like Series (1D) and DataFrame (2D) for effectively handling and analyzing structured data. This Python library for data science is built on top of NumPy and is extensively used in machine learning, and statistical analysis.
Key Features
- Data Structures: Series (1D) and DataFrame (2D) for handling structured data.
- Series: One-dimensional labelled array.
- DataFrame: Two-dimensional table with labelled axes (rows and columns).
- Data Handling: Efficiently handles missing data and supports various file formats (CSV, Excel, SQL, JSON, etc.).
- Indexing: Provides advanced indexing for data selection and manipulation.
- Integration: Works seamlessly with NumPy, Matplotlib, and other libraries.
- Operations: Built-in functions for grouping, merging, reshaping, and aggregating data.
Advantages of Pandas
- Ease of Use: Simple and intuitive syntax for handling and analyzing structured data.
- Versatility: Handles diverse data types, including numerical, categorical, and time-series data.
- Efficient Data Manipulation: Offers powerful functions for filtering, sorting, grouping, and reshaping datasets.
- File Format Support: It reads and writes data in various formats, such as CSV, Excel, HDF5, and SQL databases.
- Data Cleaning: Tools for handling missing data, duplicates, and transformations.
- Integration: Easily integrates with other Python libraries for advanced data analysis and visualization.
Disadvantages of Pandas
- Performance with Large Data: Large datasets are handled less efficiently than tools like Dask or PySpark.
- Memory Usage: High memory consumption for in-memory data processing.
- Complex Syntax for Large Data Operations: Advanced operations can require complex syntax, which might be challenging for beginners.
- Single-threaded by Default: Pandas operations are generally single-threaded, which can limit performance for large-scale data.
Applications of Pandas
- Data Analysis and Exploration: Used extensively for data wrangling, summarization, and exploratory data analysis (EDA).
- Time Series Analysis: Ideal for analyzing time-indexed data, such as stock prices or weather data.
- Financial Analysis: Perform moving averages, rolling statistics, and economic modelling calculations.
- Machine Learning: Used for preprocessing datasets, feature engineering, and preparing data for ML models.
- Data Cleaning and Transformation: Automates tasks like handling missing values, normalization, and reformatting.
- Database Operations: Acts as an intermediary between databases and Python for reading/writing SQL data.
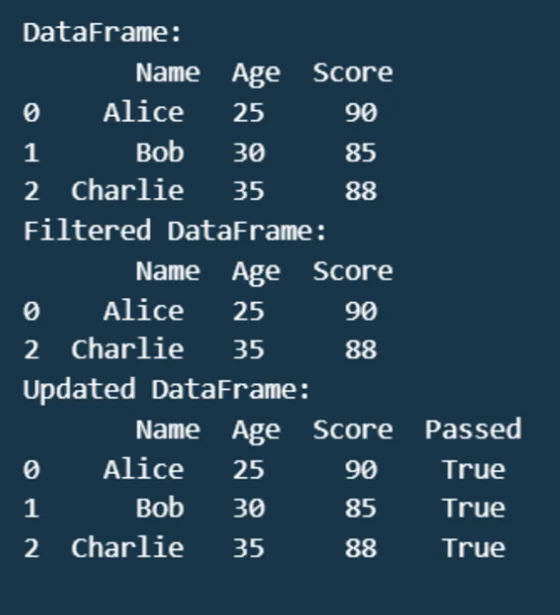
import pandas as pd
# Creating a DataFrame
data = {'Name': ('Alice', 'Bob', 'Charlie'),
'Age': (25, 30, 35),
'Score': (90, 85, 88)}
df = pd.DataFrame(data)
print("DataFrame:\n", df)
# Filtering rows
filtered = df(df('Score') > 85)
print("Filtered DataFrame:\n", filtered)
# Adding a new column
df('Passed') = df('Score') > 80
print("Updated DataFrame:\n", df)
Matplotlib
Matplotlib is a popular Python library for creating static, animated, and interactive visualizations. It provides a flexible platform for generating plots, charts, and other graphical representations. Designed with simplicity in mind, Matplotlib is highly customizable and integrates seamlessly with other Python libraries like NumPy and Pandas.
Key Features
- 2D Plotting: This Python library for data science creates line plots, bar charts, scatter plots, histograms, and more.
- Interactive and Static Plots: Generate static images and interactive visualizations with zooming, panning, and tooltips.
- Customization: Extensive support for customizing plots, including colours, labels, markers, and annotations.
- Multiple Output Formats: You can export plots to various file formats, such as PNG, PDF, and SVG.
- Integration: Works well with Jupyter Notebooks and other data analysis libraries.
Advantages of Matplotlib
- Versatility: Supports a wide range of plot types, making it suitable for diverse visualization needs.
- Customizability: Offers fine-grained control over every aspect of a plot, including axes, grids, and legends.
- Integration: Works seamlessly with libraries like NumPy, Pandas, and SciPy for plotting data directly from arrays or DataFrames.
- Wide Adoption: Extensive documentation and a large community ensure resources for learning and troubleshooting.
- Extensibility: Built to support advanced custom visualizations through its object-oriented API.
Disadvantages of Matplotlib
- Complexity for Beginners: The initial learning curve can be steep, especially when using its object-oriented interface.
- Verbosity: Often requires more lines of code compared to higher-level visualization libraries like Seaborn.
- Limited Aesthetic Appeal: Out-of-the-box visualizations may lack the polished look of libraries like Seaborn or Plotly.
- Performance Issues: It may be slower when handling large datasets or creating highly interactive visualizations than modern libraries.
Applications of Matplotlib
- Data Visualization: Used extensively to visualize trends, distributions, and relationships in data analysis workflows.
- Exploratory Data Analysis (EDA): Helps analysts understand data by creating scatter plots, histograms, and box plots.
- Scientific Research: Common in research papers and presentations for plotting experimental results.
- Financial Analysis: Ideal for visualizing stock trends, financial forecasts, and other time-series data.
- Machine Learning and ai: Used to track model performance with metrics like loss curves and confusion matrices.
- Education: Famous for teaching concepts of data visualization and statistics.
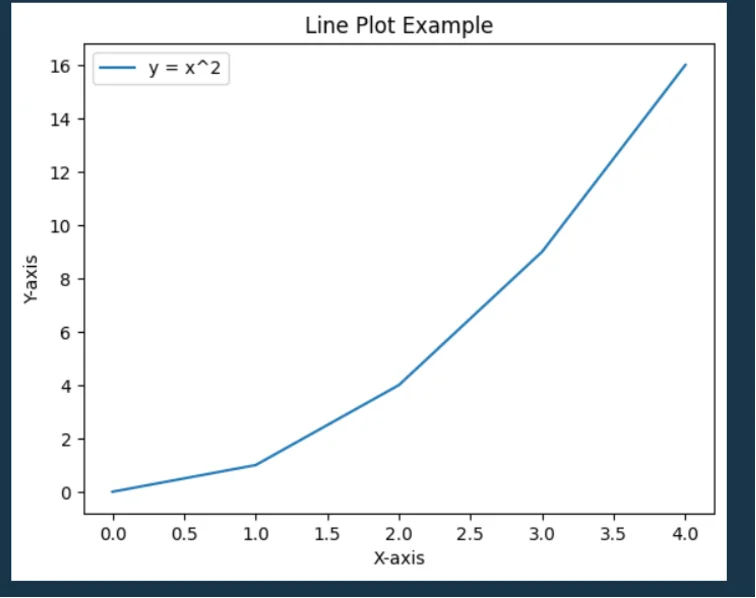
import matplotlib.pyplot as plt
# Basic line plot
x = (0, 1, 2, 3, 4)
y = (0, 1, 4, 9, 16)
plt.plot(x, y, label="y = x^2")
# Adding labels and title
plt.xlabel("x-axis")
plt.ylabel("Y-axis")
plt.title("Line Plot Example")
plt.legend()
plt.show()
Seaborn
Seaborn is a Python data visualization library built on top of Matplotlib. It is designed to create aesthetically pleasing and informative statistical graphics. Seaborn provides a high-level interface for creating complex visualizations, making analysing and presenting data insights easy.
Key Features
- High-level API: Simplifies the process of generating visualizations with less code.
- Built-in Themes: Provides attractive and customizable styles for visualizations.
- Integration with Pandas: Works seamlessly with Pandas DataFrames, making it easy to visualize structured data.
- Statistical Visualization: Includes functions for creating regression plots, distribution plots, and heat maps
Advantages of Seaborn
- Ease of Use: Simplifies complex visualizations with concise syntax and intelligent defaults.
- Enhanced Aesthetics: Automatically applies beautiful themes, colour palettes, and styles to plots.
- Integration with Pandas: This Python library for data science makes creating plots directly from Pandas DataFrames straightforwardly.
- Statistical Insights: Offers built-in support for statistical plots like box, violin, and pair plots.
- Customizability: While high-level, it allows customization and works well with Matplotlib for fine-tuning.
- Support for Multiple Visualizations: This allows complex relationships between variables to be visualized, such as faceted grids and categorical plots.
Disadvantages of Seaborn
- Dependency on Matplotlib: Seaborn relies heavily on Matplotlib, sometimes making debugging and customization more cumbersome.
- Limited Interactivity: Unlike libraries like Plotly, Seaborn focuses on static visualizations and lacks interactive capabilities.
- Steeper Learning Curve: Understanding advanced features like faceted grids or statistical parameter settings can be challenging for beginners.
- Performance on Large Datasets: Visualization of massive datasets can be slower than other libraries optimized for performance.
Applications of Seaborn
- Exploratory Data Analysis (EDA): Visualizing distributions, correlations, and relationships between variables to uncover patterns.
- Statistical Analysis: Creating regression plots, box plots, and violin plots to analyze trends and variability in data.
