 NEWSLETTER
NEWSLETTER

Image by author
In today’s data-driven world, data analysis and insights help you make the most of data and make better decisions. From a company’s perspective, it provides a competitive advantage and personalizes the entire process.
This tutorial will explore the most powerful Python library. pandas, and we will discuss the most important functions of this library that are important for data analysis. Beginners can also follow this tutorial due to its simplicity and efficiency. If you don’t have Python installed on your system, you can use Google Colaboratory.
You can download the data set from that link.
import pandas as pd
df = pd.read_csv("kaggle_sales_data.csv", encoding="Latin-1") # Load the data
df.head() # Show first five rowsProduction:
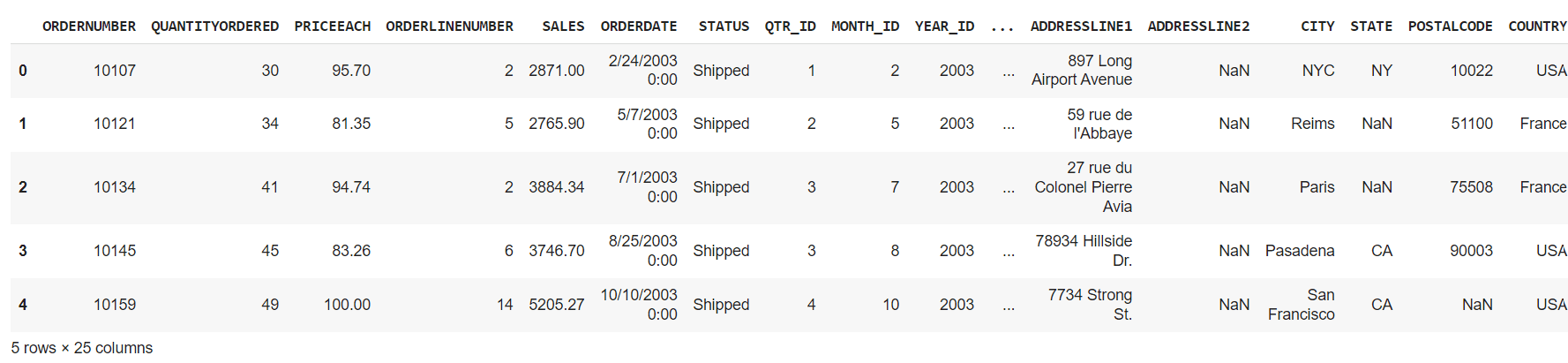
In this section, we will discuss several features that will help you get more information about your data. How to view or get the mean, average, min/max or get information about the data frame.
1. Data visualization
-
df.head(): Displays the first five rows of the sample data.
-
df.tail(): Displays the last five rows of the sample data.

-
df.sample(n): Displays the random number of n rows in the sample data.
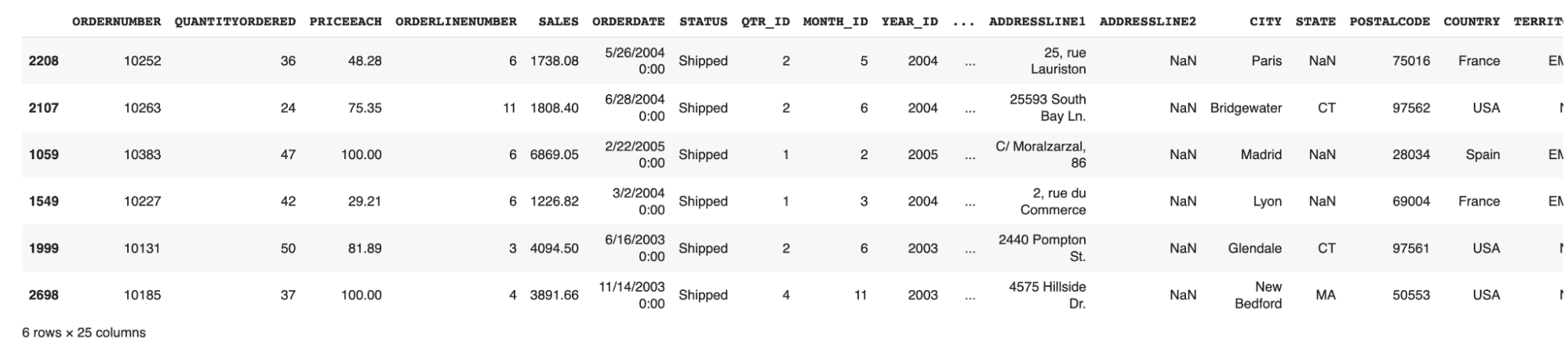
-
df.shape: Displays the rows and columns (dimensions) of the sample data.
