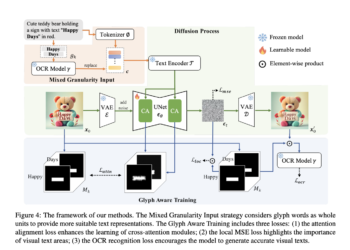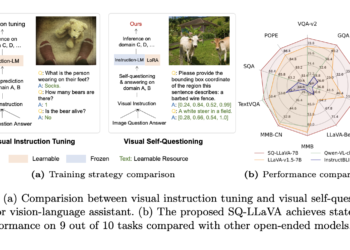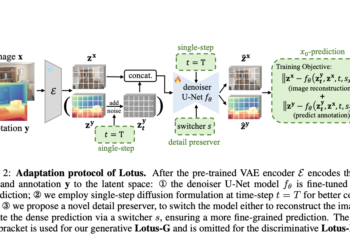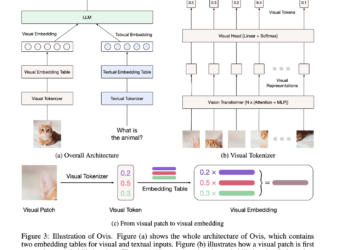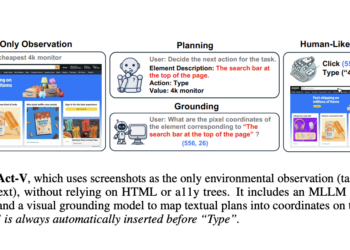
UGround: A Universal GUI Visual Connection Model Developed Using Large-Scale Web-Based Synthetic Data
Graphical user interface (GUI) agents are crucial for automating interactions within digital environments, similar to how humans operate software using ...