- Feature Engineering: Identifying outliers, analyzing feature distributions, and understanding variable interactions.
- Heatmaps for Correlation Analysis: Visualizing correlation matrices to identify relationships between numerical variables.
- Categorical Data Visualization: Creating bar plots, count plots, and swarm plots for analyzing categorical variables.
- Research and Presentation: Creating publication-quality plots with minimal effort.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# Sample dataset
df = sns.load_dataset("iris")
# Scatter plot with linear fit
sns.lmplot(data=df, x="sepal_length", y="sepal_width", hue="species")
plt.title("Sepal Length vs Width")
plt.show()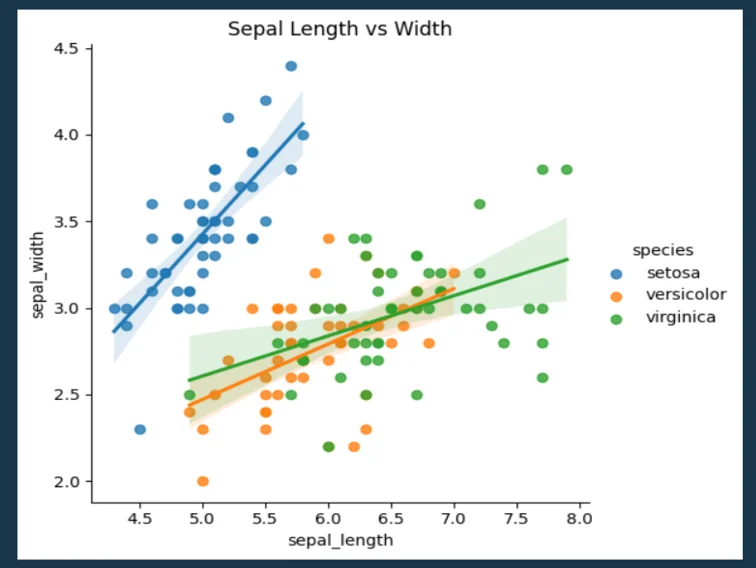
Also Read: How to Plot Heatmaps in Seaborn?
Scikit-Learn
Scikit-learn is a popular open-source Python library built on NumPy, SciPy, and Matplotlib. It provides a comprehensive set of machine learning tools, including algorithms for classification, regression, clustering, dimensionality reduction, and preprocessing. Its simplicity and efficiency make it a preferred choice for beginners and professionals working on small—to medium-scale machine learning projects.
Key Features
- Wide Range of ML Algorithms: This Python library for data science includes algorithms like linear regression, SVM, K-means, random forests, etc.
- Data Preprocessing: Functions for handling missing values, scaling features, and encoding categorical variables.
- Model Evaluation: Tools for cross-validation, metrics like accuracy, precision, recall, and ROC-AUC.
- Pipeline Creation: Enables chaining of preprocessing steps and model building for streamlined workflows.
- Integration: Seamlessly integrates with Python libraries like NumPy, Pandas, and Matplotlib.
Advantages of Scikit-learn
- Ease of Use: Simple, consistent, and user-friendly APIs make it accessible for beginners.
- Comprehensive Documentation: Detailed documentation and a wealth of tutorials help in learning and troubleshooting.
- Wide Applicability: Covers most standard machine learning tasks, from supervised to unsupervised learning.
- Built-in Model Evaluation: Facilitates robust evaluation of models using cross-validation and metrics.
- Scalability for Prototyping: Ideal for quick prototyping and experimentation due to its optimized implementations.
- Active Community: Backed by a large and active community for support and continuous improvements.
Disadvantages of Scikit-learn
- Limited Deep Learning Support: Does not support deep learning models; frameworks like TensorFlow or PyTorch are required.
- Scalability Limitations: Not optimized for handling massive datasets or distributed systems.
- Lack of Real-Time Capabilities: NIt is not designed for real-time applications like streaming data analysis.
- Dependency on NumPy/SciPy: Knowing these libraries is required for efficient use.
- Limited Customization: Customizing algorithms beyond basic parameters can be challenging.
Applications of Scikit-learn
- Predictive Analytics: Used in applications like sales forecasting, customer churn prediction, and fraud detection.
- Classification Problems: Spam email detection, sentiment analysis, and image classification.
- Regression Problems: Predicting house prices, stock prices, and other continuous outcomes.
- Clustering and Dimensionality Reduction: Market segmentation, document clustering, and feature extraction (e.g., PCA).
- Preprocessing Pipelines: Automating data cleaning and transformation tasks for better machine learning workflows.
- Educational Purposes: Used extensively in academic and online courses for teaching machine learning concepts.
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load the California Housing dataset
data = fetch_california_housing()
x = data.data # Features
y = data.target # Target variable (median house value)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# Fit a linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print("Mean Squared Error:", mse)

Tensorflow
TensorFlow is an open-source library developed by Google for machine learning and deep learning. It is widely used for building and deploying machine learning models, ranging from simple linear regression to advanced deep neural networks. TensorFlow is famous for its scalability, allowing developers to train and deploy models on various platforms, from edge devices to cloud-based servers.
Key Features
- Computation Graphs: Uses dataflow graphs for numerical computation, enabling optimization and visualization.
- Scalability: Supports deployment on various platforms, including mobile devices (TensorFlow Lite) and browsers (TensorFlow.js).
- Keras Integration: Provides a high-level API, Keras, for building and training models with less complexity.
- Broad Ecosystem: Offers tools like TensorBoard for visualization, TensorFlow Hub for pre-trained models, and TensorFlow Extended (TFX) for production workflows.
- Support for Multiple Languages: Primarily Python, but APIs exist for C++, Java, and others.
Advantages of TensorFlow
- Flexibility: Allows both low-level operations and high-level APIs for different expertise levels.
- Scalability: It can handle large datasets and models and supports distributed training across GPUs, TPUs, and clusters.
- Visualization: TensorBoard provides detailed visualization of computation graphs and metrics during training.
- Pre-Trained Models and Transfer Learning: TensorFlow Hub offers pre-trained models that can be fine-tuned for specific tasks.
- Active Community and Support: Backed by Google, TensorFlow has a large community and excellent documentation.
- Cross-Platform Support: Models can be deployed on mobile (TensorFlow Lite), web (TensorFlow.js), or cloud services.
Disadvantages of TensorFlow
- Steep Learning Curve: Beginners might find TensorFlow challenging due to its complexity, especially with low-level APIs.
- Verbose Syntax: CensorFlow’s syntax can be less intuitive than other frameworks like PyTorch.
- Debugging Challenges: Debugging can be difficult, especially when working with large computation graphs.
- Resource Intensive: Requires powerful hardware for efficient training and inference, especially for deep learning tasks.
Applications of TensorFlow
- Deep Learning: This Python library for data science is used to design neural networks for image recognition, natural language processing (NLP), and speech recognition.
- Recommender Systems: Powers personalized recommendations in e-commerce and streaming platforms.
- Time-Series Forecasting: Applied in predicting stock prices, weather, and sales trends.
- Healthcare: Enables medical imaging analysis, drug discovery, and predictive analytics.
- Autonomous Vehicles: It helps with real-time object detection and path planning.
- Robotics: TensorFlow supports reinforcement learning to teach robots complex tasks.
- Natural Language Processing: Used for tasks like sentiment analysis, translation, and chatbots.
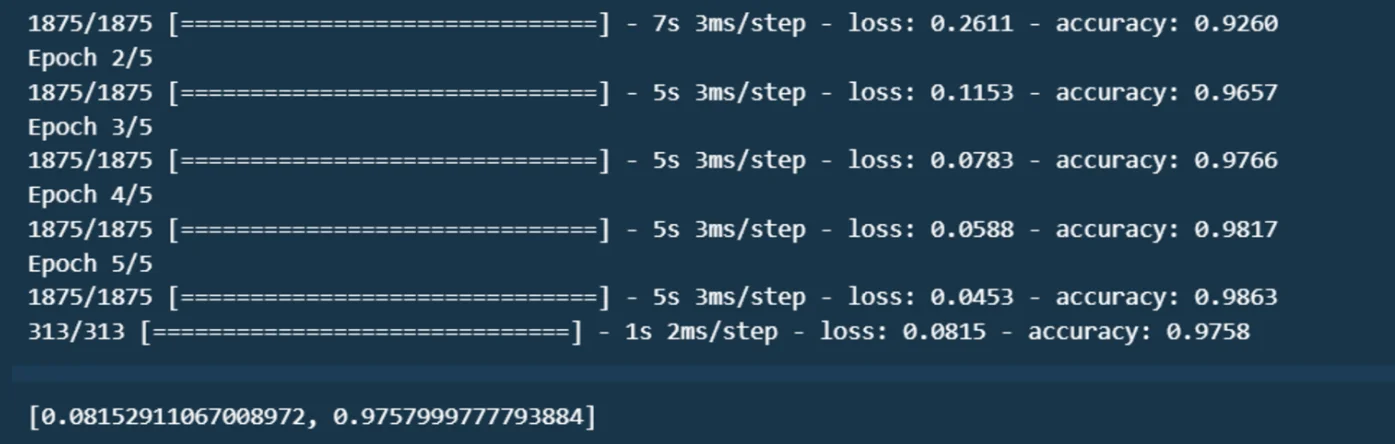
import tensorflow as tf
from tensorflow.keras import layers, models
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Build a Sequential model
model = models.Sequential((
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
))
# Compile the model
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=('accuracy'))
# Train the model
model.fit(x_train, y_train, epochs=5)
# Evaluate the model
model.evaluate(x_test, y_test)
Pytorch
PyTorch is an open-source machine learning library developed by facebook ai Research. It is widely used for developing deep learning models and performing research in artificial intelligence (ai). Known for its dynamic computation graph and Pythonic design, PyTorch provides flexibility and ease of use for implementing and experimenting with neural networks.