It means that our data set has 2823 rows, each of which contains 25 columns.
2. Statistics
This section contains the functions that help you perform statistics such as average, minimum/maximum, and quartiles on your data.
-
df.describe(): Get the basic statistics of each column of the sample data
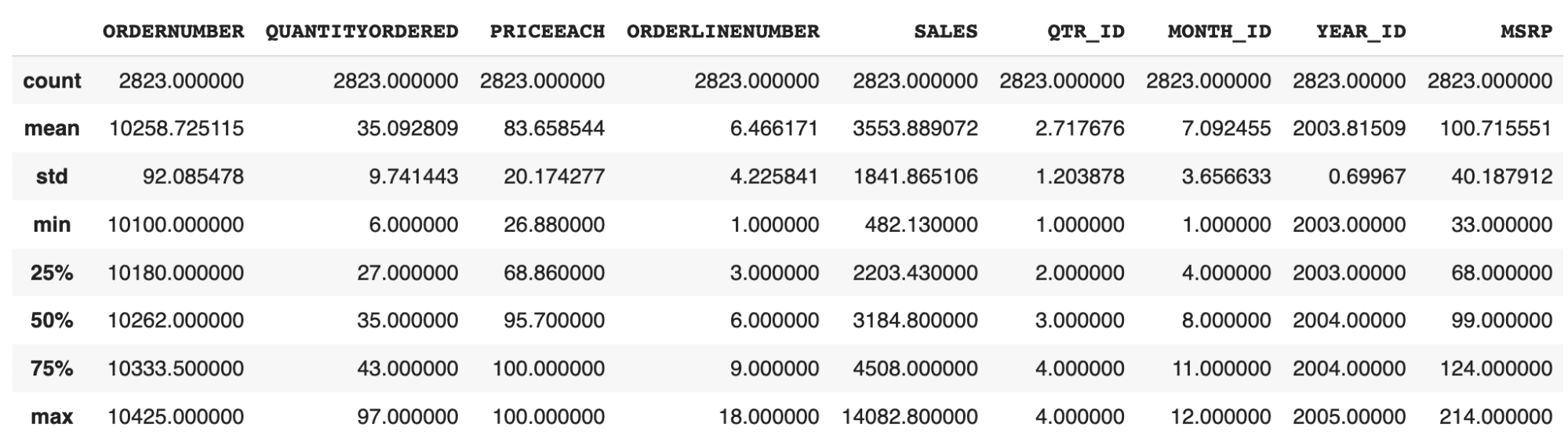
-
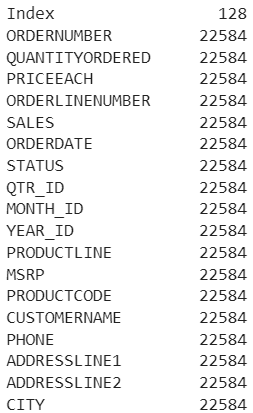
