 NEWSLETTER
NEWSLETTER

Add and adapt natural language cues for subsequent CLIP generalization
Large pre-trained vision and language models, such as CLIP, have shown promising generalization ability, but may struggle in specialized domains ...
Large pre-trained vision and language models, such as CLIP, have shown promising generalization ability, but may struggle in specialized domains ...
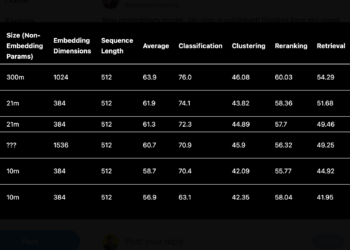
Alibaba DAMO Academy's GTE-tiny is a lightweight and fast text embedding model. It uses the BERT framework and has been ...