Key Features
- Dynamic Computation Graph: This Python library for data science builds computation graphs on the fly, allowing real-time modifications during execution.
- Tensor Computation: Supports multi-dimensional tensors with GPU acceleration.
- Autograd Module: Automatic differentiation for easy gradient computation.
- Extensive Neural Network APIs: Provides tools to build, train, and deploy deep learning models.
- Community Support: A vibrant and growing community with numerous resources, libraries, and extensions like torchvision for vision tasks.
Advantages of PyTorch
- Ease of Use: Pythonic interface makes it intuitive for beginners and flexible for experts.
- Dynamic Computation Graphs: Allows dynamic changes to the model, enabling experimentation and debugging.
- GPU Acceleration: Seamless integration with GPUs for faster training and computation.
- Extensive Ecosystem: Includes libraries for computer vision (torchvision), NLP (torchtext), and more.
- Active Community and Industry Adoption: Backed by facebook, it’s widely used in academia and industry for state-of-the-art research.
- Integration with Libraries: Works well with NumPy, SciPy, and deep learning frameworks like Hugging Face Transformers.
Disadvantages of PyTorch
- Steep Learning Curve: Beginners might find advanced topics like custom layers and backpropagation challenging.
- Lacks Built-in Production Tools: Compared to TensorFlow, production-oriented tools like TensorFlow Serving or TensorFlow Lite are less mature.
- Less Support for Mobile: Though improving, PyTorch’s mobile support is not as robust as TensorFlow.
- Memory Consumption: Dynamic computation graphs can sometimes lead to higher memory usage than static ones.
Applications of PyTorch
- Deep Learning Research: Famous for implementing and testing new architectures in academic and industrial research.
- Computer Vision: Used for image classification, object detection, and segmentation tasks with tools like torchvision.
- Natural Language Processing (NLP): Powers models for sentiment analysis, machine translation, and text generation, often in conjunction with libraries like Hugging Face.
- Reinforcement Learning: Supports frameworks like PyTorch RL for training agents in dynamic environments.
- Generative Models: Widely used for building GANs (Generative Adversarial Networks) and autoencoders.
- Financial Modeling: Applied in time-series prediction and risk management tasks.
- Healthcare: Helps create disease detection, drug discovery, and medical image analysis. models
import torch
import torch.nn as nn
import torch.optim as optim
# Define the Neural Network class
class SimpleNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNN, self).__init__()
# Define layers
self.hidden = nn.Linear(input_size, hidden_size) # Hidden layer
self.output = nn.Linear(hidden_size, output_size) # Output layer
self.relu = nn.ReLU() # Activation function
def forward(self, x):
# Define forward pass
x = self.relu(self.hidden(x)) # Apply ReLU to the hidden layer
x = self.output(x) # Output layer
return x
# Define network parameters
input_size = 10 # Number of input features
hidden_size = 20 # Number of neurons in the hidden layer
output_size = 1 # Number of output features (e.g., 1 for regression, or number of classes for classification)
# Create an instance of the network
model = SimpleNN(input_size, hidden_size, output_size)
# Define a loss function and an optimizer
criterion = nn.MSELoss() # Mean Squared Error for regression
optimizer = optim.SGD(model.parameters(), lr=0.01) # Stochastic Gradient Descent
# Example input data (10 features) and target
x = torch.randn(5, input_size) # Batch size of 5, 10 input features
y = torch.randn(5, output_size) # Corresponding targets
# Training loop (1 epoch for simplicity)
for epoch in range(1): # Use more epochs for actual training
optimizer.zero_grad() # Zero the gradients
outputs = model(x) # Forward pass
loss = criterion(outputs, y) # Compute the loss
loss.backward() # Backward pass
optimizer.step() # Update weights
print(f"Epoch ({epoch+1}), Loss: {loss.item():.4f}"
Keras
Keras is a high-level, open-source neural network library written in Python. It provides a user-friendly interface for building and training deep learning models. Keras acts as an abstraction layer, running on top of low-level libraries like TensorFlow, Theano, or Microsoft Cognitive Toolkit (CNTK). This Python library for data science is known for its simplicity and modularity, making it ideal for both beginners and experts in deep learning.
Key Features
- User-Friendly: Intuitive APIs for quickly building and training models.
- Modularity: Easy-to-use building blocks for neural networks, such as layers, optimizers, and loss functions.
- Extensibility: Allows custom additions to suit specific research needs.
- Backend Agnostic: Compatible with multiple deep learning backends (mainly TensorFlow in recent versions).
- Pre-trained Models: Includes pre-trained models for transfer learning, like VGG, ResNet, and Inception.
- Multi-GPU and TPU Support: Scalable across different hardware architectures.
Advantages of Keras
- Ease of Use: Simple syntax and high-level APIs make it easy for beginners to get started with deep learning.
- Rapid Prototyping: Enables fast development and experimentation with minimal code.
- Comprehensive Documentation: Offers detailed tutorials and guides for various tasks.
- Integration with TensorFlow: Fully integrated into TensorFlow, giving access to both high-level and low-level functionalities.
- Wide Community Support: Backed by a large community and corporate support (e.g., Google).
- Built-in Preprocessing: Provides tools for image, text, and sequence data preprocessing.
- Pre-trained Models: Simplifies transfer learning and fine-tuning for tasks like image and text classification.
Disadvantages of Keras
- Limited Flexibility: The high-level abstraction may restrict advanced users who require fine-tuned model control.
- Dependency on Backend: Performance and compatibility depend on the backend (primarily TensorFlow).
- Debugging Challenges: Abstract layers can make debugging more complex for custom implementations.
- Performance Trade-offs: Slightly slower compared to low-level frameworks like PyTorch due to its high-level nature.
Applications of Keras
- Image Processing: Used in tasks like image classification, object detection, and segmentation with Convolutional Neural Networks (CNNs).
- Natural Language Processing (NLP): Powers models for text classification, sentiment analysis, machine translation, and language generation.
- Time Series Analysis: Applied in predictive analytics and forecasting using Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks.
- Recommendation Systems: Builds collaborative filtering and deep learning-based recommendation engines.
- Generative Models: Enables generating Generative Adversarial Networks (GANs) for tasks like image synthesis.
- Healthcare: Supports medical image analysis, drug discovery, and disease prediction models.
- Finance: Used for fraud detection, stock price prediction, and risk modelling
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.datasets import mnist
from keras.utils import to_categorical
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
# Build a model
model = Sequential((
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
))
# Compile and train the model
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=('accuracy'))
model.fit(x_train, y_train, epochs=5)
# Evaluate the model
model.evaluate(x_test, y_test)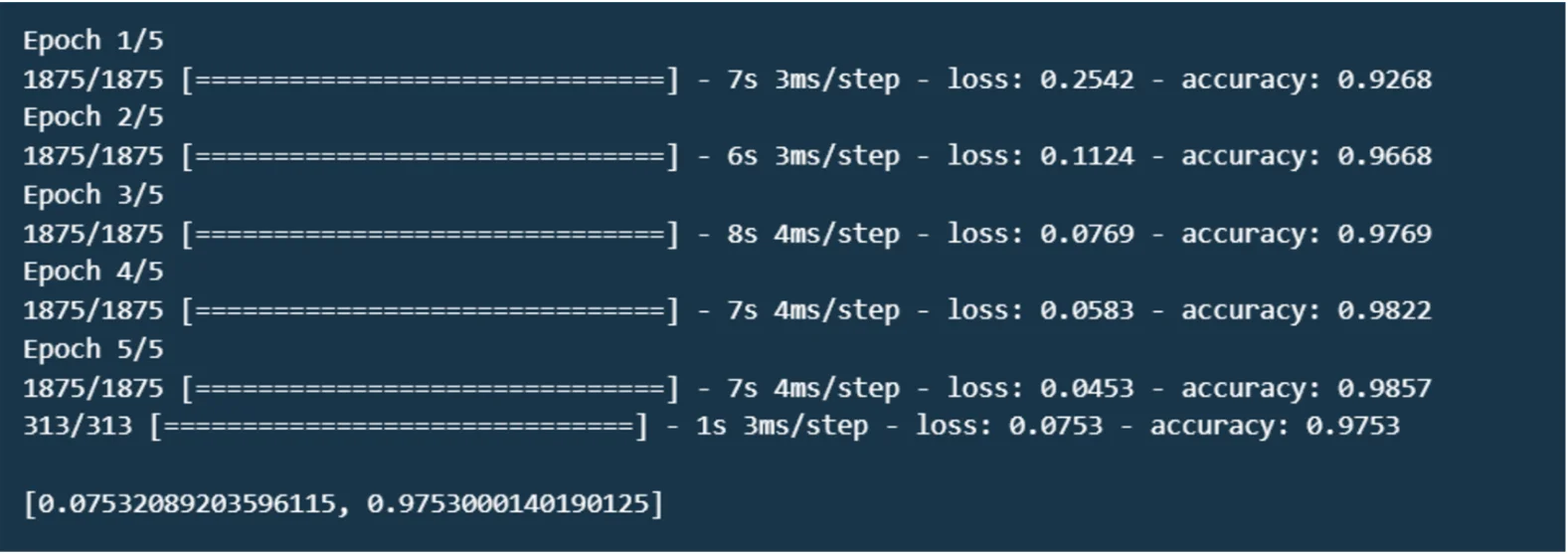
Scipy
SciPy (Scientific Python) is a Python-based library that builds upon NumPy and provides additional scientific and technical computing functionality. It includes modules for optimization, integration, interpolation, eigenvalue problems, algebraic equations, statistics, and more. SciPy is widely used for scientific and engineering tasks, offering a comprehensive suite of tools for advanced computations.
Key Features
- Optimization: Tools for finding minima and maxima of functions and solving constrained and unconstrained optimization problems.