df.info()– Learn about the different data types used and the non-null count of each column.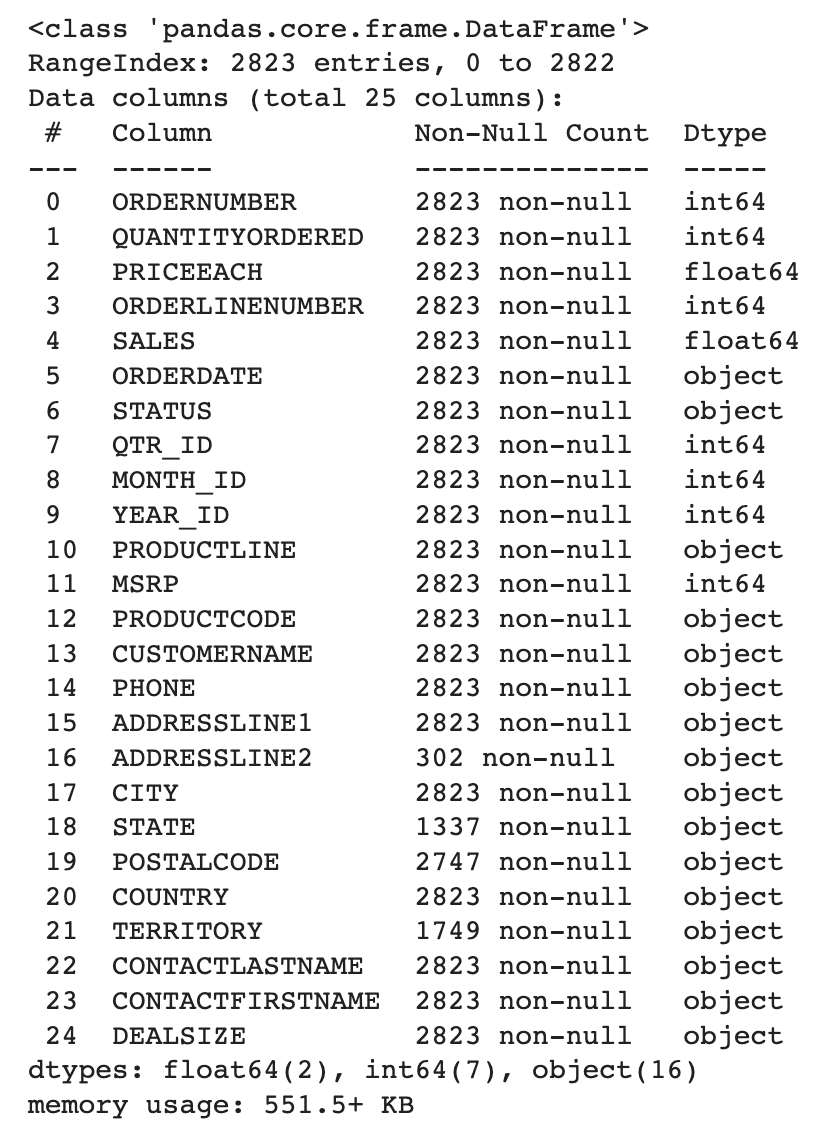
-
df.corr(): This can give you the correlation matrix between all integer columns in the data frame.
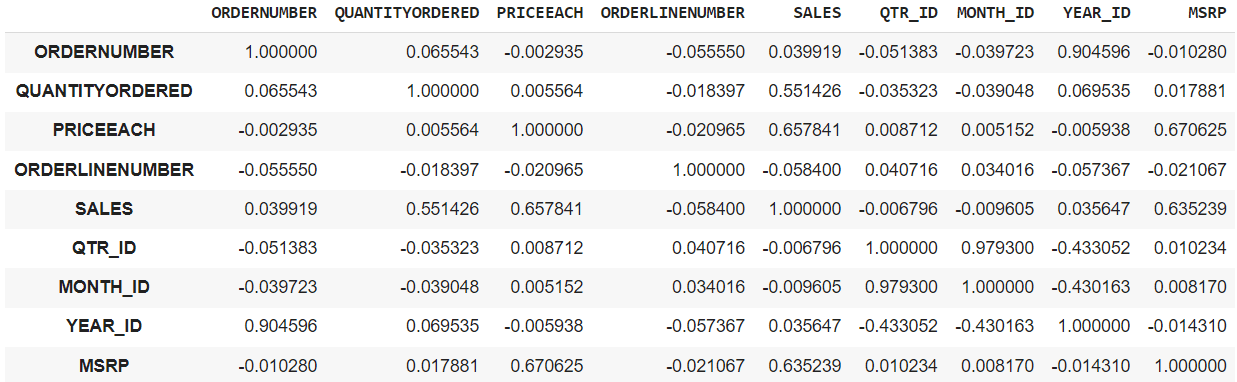
-
df.memory_usage(): It will tell you how much memory each column consumes.
