
Channel 4 in the UK now has a dedicated app for Apple Vision Pro
The initial buzz around Apple's mixed reality headset has died down, but new apps and experiences are still coming for ...

The initial buzz around Apple's mixed reality headset has died down, but new apps and experiences are still coming for ...
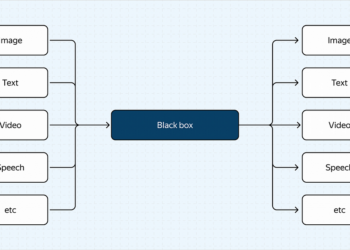
Building a 28% more accurate multimodal image search engine with VLMs.Until recently, ai models were narrow in scope and limited ...

In recent years, multimodal large language models (MLLM) have revolutionized vision-language tasks, improving capabilities such as image captioning and object ...

As the US presidential election approaches, former President Donald Trump's odds on crypto betting platforms like Polymarket have increased, with ...

A new report from The information quotes "several people" involved in making parts for Apple's Vision Pro headphones to say ...
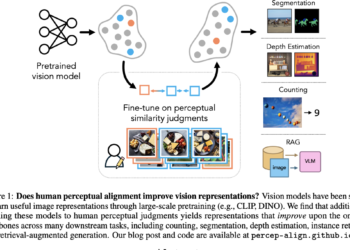
Humans possess innately extraordinary perceptual judgments, and when computer vision models are aligned with them, model performance can be greatly ...
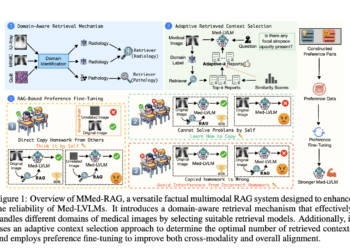
ai has had a significant impact on healthcare, particularly in disease diagnosis and treatment planning. One area gaining attention is ...

*Equal taxpayers Current basic multimodal and multitasking models, such as 4M or UnifiedIO, show promising results, but in practice their ...

In the current spirit of ai, sequence models have skyrocketed in popularity for their ability to analyze data and predict ...

Ripcache, a pseudonymous artist, explores themes of surveillance and privacy through a 1-bit pixelated aesthetic. By examining the impact of ...