- Integration and Differentiation: This Python library for data science functions for numerical integration and solving ordinary differential equations (ODEs).
- Linear Algebra: Advanced tools for solving linear systems, eigenvalue problems, and performing matrix operations.
- Statistics: A broad set of statistical functions, including probability distributions and hypothesis testing.
- Signal and Image Processing: Modules for Fourier transforms, image filtering, and signal analysis.
- Sparse Matrices: Efficient operations on sparse matrices for large-scale problems.
Advantages of SciPy
- Comprehensive Functionality: Extends NumPy’s capabilities with specialised scientific computing tools.
- Performance: Written in C, Fortran, and C++, providing high computational efficiency.
- Open Source: Freely available and supported by a large community of developers and users.
- Wide Application Areas: Offers tools suitable for physics, biology, engineering, and statistics, among other domains.
- Integration with Other Libraries: Seamlessly integrates with NumPy, Matplotlib, Pandas, and other Python scientific libraries.
Disadvantages of SciPy
- Steep Learning Curve: The library is extensive, and understanding all its modules can be challenging for new users.
- Dependency on NumPy: Requires a solid understanding of NumPy for practical usage.
- Limited High-Level Abstractions: Lacks features like dataframes (provided by Pandas) and specific domain functionalities.
- Size and Complexity: A large codebase and extensive functionalities can make debugging difficult.
Applications of SciPy
- Optimization Problems: Solving problems like minimizing production costs or maximizing efficiency.
- Numerical Integration: Calculating definite integrals and solving ODEs in engineering and physics.
- Signal Processing: Analyzing and filtering signals in communication systems.
- Statistical Analysis: Performing advanced statistical tests and working with probability distributions.
- Image Processing: Enhancing images, edge detection, and working with Fourier transformations for images.
- Engineering Simulations: Used in solving problems in thermodynamics, fluid dynamics, and mechanical systems.
- Machine Learning and Data Science: Supporting preprocessing steps like interpolation, curve fitting, and feature scaling.
from scipy import integrate
import numpy as np
# Define a function to integrate
def func(x):
return np.sin(x)
# Compute the integral of sin(x) from 0 to pi
result, error = integrate.quad(func, 0, np.pi)
print(f"Integral result: {result}")

Statsmodels
Statsmodels is a Python library designed for statistical modelling and analysis. It provides classes and functions for estimating various statistical models, performing statistical tests, and analyzing data. Statsmodels is particularly popular for its detailed focus on statistical inference, making it an excellent choice for tasks requiring a deep understanding of relationships and patterns in the data.
Key Features of Statsmodels
- Statistical Models: Supports a variety of models, including linear regression, generalized linear models (GLMs), time series analysis (e.g., ARIMA), and survival analysis.
- Statistical Tests: Offers a wide range of hypothesis tests like t-tests, chi-square tests, and non-parametric tests.
- Descriptive Statistics: This Python library for data science allows summary statistics and exploration of datasets.
- Deep Statistical Inference provides rich output, such as confidence intervals, p-values, and model diagnostics, which are crucial for hypothesis testing.
- Integration with Pandas and NumPy: Works seamlessly with Pandas DataFrames and NumPy arrays for efficient data manipulation.
Advantages of Statsmodels
- Comprehensive Statistical Analysis: Delivers tools for in-depth statistical insights, including model diagnostics and visualizations.
- Ease of Use: Provides well-documented APIs and a structure similar to other Python data libraries.
- Focus on Inference: Unlike libraries like scikit-learn, which emphasize prediction, Statsmodels excels in statistical inference and hypothesis testing.
- Visualization Tools: Offers built-in plotting functions for model diagnostics and statistical distributions.
- Open Source and Active Community: Regular updates and contributions make it a reliable choice.
Disadvantages of Statsmodels
- Limited Machine Learning Features: Lacks advanced features for modern machine learning like neural networks or tree-based models (unlike scikit-learn).
- Performance on Large Datasets: It may not be as fast or optimized as other libraries for handling large-scale datasets.
- Learning Curve for Beginners: While powerful, it requires a good understanding of statistics to leverage its capabilities effectively.
- Less Focused on Automation: Requires manual setup for some automated tasks in libraries like scikit-learn.
Applications of Statsmodels
- Economic and Financial Analysis: Time series forecasting and regression analysis are used to understand economic indicators and financial trends.
- Healthcare and Biostatistics: Survival analysis and logistic regression support clinical trials and binary outcome predictions.
- Social Sciences: Hypothesis testing and ANOVA enable experimental data analysis and statistical comparisons.
- Academics and Research: Statsmodels is preferred for researchers needing in-depth statistical insights.
- Business Analytics: A/B testing and customer segmentation help optimize marketing campaigns and reduce churn.
import statsmodels.api as sm
import numpy as np
# Generate synthetic data
x = np.linspace(0, 10, 100)
y = 3 * x + np.random.normal(0, 1, 100)
# Add a constant to the predictor variable
x = sm.add_constant(x)
# Fit the regression model
model = sm.OLS(y, x).fit()
print(model.summary())
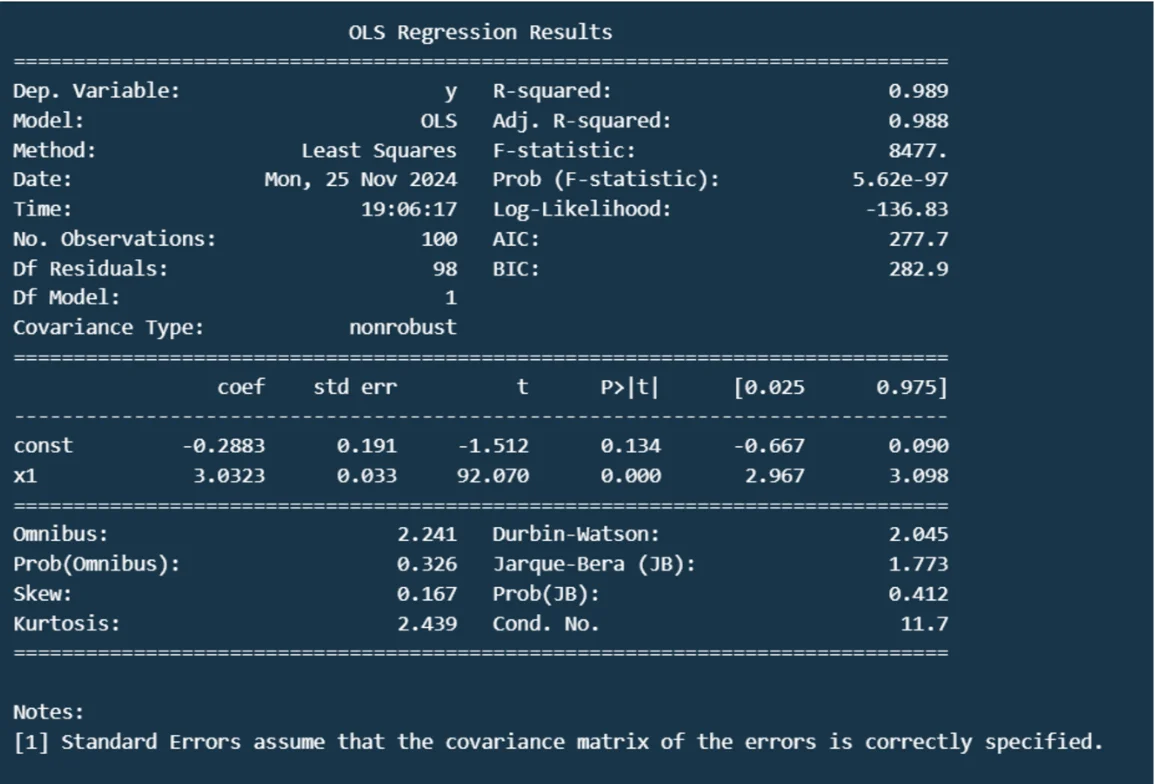
Plotly
Plotly is a versatile, open-source library for creating interactive data visualizations. It is built on top of popular JavaScript libraries like D3.js and WebGL, enabling users to create highly customizable and dynamic charts and dashboards. Plotly supports Python, R, MATLAB, Julia, and JavaScript, making it accessible to many developers and data scientists.
The library is particularly valued for its ability to produce interactive plots that can be embedded in web applications, Jupyter notebooks, or shared as standalone HTML files.
Key Features
- Interactive Visualizations: This tool allows the creation of dynamic and interactive charts, such as scatter plots, bar graphs, line charts, and 3D visualizations. Users can zoom, pan, and hover for detailed insights.
- Wide Range of Charts: It supports advanced visualizations like heat maps, choropleths, sunburst plots, and waterfall charts.
- Dashboards and Apps: Enable building interactive dashboards and web applications using Dash, a companion framework by Plotly.
- Cross-Language Support: It is available in Python, R, MATLAB, and JavaScript, making it accessible to developers in diverse ecosystems.
- Web-Based Rendering: V visualizations are rendered in browsers using WebGL, making them platform-independent and easily shareable.
- Customization: Extensive customization options allow detailed control over layout, themes, and annotations.
Advantages of Plotly
- Interactivity: Charts created with Plotly are interactive by default. Users can easily zoom, pan, hover for tooltips, and toggle data series.
- Wide Range of Visualizations: It supports various plot types, including scatter plots, line charts, bar plots, heat maps, 3D plots, and geographical maps.
- Cross-Language Support: Available for multiple programming languages, enabling its use across diverse ecosystems.
- Ease of Integration: Easily integrates with web frameworks like Flask and Django or dashboards using Dash (a framework built by Plotly).
- Aesthetics and Customization: This Python library for data science offers high-quality, publication-ready visuals with extensive options for styling and layout customization.
- Embeddability: Visualizations can be embedded into web applications and notebooks or exported as static images or HTML files.