3. Data selection
You can also select data from any specific row, column, or even multiple columns.
-
df.iloc(row_num): Will select a particular row based on its index
For ex-,
-
df(col_name): Will select the particular column
For ex-,
Production:
-
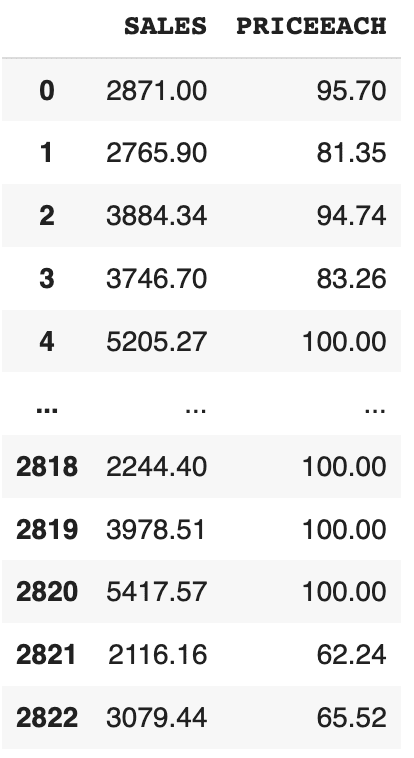
df((‘col1’, ‘col2’)): Will select multiple given columns
For ex-,
df(("SALES", "PRICEEACH"))Production:
These functions are used to handle missing data. Some rows of the data contain some null and garbage values, which may hamper the performance of our trained model. Therefore, it is always better to correct or remove these missing values.
-
df.isnull(): This will identify missing values in your data frame. -
df.dropna(): This will remove rows that contain missing values in any column. -
df.fillna(val): This will fill the missing values withvalgiven in the argument. -
df(‘col’).astype(new_data_type): You can convert the data type of the selected columns to a different data type.
For ex-,
We are converting the data type of the SALES column from float to int.

Here, we will use some useful functions in data analysis such as grouping, sorting and filtering.
- Aggregation functions:
You can group a column by its name and then apply some aggregation functions like sum, min/max, mean, etc.
df.groupby("col_name_1").agg({"col_name_2": "sum"})For ex-,
df.groupby("CITY").agg({"SALES": "sum"})It will give you the total sales for each city.
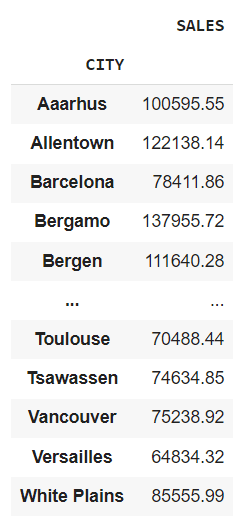
If you want to apply multiple aggregations at once, you can write them like this.
For ex-,
aggregation = df.agg({"SALES": "sum", "QUANTITYORDERED": "mean"})Production:
SALES 1.003263e+07
QUANTITYORDERED 3.509281e+01
dtype: float64- Data filtering:
We can filter the data in rows based on a specific value or condition.
For ex-,
Shows the rows where the sales value is greater than 5000
You can also filter the data frame using the query() function. It will also generate a result similar to the previous one.
For example,
- Data classification:
You can sort data based on a specific column, either in ascending or descending order.
