 NEWSLETTER
NEWSLETTER
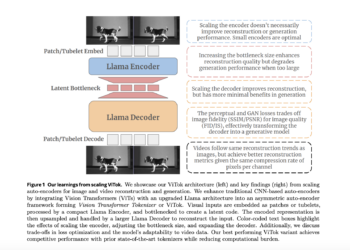
Researchers from Meta AI and UT Austin explored scaling in autoencoders and introduced ViTok: a ViT-style autoencoder for performing exploration
Modern image and video generation methods rely heavily on tokenization to encode high-dimensional data into compact latent representations. While advances ...