- Community and Documentation: Strong community support and detailed documentation make it easier for newcomers to learn and implement.
Disadvantages of Plotly
- Performance: Performance can degrade for very large datasets, especially compared to libraries like Matplotlib or Seaborn for static plots.
- Learning Curve: While powerful, the extensive options and features can be overwhelming for beginners.
- Limited Offline Functionality: Some features, especially with Dash and advanced charting, may require an internet connection or a subscription to Plotly Enterprise.
- Size of Output: The output file size of Plotly visualizations can be more significant than that of static plotting libraries.
- Dependency on JavaScript: Since Plotly relies on JavaScript, some complex configurations may need additional JS knowledge.
Applications of Plotly
- Data Analysis and Exploration: Used extensively in data science for exploring datasets with interactive visualizations.
- Dashboards: Ideal for building interactive dashboards with frameworks like Dash for real-time monitoring and reporting.
- Scientific Research: It supports the high-quality visualizations required for publications and presentations.
- Business Intelligence: Helps create dynamic and interactive charts for insights, trend analysis, and decision-making.
- Geospatial Analysis: Widely used for visualizing geographical data through maps like choropleths and scatter geo-plots.
- Education: Used in teaching data visualization techniques and principles due to its intuitive and interactive nature.
- Web Applications: Easily embeds into web applications, enhancing user interaction with data.
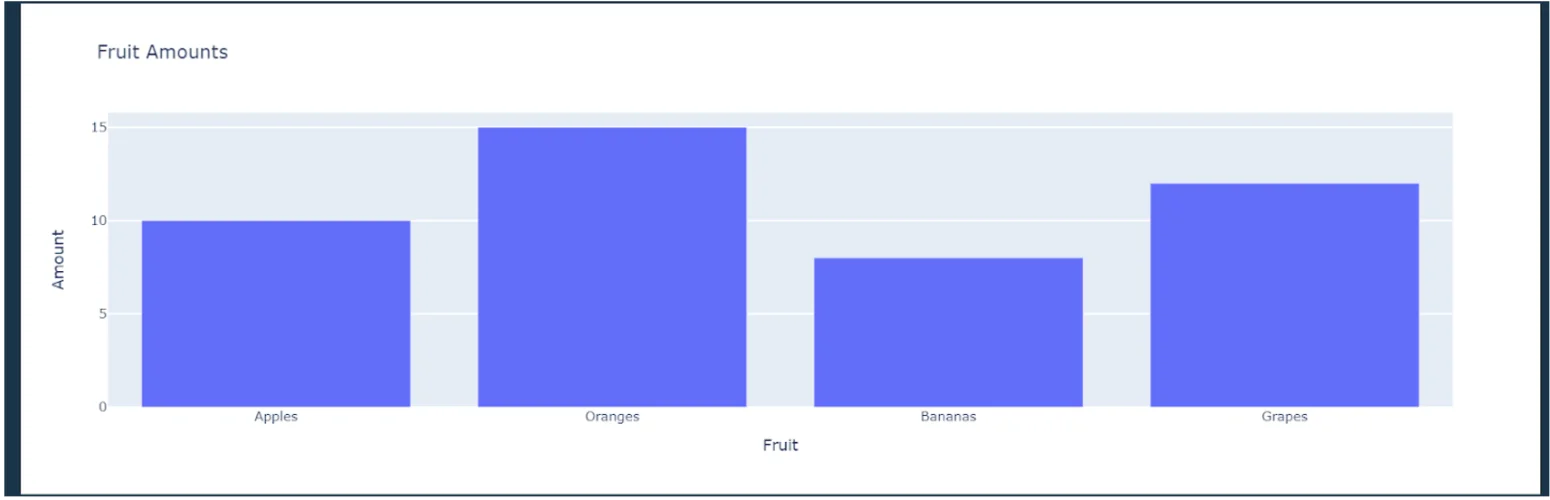
import plotly.express as px
import pandas as pd
# Sample data
data = {
"Fruit": ("Apples", "Oranges", "Bananas", "Grapes"),
"Amount": (10, 15, 8, 12)
}
df = pd.DataFrame(data)
# Create a bar chart
fig = px.bar(df, x="Fruit", y="Amount", title="Fruit Amounts")
fig.show()
BeautifulSoup
BeautifulSoup is a Python library for web scraping and parsing HTML or XML documents. This Python library for data science provides tools for navigating and modifying the parse tree of a web page, enabling developers to extract specific data efficiently. It works with parsers like lxml or Python’s built-in HTML. parser to read and manipulate web content.
Key Features
- HTML and XML Parsing: Beautiful Soup can parse and navigate HTML and XML documents, making it easy to extract, modify, or scrape web data.
- Tree Navigation: Converts parsed documents into a parse tree, allowing traversal using Pythonic methods like tags, attributes, or CSS selectors.
- Fault Tolerance: Handles poorly formatted or broken HTML documents gracefully, enabling robust web scraping.
- Integration with Parsers: It works seamlessly with different parsers, such as lxml, html.parser, and html5lib, for optimized performance and features.
- Search Capabilities: Supports methods like .find(), .find_all(), and CSS selectors for locating specific document elements.
Advantages of BeautifulSoup
- Easy to Use: BeautifulSoup offers a simple and intuitive syntax, making it beginner-friendly.
- Flexible Parsing: It can parse and work with well-formed and poorly formatted HTML or XML.
- Integration with Other Libraries: Works seamlessly with libraries like requests for HTTP requests and pandas for data analysis.
- Powerful Search Capabilities: Allows precise searches using tags, attributes, and CSS selectors.
- Cross-platform Compatibility: Being Python-based, it works on various operating systems.
Disadvantages of BeautifulSoup
- Performance Limitations: It can be slower than web-scraping tools like lxml or Scrapy for large-scale scraping tasks.
- Limited to Parsing: BeautifulSoup does not handle HTTP requests or browser interactions, so additional tools are required for such tasks.
- Dependency on Page Structure: Any changes in the web page’s HTML can break the scraping code, necessitating frequent maintenance.
Applications of BeautifulSoup
- Web Data Extraction: Scraping data like news articles, product prices, and website reviews
- Data Cleaning and Transformation: Cleaning HTML content for specific tags or formatting.
- Research and Analysis: Gathering information for academic, sentiment, or competitive research.
- Automated Reporting: Extracting and summarizing data for periodic reports.
- SEO and Content Monitoring: Analyzing page structures, keywords, or metadata for SEO insights.
from bs4 import BeautifulSoup
import requests
# Fetch a webpage
url = "https://oracle.com"
response = requests.get(url)
# Parse the webpage
soup = BeautifulSoup(response.content, "html.parser")
# Extract and print the title of the webpage
title = soup.title.string
print("Page Title:", title)

NLTK
The Natural Language Toolkit (NLTK) is a comprehensive library for processing human language data (text) in Python. Developed initially as a teaching and research tool, NLTK has grown to become one of the most popular libraries for tasks related to Natural Language Processing (NLP). This Python library for data science offers many tools for functions such as tokenization, stemming, lemmatization, parsing, etc.
Key Features
- Text Processing: Functions for tokenization, stemming, lemmatization, and word segmentation.
- Corpus Access: Built-in access to over 50 corpora and lexical resources like WordNet.
- Machine Learning: Basic support for text classification and feature extraction.
- Parsing and Tagging: Includes tools for syntactic parsing and Part-of-Speech (POS) tagging.
- Visualization: Offers tools to visualize linguistic data.
Advantages of NLTK
- Comprehensive Toolkit: Covers almost all standard NLP tasks, making it ideal for beginners.
- Ease of Use: User-friendly with well-documented functions and examples.
- Rich Resources: Provides access to large corpora and lexical resources.
- Customizability: Allows users to fine-tune processing steps or implement their algorithms.
- Educational Value: Designed with a strong focus on teaching NLP concepts.
Disadvantages of NLTK
- Performance Issues: Processing large datasets can be slow compared to modern alternatives like spaCy.
- Outdated for Some Use Cases: Does not natively support deep learning or state-of-the-art NLP methods.
- Steeper Learning Curve: Some advanced functions require significant effort to master.
- Limited Scalability: Best suited for small to medium-sized NLP projects.
Applications of NLTK
- Text Preprocessing: NLTK facilitates text preprocessing tasks such as tokenizing sentences or words and removing stopwords or punctuation to prepare text for further analysis.
- Text Analysis: It enables sentiment analysis using methods like bag-of-words or lexical resources such as WordNet, and supports POS tagging and chunking to understand sentence structure.
- Language Modeling: The Python library for data science implements basic language models for text prediction and other language processing tasks.
- Educational and Research Tool: NLTK is widely employed in academia for teaching NLP concepts and conducting research in computational linguistics.
- Linguistic Analysis: It aids in building thesauruses and exploring relationships between words, such as synonyms and hypernyms, for linguistic studies.
import nltk
from nltk.tokenize import word_tokenize
# Sample text
text = "Natural Language Toolkit is a library for processing text in Python."
# Tokenize the text into words
tokens = word_tokenize(text)
print("Tokens:", tokens)
# Download stopwords if not already done
nltk.download('stopwords')
from nltk.corpus import stopwords
# Filter out stopwords
stop_words = set(stopwords.words('english'))
filtered_tokens = (word for word in tokens if word.lower() not in stop_words)
print("Filtered Tokens:", filtered_tokens)

SpaCy
SpaCy is an open-source Python library for advanced Natural Language Processing (NLP) tasks. It provides a robust and efficient framework for building NLP applications by combining powerful pre-trained models and user-friendly APIs. SpaCy is mainly known for its speed and accuracy in handling large volumes of text, making it a popular choice among developers and researchers.