For ex-,
df.sort_values("SALES", ascending=False) # Sorts the data in descending order- Dynamic tables:
We can create pivot tables that summarize data using specific columns. This is very useful for analyzing data when you only want to consider the effect of particular columns.
For ex-,
pd.pivot_table(df, values="SALES", index="CITY", columns="YEAR_ID", aggfunc="sum")Let me explain this to you.
-
values: Contains the column for which you want to populate the table cells. -
index: The column used in it will become the row index of the pivot table, and each unique category of this column will become a row of the pivot table. -
columns: Contains the headers of the pivot table and each unique element will become the column of the pivot table. -
aggfunc: This is the same aggregation function that we discussed earlier.
Production:
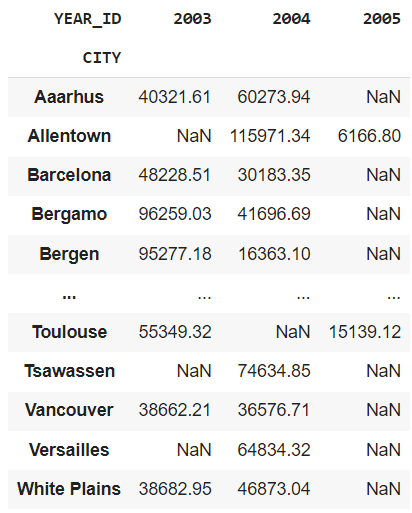
This result displays a graph showing the total sales in a particular city during a specific year.
6. Combining data frames
We can combine and merge multiple data frames either horizontally or vertically. It will concatenate two data frames and return a single combined data frame.
For ex-,
combined_df = pd.concat((df1, df2))You can merge two data frames based on a common column. It is useful when you want to combine two data frames that share a common identifier.
For example,
merged_df = pd.merge(df1, df2, on="common_col")7. Apply custom functions
You can apply custom functions according to your needs, whether on a row or a column.
For ex-,
def cus_fun(x):
return x * 3
df("Sales_Tripled") = df("SALES").apply(cus_fun, axis=0)We have written a custom function that will triple the sales value of each row. axis=0 means we want to apply the custom function on a column, and axis=1 It implies that we want to apply the function on a row.
In the above method, you have to write a separate function and then call it from the apply() method. The Lambda function helps you use the custom function within the apply() method itself. Let’s see how we can do that.
df("Sales_Tripled") = df("SALES").apply(lambda x: x * 3)Apply map:
We can also apply a custom function to each element of the data frame in a single line of code. But one point to remember is that it is applicable to all elements of the data frame.
For ex-,
df = df.applymap(lambda x: str(x))It will convert the data type to a string of all elements in the data frame.
8. Time series analysis
In mathematics, time series analysis means analyzing data collected over a specific time interval, and Pandas has functions to perform this type of analysis.
Converting to DateTime object model:
We can convert the date column to a date and time format to make data manipulation easier.
For ex-,
df("ORDERDATE") = pd.to_datetime(df("ORDERDATE"))Production:
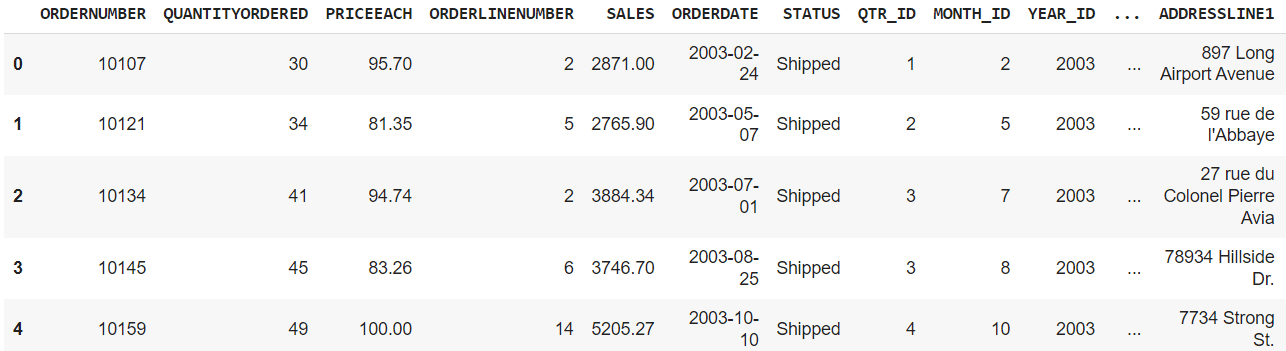
Calculate the moving average:
With this method, we can create a moving window to view the data. We can specify a moving window of any size. If the window size is 5, it means a 5-day data window at that time. It can help you eliminate fluctuations in your data and identify patterns over time.
