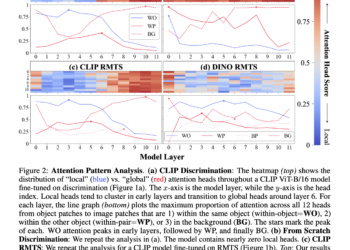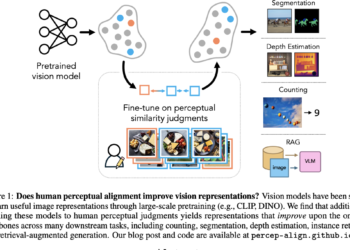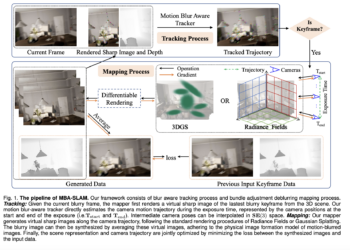
MBA-SLAM: A new AI framework for dense and robust RGB-D visual SLAM, implementing a version of implicit radiation fields and a version of explicit Gaussian splatter
SLAM (Simultaneous Localization and Mapping) It is one of the important techniques used in robotics and computer vision. It helps ...