Key Features and Capabilities of SpaCy
- Natural Language Processing Pipeline: This provides a full NLP pipeline, including tokenization, part-of-speech tagging, named entity recognition (NER), dependency parsing, and more.
- Pretrained Models: Offers a range of pretrained models for various languages, enabling out-of-the-box text processing in multiple languages.
- Speed and Efficiency: Designed for production use with fast processing speeds and low memory overhead.
- Integration with Machine Learning: It works seamlessly with deep learning frameworks like TensorFlow and PyTorch, allowing users to create custom pipelines and integrate NLP with other ML workflows.
- Extensibility: This Python library for data science is highly customizable and supports adding custom components, rules, and extensions to the processing pipeline.
- Visualization Tools: Includes built-in visualizers like displays for rendering dependency trees and named entities.
Advantages of SpaCy
- Speed and Efficiency: SpaCy is designed for production, offering fast processing for large-scale NLP tasks.
- Pre-trained Models: It provides pre-trained models for various languages optimized for tasks such as part-of-speech tagging, named entity recognition (NER), and dependency parsing.
- Easy Integration: Integrates seamlessly with other libraries like TensorFlow, PyTorch, and scikit-learn.
- Extensive Features: Offers tokenization, lemmatization, word vectors, rule-based matching, and more.
- Multilingual Support: Provides support for over 50 languages, making it versatile for global applications.
- Customizability: Allows users to train custom pipelines and extend their functionalities.
- Good Documentation: Offers comprehensive documentation and tutorials, making it beginner-friendly.
Disadvantages of SpaCy
- High Memory Usage: SpaCy models can consume significant memory, which may be challenging for resource-constrained environments.
- Limited Flexibility for Custom Tokenization: Although customizable, its tokenization rules are less flexible than alternatives like NLTK.
- Focused on Industrial Use: Prioritizes speed and production-readiness over experimental NLP features, limiting exploratory use cases.
- No Built-in Sentiment Analysis: Unlike some libraries, SpaCy doesn’t automatically provide sentiment analysis. Third-party tools need to be integrated for this.
Applications of SpaCy
- Named Entity Recognition (NER): Identifying entities like names, locations, dates, and organizations in the text (e.g., extracting customer data from emails).
- Text Classification: Categorizing text into predefined categories, such as spam detection or topic modelling.
- Dependency Parsing: Analyzing grammatical structure to understand relationships between words (e.g., question-answering systems).
- Information Extraction: Extracting structured information, such as extracting keywords from legal documents.
- Text Preprocessing: Tokenizing, lemmatizing, and cleaning text data for machine learning models.
- Chatbots and Virtual Assistants: Enhancing conversational ai systems with linguistic features and context understanding.
- Translation Memory Systems: Supporting language translation applications with accurate text segmentation and feature extraction.
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Process text
doc = nlp("SpaCy is a powerful NLP library.")
# Extract named entities, part-of-speech tags, and more
for token in doc:
print(f"Token: {token.text}, POS: {token.pos_}, Lemma: {token.lemma_}")
# Extract named entities
for ent in doc.ents:
print(f"Entity: {ent.text}, Label: {ent.label_}")
XGBoost
XGBoost (eXtreme Gradient Boosting) is an open-source machine-learning library designed for high-performance and flexible gradient boosting. It was developed to improve speed and efficiency while maintaining scalability and accuracy. It supports various programming languages, including Python, R, Java, and C++. XGBoost is widely used for both regression and classification tasks.
Key Features and Capabilities of XGBoost
- Gradient Boosting Framework: Implements a scalable and efficient version of gradient boosting for supervised learning tasks.
- Regularization: Includes L1 and L2 regularization to reduce overfitting and improve generalization.
- Custom Objective Functions: Supports user-defined objective functions for tailored model optimization.
- Handling Missing Values: Efficiently manages missing data by learning optimal split directions during training.
- Parallel and Distributed Computing: Leverages multithreading and supports distributed computing frameworks like Hadoop and Spark.
- Feature Importance: Provides tools to rank features based on their contribution to model performance.
- Cross-Validation: This Python library for data science offers built-in cross-validation capabilities for tuning hyperparameters.
Advantages of XGBoost:
- Uses optimized gradient boosting algorithms.
- Provides parallel processing for faster computation.
- Efficient handling of sparse data using optimized memory and computational resources.
- Supports custom objective functions.
- Compatible with many data types, including sparse and structured data.
- Includes L1 (Lasso) and L2 (Ridge) regularization to prevent overfitting.
- Offers additional control over the model complexity.
- Provides feature importance scores, which aid in understanding the model’s decision process.
- Handles large datasets efficiently and scales well across distributed systems.
- Compatible with scikit-learn and other machine learning frameworks, facilitating easy integration.
Disadvantages of XGBoost:
- Complexity: Requires careful tuning of hyperparameters to achieve optimal performance, which can be time-consuming.
- Memory Consumption: It may consume significant memory when working with massive datasets.
- Risk of Overfitting: It can overfit the training data if not correctly regularized or tuned.
- Harder Interpretability: Interpreting individual predictions can be challenging as an ensemble model compared to simpler models like linear regression.
Applications of XGBoost:
- Finance: Credit scoring, fraud detection, and algorithmic trading.
- Healthcare: Disease prediction, medical diagnostics, and risk stratification.
- E-commerce: Customer segmentation, recommendation systems, and sales forecasting.
- Marketing: Lead scoring, churn prediction, and campaign response modelling.
- Competitions: Extensively used in machine learning competitions like Kaggle due to its high performance.
import xgboost as xgb
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load dataset
data = fetch_california_housing()
x, y = data.data, data.target
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# Create and train an XGBoost regressor
model = xgb.XGBRegressor(objective="reg:squarederror", random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
LightGBM
LightGBM is an open-source, distributed, high-performance implementation of Microsoft’s gradient-boosting framework. It is designed to be highly efficient, scalable, and flexible, particularly for large datasets. It is based on the gradient boosting concept, where models are trained sequentially to correct the errors of the previous ones. However, LightGBM introduces several optimizations to enhance speed and accuracy.
Key Features:
- Gradient Boosting: A decision tree-based algorithm that builds models iteratively, where each tree tries to correct the errors made by the previous one.
- Leaf-wise Growth: Unlike traditional tree-building methods like level-wise growth (used by other boosting algorithms like XGBoost), LightGBM grows trees leaf-wise. This typically results in deeper trees and better performance, though it can sometimes lead to overfitting if not tuned correctly.
- Histogram-based Learning: LightGBM uses histogram-based algorithms to discretize continuous features, reducing memory usage and speeding up computation.
- Support for Categorical Features: It natively handles categorical features without manual encoding (like one-hot encoding).
- Parallel and GPU Support: It supports parallel and GPU-based computation, significantly improving training time for large datasets.
Advantages of LightGBM:
- Speed and Efficiency: LightGBM is known for its speed and ability to handle large datasets efficiently. Its histogram-based approach significantly reduces memory usage and speeds up training.
- Accuracy: It often outperforms other gradient-boosting algorithms like XGBoost in terms of accuracy, especially for extensive and high-dimensional data.
- Scalability: This Python library for data science is highly scalable to large datasets and is suitable for distributed learning.
- Handling Categorical Data: It natively handles categorical features, which can simplify preprocessing.
- Overfitting Control: The leaf-wise growth strategy can improve model accuracy without overfitting if properly tuned with parameters like max_depth or num_leaves.
Disadvantages of LightGBM:
- Risk of Overfitting: The leaf-wise growth can lead to overfitting, especially if the number of leaves or tree depth is not tuned correctly.
- Memory Consumption: While LightGBM is efficient, its memory usage can still be significant compared to other algorithms. for massive datasets
- Complex Hyperparameter Tuning: LightGBM has several hyperparameters (e.g., number of leaves, max depth, learning rate) that need careful tuning to avoid overfitting or underfitting.
- Interpretability: Like other boosting algorithms, the models can become complex and more challenging to interpret than simpler models like decision trees or linear regression.
Applications of LightGBM:
- Classification Tasks: It is widely used for classification problems, such as predicting customer churn, fraud detection, sentiment analysis, etc.
- Regression Tasks: LightGBM can be applied to regression problems, such as predicting housing prices, stock prices, or sales forecasts.
- Ranking Problems: It is used to rank problems such as recommendation systems or search engine result rankings.
- Anomaly Detection: It can be applied to detect outliers or anomalies in data and is helpful in fraud detection or cybersecurity.
- Time Series Forecasting: LightGBM can be adapted to time series prediction problems, although it may require feature engineering for temporal dependencies.
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
data = load_breast_cancer()
x = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# Create LightGBM dataset
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# Define parameters
params = {
"objective": "binary",
"metric": "binary_error",
"boosting_type": "gbdt"
}
# Train the model
model = lgb.train(params, train_data, valid_sets=(test_data), early_stopping_rounds=10)
# Make predictions
y_pred = model.predict(X_test)
y_pred_binary = (y_pred > 0.5).astype(int)
# Evaluate
print("Accuracy:", accuracy_score(y_test, y_pred_binary))

CatBoost
CatBoost (short for Categorical Boosting) is an open-source gradient boosting library developed by Yandex. It is designed to handle categorical data efficiently. It is instrumental in machine learning tasks that involve structured data, offering excellent performance and ease of use. This Python library for data science is based on the principles of decision tree-based learning but incorporates advanced techniques to improve accuracy, training speed, and model interpretability.
Key Features
- Gradient Boosting on Decision Trees: Specializes in gradient boosting with innovative techniques to handle categorical features effectively.
- Built-in Handling of Categorical Features: Converts categorical variables into numeric representations without manual preprocessing.
- Fast Training: Optimized for high performance with fast learning speeds and GPU support.
- Robustness to Overfitting: Implements techniques such as ordered boosting to reduce overfitting.
- Model Interpretability: Provides tools for feature importance analysis and visualizations.