For ex-
rolling_avg = df("SALES").rolling(window=5).mean()Production:
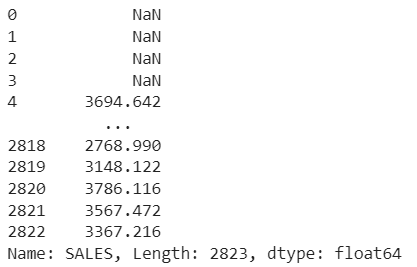
9. Cross tabulation
We can perform cross tabulations between two columns of a table. It is generally a frequency table that shows the frequency of occurrence of various categories. It can help you understand the distribution of categories in different regions.
For ex-,
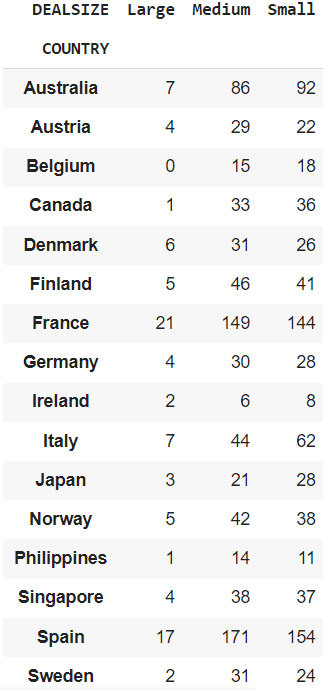
Obtain a cross tabulation between the COUNTRY and DEALSIZE.
cross_tab = pd.crosstab(df("COUNTRY"), df("DEALSIZE"))It can show you the order size (“DEALSIZE”) sorted by different countries.
10. Handling outliers
Outliers in the data mean that a particular point goes well beyond the average range. Let’s understand it through an example. Suppose you have 5 points, say 3, 5, 6, 46, 8. Then we can clearly say that the number 46 is an outlier because it is much above the average of the rest of the points. These outliers can lead to erroneous statistics and should be removed from the data set.
Here pandas come to the rescue to find these potential outliers. We can use a method called Interquartile Range (IQR), which is a common method for finding and handling these outliers. You can also read about this method if you want information about it. You can read more about them. here.
Let’s see how we can do that using pandas.
Q1 = df("SALES").quantile(0.25)
Q3 = df("SALES").quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df((df("SALES") < lower_bound) | (df("SALES") > upper_bound))Q1 is the first quartile representing the 25th percentile of the data and Q3 is the third quartile representing the 75th percentile of the data.
lower_bound The variable stores the lower bound that is used to find possible outliers. Its value is set at 1.5 times the IQR below Q1. Similarly, upper_bound calculates the upper limit, 1.5 times the IQR above Q3.
After which, it filters out outliers that are less than the lower limit or greater than the upper limit.
The Python pandas library allows us to perform advanced data manipulations and analysis. These are only some of them. You can find more tools at this pandas documentation. One important thing to remember is that the selection of techniques can be specific and tailored to your needs and the data set you are using.
Aryan Garg It is a B.tech. Electrical Engineering student, currently in the last year of the degree. His interest lies in the field of Web Development and Machine Learning. He has pursued this interest and is eager to work further in these directions.






{kind=link}