 NEWSLETTER
NEWSLETTER
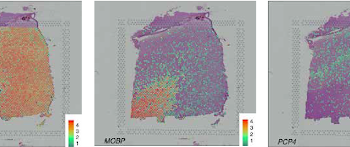
Unravel spacely variable genes: a statistical perspective on space transcriptomic
\ (\) The article was written by Guanao Yan, Ph.D. Statistics and Data Science Student in UCLA. Guanao is the ...
\ (\) The article was written by Guanao Yan, Ph.D. Statistics and Data Science Student in UCLA. Guanao is the ...

Let's start 2025 by writing clean code togetherImage by swell of unpackWhen you're deep into rapid prototyping, it's tempting to ...

Large Language Models (LLM) are commonly trained on data sets consisting of sequences of fixed-length tokens. These data sets are ...

Endogeneity presents a significant challenge when making causal inferences in observational settings. Researchers in social sciences, statistics, and related fields ...
Introduction Understanding the namespaces, scopes, and behavior of variables in Python functions is crucial for writing efficiently and avoiding runtime ...
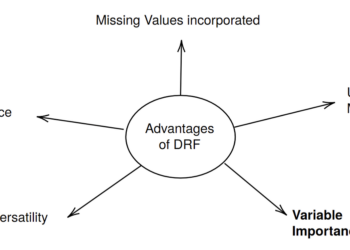
Traditional Methods and New DevelopmentsFeatures of (Distributional) Random Forests. In this article: The ability to produce variable importance. Source: Author.Random ...
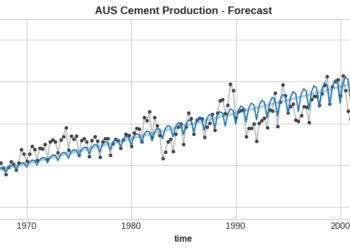
Improve time series forecasting performance with a signal processing techniqueModeling time series data and forecasting it are complex topics. There ...