- Cross-Platform Compatibility: Compatible with multiple programming languages like Python, R, and C++.
- Scalability: Efficient for both small and large datasets with high-dimensional data.
Advantages of CatBoost
- Native Handling of Categorical Features: CatBoost directly processes categorical features without requiring extensive preprocessing or encoding (e.g., one-hot encoding). This saves time and reduces the risk of errors.
- High Performance: It often achieves state-of-the-art results on structured data, with robust out-of-the-box performance and less hyperparameter tuning than other libraries like XGBoost or LightGBM.
- Fast Training and Inference: CatBoost employs efficient algorithms to speed up training and inference without compromising accuracy.
- Reduced Overfitting: The library incorporates techniques like Ordered Boosting, which minimizes information leakage and reduces overfitting.
- Ease of Use: The library is user-friendly, with built-in support for metrics visualization, model analysis tools, and straightforward parameter configuration.
- GPU Acceleration: CatBoost supports GPU training, enabling faster computation for large datasets.
- Model Interpretability: It provides tools like feature importance analysis and SHAP (Shapley Additive explanations) values to explain predictions.
Disadvantages of CatBoost
- Memory Consumption: It can consume significant memory, especially for large datasets or when training on GPUs.
- Longer Training Time for Some Use Cases: While generally fast, CatBoost can be slower for smaller datasets or simpler algorithms in specific scenarios.
- Limited to Tree-Based Models: CatBoost is specialized for gradient boosting and may not be suitable for tasks requiring other model types (e.g., neural networks for image or text data).
- Steeper Learning Curve for Customization: While user-friendly for primary use, advanced customization might require understanding the library’s inner workings.
Applications of CatBoost
- Finance: Credit scoring, fraud detection, customer churn prediction, and risk assessment due to its ability to handle structured financial datasets.
- E-commerce: Product recommendation systems, click-through rate prediction, and demand forecasting.
- Healthcare: Patient risk stratification, medical billing fraud detection, and diagnosis prediction.
- Marketing: Customer segmentation, lead scoring, and campaign optimization.
- Real Estate: Property price prediction and investment analysis.
- Logistics: Route optimization and delivery time prediction.
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
data = load_iris()
x, y = data.data, data.target
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=42)
# Initialize and train CatBoostClassifier
model = CatBoostClassifier(iterations=100, learning_rate=0.1, verbose=0)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate
print("Accuracy:", accuracy_score(y_test, y_pred))
OpenCV
OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library. Originally developed by Intel, it is now maintained by a large community and supports a wide range of image processing, computer vision, and machine learning tasks. OpenCV is written in C++ and has bindings for Python, Java, and other languages, making it versatile and accessible to developers across various platforms.
Key Features
- Image Processing: Supports operations like filtering, edge detection, histograms, and geometric transformations.
- Object Detection and Recognition: Offers tools for detecting faces, eyes, and features such as corners and contours.
- Machine Learning Integration: Includes pre-trained models and algorithms for classification, clustering, and feature extraction.
- Video Analysis: Provides capabilities for motion detection, object tracking, and background subtraction.
- Cross-Platform Compatibility: Runs on Windows, Linux, macOS, and Android/iOS platforms.
Advantages of OpenCV
- Wide Range of Features: OpenCV provides tools for image processing, object detection, facial recognition, motion analysis, 3D reconstruction, and more.
- Cross-Platform Compatibility: Works on multiple platforms, including Windows, Linux, macOS, iOS, and Android.
- Integration with Other Libraries: This Python library for data science integrates well with libraries like NumPy, TensorFlow, and PyTorch, enabling seamless development of advanced machine learning and computer vision projects.
- High Performance:Written in optimized C++, OpenCV is designed for real-time applications and offers fast performance in many computational tasks.
- Open-Source and F are open-source under the BSD lic and free for academic and commercial use.
- Active Community Support: A vast community ensures frequent updates, extensive documentation, and problem-solving forums.
Disadvantages of OpenCV
- Steep Learning Curve: Due to its complexity and low-level programming style, beginners may find it challenging, especially when working directly with C++.
- Limited Deep Learning Capabilities: While it supports DNN modules for deep learning, its functionality is less comprehensive than that of libraries like TensorFlow or PyTorch.
- Dependency on Other Libraries: Some advanced features require additional libraries or frameworks, which can complicate installation and setup.
- Debugging Challenge: Debugging in OpenCV can be complex due to its low-level nature, especially for real-time applications.
- Documentation Gaps: Although extensive, some advanced topics may lack detailed or beginner-friendly explanations.
Applications of OpenCV
- Image Processing: OpenCV is widely used for image enhancement, filtering, and transformations, including tasks like histogram equalization and edge detection.
- Object Detection and Recognition: It supports face detection using techniques such as Haar cascades and enables applications like QR code and barcode scanning.
- Motion Analysis: The library facilitates optical flow estimation and motion tracking in videos, crucial for dynamic scene analysis.
- Augmented Reality (AR): OpenCV powers marker-based AR applications and allows overlaying virtual objects onto real-world images.
- Medical Imaging: It is utilized for analyzing medical images such as x-rays, CT scans, and MRI scans for diagnostic purposes.
- Industrial Automation: OpenCV is key in quality inspection, defect detection, and robotic vision for industrial applications.
- Security and Surveillance: It supports intruder detection and license plate recognition, enhancing security systems.
- Gaming and Entertainment: The library enables gesture recognition and real-time face filters for interactive gaming and entertainment experiences.
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import convolve2d
import cv2
image = cv2.imread("assasin.png")
image1 = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image1)
Dask
Dask is a flexible parallel computing library in Python designed to scale workflows from a single machine to large clusters. It is particularly well-suited for handling large datasets and computationally intensive tasks that do not fit into memory or require parallel execution. Dask integrates seamlessly with popular Python libraries such as NumPy, pandas, and scikit-learn, making it a versatile choice for data science and machine learning workflows.
Key Features and Capabilities
- Parallelism: Executes tasks in parallel on multicore machines or distributed clusters.
- Scalability: Scales computations from small datasets on a laptop to terabytes of data on a distributed cluster.
- Flexible API: Offers familiar APIs for collections like arrays, dataframes, and machine learning that mimic NumPy, pandas, and scikit-learn.
- Lazy Evaluation: Builds operation task graphs, optimizing execution only when results are needed.
- Integration: Works seamlessly with Python’s data ecosystem, supporting libraries such as pandas, NumPy, and more.
- Custom Workflows: Supports custom parallel and distributed computing workflows through its low-level task graph API.
Advantages of Dask
- Scalability: Dask can operate on single machines and distributed systems, enabling easy scaling from a local laptop to a multi-node cluster.
- Familiar API: Dask’s APIs closely mimic those of pandas, NumPy, and scikit-learn, making it easy for users familiar with these libraries to adopt it.
- Handles Larger-than-Memory Data: This Python library for data science divides large datasets into smaller, manageable chunks, enabling computation on datasets that do not fit into memory.
- Parallel and Lazy Computation: It uses lazy evaluation and task scheduling to optimize computation, ensuring tasks are executed only when needed.
- Interoperability: Dask works well with other Python libraries, such as TensorFlow, PyTorch, and XGBoost, enhancing its usability in diverse domains.
- Dynamic Task Scheduling: Dask’s scheduler optimizes execution, which is particularly beneficial for workflows with complex dependencies.
Disadvantages of Dask
- Steeper Learning Curve: While the API is familiar, optimizing workflows for distributed environments may require a deeper understanding of Dask’s internals.
- Overhead in Small-Scale Workloads: Dask’s parallelization overhead might lead to slower performance for smaller datasets, simpler tasks for smaller datasets, and more straightforward tasks than non-parallel alternatives like Pandas.
- Limited Built-in Algorithms: Compared to libraries like scikit-learn, Dask has fewer built-in algorithms and might require additional tuning for optimal performance.
- Cluster Management Complexity: Running Dask on distributed clusters can involve deployment, configuration, and resource management complexities.
- Less Community Support: While growing, Dask’s community and ecosystem are smaller compared to more established libraries like Spark.
Applications of Dask
- Big Data Analysis: Analyzing large datasets with pandas-like operations when data exceeds local memory limits.
- Machine Learning: Scaling machine learning workflows, including preprocessing, model training, and hyperparameter tuning, using libraries like Dask-ML.
- ETL Pipelines: Efficiently handling Extract, Transform, and Load (ETL) processes for big data.
- Geospatial Data Processing: Working with spatial data in combination with libraries like GeoPandas.
- Scientific Computing: Performing large-scale simulations and computations in fields like climate modelling and genomics.
- Distributed Data Processing: Leveraging distributed clusters for tasks like data wrangling, feature engineering, and parallel computation.
import dask
import dask.dataframe as dd
data_frame = dask.datasets.timeseries()
df = data_frame.groupby('name').y.std()
df
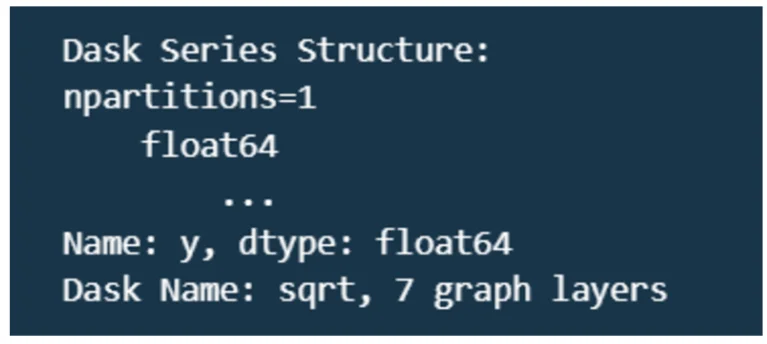
NetworkX
NetworkX is a Python library designed for creating, manipulating, and analyzing complex networks (graphs). This Python library for data science provides a versatile framework for handling standard graph structures (e.g., undirected and directed) and more complex scenarios like multigraphs, weighted graphs, or bipartite networks.
