 NEWSLETTER
NEWSLETTER
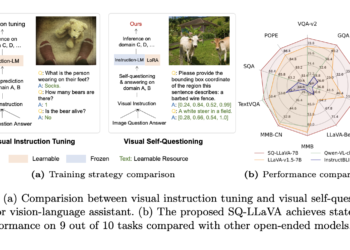
SQ-LLaVA: A New Visual Instruction Tuning Method That Improves General-Purpose Language and Vision Comprehension and Image-Oriented Question Answering Through Visual Self-Questioning
Large models of vision and language have emerged as powerful tools for multimodal understanding, demonstrating impressive capabilities for interpreting and ...




