
CtrlSynth: Controllable image and text synthesis for data-efficient multimodal learning
Pre-training of robust or multimodal baseline vision models (e.g., CLIP) relies on large-scale data sets that can be noisy, potentially ...

Pre-training of robust or multimodal baseline vision models (e.g., CLIP) relies on large-scale data sets that can be noisy, potentially ...

Omnimodal language models (OLMs) are a rapidly advancing area of ai that enables understanding and reasoning across multiple types of ...
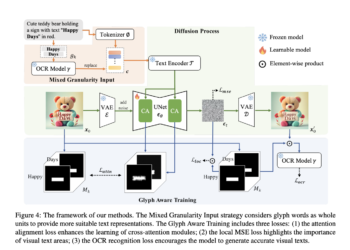
Generating accurate and aesthetically appealing visual texts in text-to-image generation models presents a significant challenge. While diffusion-based models have succeeded ...

Editor's Image | Ideogram Text mining helps us obtain important information from large amounts of text. R is a useful ...

An introduction to using no-code solutionsChart showing the process of unordered data. Image by author using ChatGPT-4o.People use large language ...

Large multimodal language models (MLLMs) focus on creating artificial intelligence (ai) systems capable of seamlessly interpreting textual and visual data. ...

Text embedding models have become fundamental in natural language processing (NLP). These models convert text into high-dimensional vectors that capture ...

IntroductionLarge Language Models or LLMs, have been all the rage since the advent of ChatGPT in 2022. This is largely ...

Generative artificial intelligence (ai) models have become increasingly popular and powerful, enabling a wide range of applications such as text ...
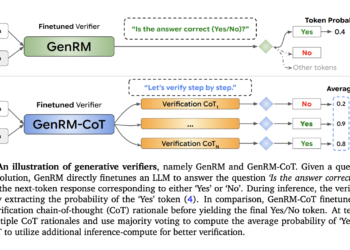
Generative ai, an area of artificial intelligence, focuses on creating systems capable of producing human-like text and solving complex reasoning ...