Key Features
- Graph Creation: This tool supports the construction of various graph types, including undirected, directed, multigraphs, and weighted graphs.
- Graph Algorithms: This company offers an extensive suite of algorithms for traversal, shortest path, clustering, centrality, and network flow.
- Visualization: Provides basic visualization capabilities to represent graphs intuitively.
- Integration: Compatible with other libraries like Matplotlib, Pandas, and NumPy for data manipulation and visualization.
- Ease of Use: The API is Pythonic and beginner-friendly, making it accessible to those new to graph theory.
Advantages of NetworkX
- Versatility: Handles various graph types, from simple to complex (e.g., multigraphs or weighted networks).
- Rich Algorithmic Support: Implements numerous standard and advanced graph algorithms, such as PageRank, maximum flow, and community detection.
- Python Integration: Integrates seamlessly with other Python libraries for data processing and visualization.
- Active Community: An open-source project with a solid user base and extensive documentation.
- Cross-Platform: Runs on any platform that supports Python.
Disadvantages of NetworkX
- Scalability Issues: NetworkX is not optimized for massive graphs. Graphs with millions of nodes/edges may become slow or consume excessive memory. Alternatives like igraph or Graph-tool offer better performance for large-scale networks.
- Limited Visualization: While it offers basic visualization, integration with libraries like Matplotlib or Gephi is required. For more complex visualizations
- Single-threaded Processing: NetworkX does not inherently support parallel computing, which can be a bottleneck for large datasets.
Applications of NetworkX
- Social Network Analysis: Analyzing social media and communication networks’ relationships, influence, and connectivity.
- Biological Networks: Modeling and studying protein interaction networks, gene regulatory networks, and ecological systems.
- Transportation and Logistics: Optimizing routes, analyzing transportation systems, and solving network flow problems.
- Infrastructure and Utility Networks: Representing power grids, water distribution systems, or telecommunication networks.
- Research and Education: Teaching graph theory concepts and experimenting with real-world network problems.
- Web Science: Ranking web pages using algorithms like PageRank and understanding hyperlink structures.
import networkx as nx
import matplotlib.pyplot as plt
# Create a graph
G = nx.Graph()
# Add nodes
G.add_nodes_from((1, 2, 3, 4))
# Add edges
G.add_edges_from(((1, 2), (2, 3), (3, 4), (4, 1)))
# Draw the graph
nx.draw(G, with_labels=True, node_color="lightblue", edge_color="gray", node_size=500)
plt.show()
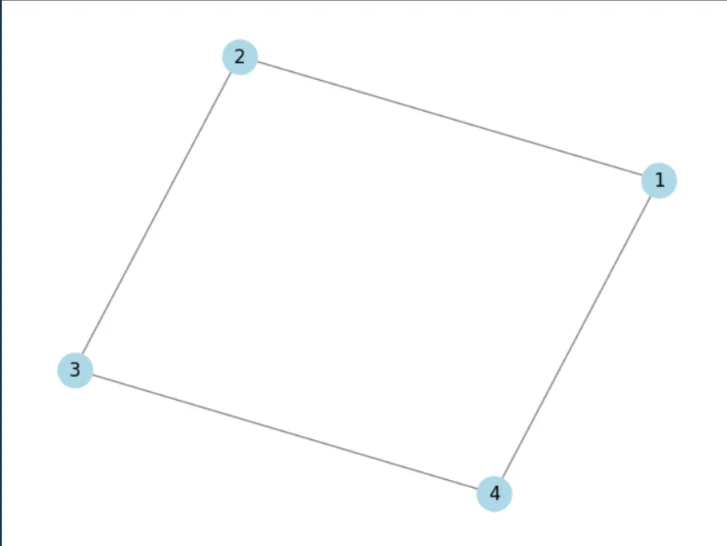
Polars
Polars is a fast, multi-threaded DataFrame library designed to work with large datasets in Python and Rust. Built for high performance, Polars uses Rust’s memory safety and efficiency features to handle data processing efficiently. It is a solid alternative to Panda, especially for computationally intensive tasks or when handling datasets that exceed memory capacity.
Key Features
- High-Performance DataFrame Operations: Polars is designed for speed, leveraging Rust’s performance capabilities to process large datasets efficiently. It supports lazy and eager execution modes.
- Columnar Data Storage: This Python library for data science uses Apache Arrow as its in-memory format, ensuring compact data representation and fast columnar data access.
- Parallel Processing: Automatically utilizes multi-threading for faster computations on multi-core processors.
- Rich API for Data Manipulation: Offers functionalities for filtering, aggregation, joins, pivots, and other common data manipulation tasks with a concise syntax.
- Interoperability: Polars integrates with Pandas, allowing easy conversion between Polars DataFrames and Pandas DataFrames for compatibility with existing workflows.
- Memory Efficiency: Optimized to handle datasets larger than memory by leveraging its lazy execution engine and efficient memory management.
Advantages of Polars
- Speed: Polars is significantly faster than traditional libraries like Pandas, especially for large datasets. It outperforms in both eager and lazy execution scenarios.
- Lazy Execution: Enables query optimization by deferring computations until the final result is requested, which reduces redundant operations.
- Scalability: Handles large datasets efficiently by utilizing Arrow for in-memory operations and multi-threaded processing.
- Type Safety: Polars enforces stricter type checks than Pandas, reducing runtime errors.
- Cross-Language Support: Written in Rust, Polars can be used in Python and Rust ecosystems, making it versatile for different projects.
Disadvantages of Polars
- Learning Curve: The syntax and concepts like lazy execution might be unfamiliar to users accustomed to Pandas.
- Feature Gaps: While robust, Polars lacks specialized features or functions in mature libraries like Pandas (e.g., rich support for datetime operations).
- Community and Ecosystem: Though growing, Polars has a smaller community and fewer third-party integrations compared to Pandas.
- Limited Visualization: Polars does not have built-in visualization tools, necessitating the use of other libraries like Matplotlib or Seaborn.
Applications of Polars
- Big Data Analytics: Processing and analyzing large-scale datasets efficiently in fields like finance, healthcare, and marketing.
- ETL Pipelines: Ideal for Extract, Transform, Load (ETL) workflows due to its speed and memory efficiency.
- Machine Learning Preprocessing: Used to preprocess large datasets for ML models, taking advantage of its optimized operations.
- Data Engineering: Suitable for creating scalable pipelines that involve heavy data wrangling and manipulation.
- Real-Time Data Processing: Can be used in real-time analytics applications requiring high performance, such as IoT and sensor data analysis.
- Scientific Research: Useful for handling large datasets in fields like bioinformatics, physics, and social sciences.
import polars as pl
# Create a simple DataFrame
df = pl.DataFrame({
"name": ("Alice", "Bob", "Charlie"),
"age": (25, 30, 35)
})
# Filter rows where age > 28
filtered = df.filter(df("age") > 28)
# Add a new column
df = df.with_columns((df("age") * 2).alias("age_doubled"))
print(df)
print(filtered)
Conclusion
Python is a versatile and user-friendly language, making it ideal for all machine-learning tasks. In this article, we covered the top 20 Python libraries for data science, catering to a wide range of needs. These libraries provide essential tools for mathematics, data mining, exploration, visualization, and machine learning. With powerful options like NumPy, Pandas, and Scikit-learn, you’ll have everything you need to manipulate data, create visualizations, and develop machine learning models.
Frequently Asked Questions
A. A good learning order for beginners is to start with NumPy and Pandas, then move to visualization with Matplotlib and Seaborn, and finally dive into machine learning with Scikit-learn and Statsmodels.
A. Dask DataFrame is faster than Pandas primarily when working with large datasets that exceed memory capacity or require distributed computing. Pandas is usually more efficient for smaller datasets or single-machine operations. Choosing between the two depends on your specific use case, including the size of your data, available system resources, and the complexity of your computations.
A. Seaborn and Matplotlib serve different purposes, and which is better depends on your needs. Matplotlib is a highly customizable, low-level library that provides detailed control over every plot aspect. It is ideal for creating complex visualizations or customizing plots to meet specific requirements. Seaborn, built on top of Matplotlib, is a high-level library designed to simplify statistical plotting and produce aesthetically pleasing visualizations with minimal code.
A. The most popular Python plotting library is Matplotlib. It is the foundational library for data visualization in Python, providing a comprehensive set of tools for creating a wide range of static, animated, and interactive plots. Many other plotting libraries, such as Seaborn, Plotly, and Pandas plotting, are built on top of Matplotlib, showcasing its importance in the Python ecosystem.

Hello, my name is Yashashwy Alok, and I am passionate about data science and analytics. I thrive on solving complex problems, uncovering meaningful insights from data, and leveraging technology to make informed decisions. Over the years, I have developed expertise in programming, statistical analysis, and machine learning, with hands-on experience in tools and techniques that help translate data into actionable outcomes.
I’m driven by a curiosity to explore innovative approaches and continuously enhance my skill set to stay ahead in the ever-evolving field of data science. Whether it’s crafting efficient data pipelines, creating insightful visualizations, or applying advanced algorithms, I am committed to delivering impactful solutions that drive success.
In my professional journey, I’ve had the opportunity to gain practical exposure through internships and collaborations, which have shaped my ability to tackle real-world challenges. I am also an enthusiastic learner, always seeking to expand my knowledge through certifications, research, and hands-on experimentation.
Beyond my technical interests, I enjoy connecting with like-minded individuals, exchanging ideas, and contributing to projects that create meaningful change. I look forward to further honing my skills, taking on challenging opportunities, and making a difference in the world of data science.





