 NEWSLETTER
NEWSLETTER
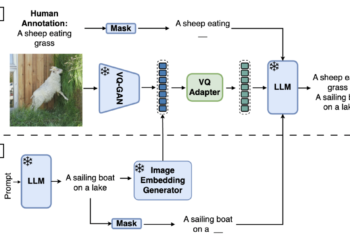
Synth2: Powering Visual Language Models with Synthetic Captions and Image Embeddings by Google DeepMind Researchers
VLMs are powerful tools for capturing visual and textual data, promising advances in tasks such as image captioning and visual ...
VLMs are powerful tools for capturing visual and textual data, promising advances in tasks such as image captioning and visual ...




