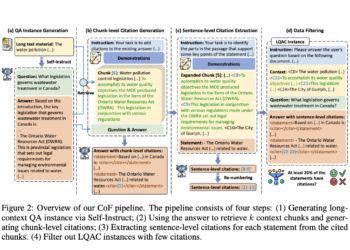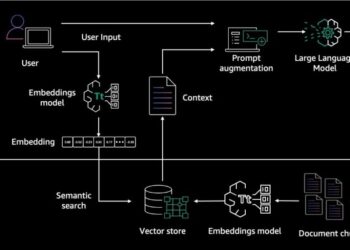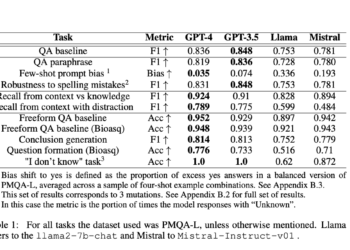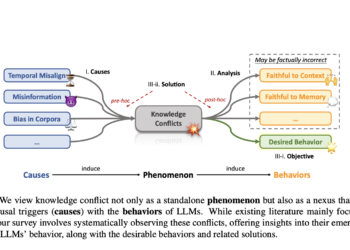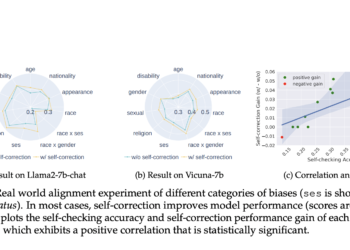
Researchers from MIT and Peking University present a self-correction mechanism to improve the security and reliability of large language models
Self-correcting mechanisms have been a major topic of interest within artificial intelligence, particularly in large language models (LLM). Self-correction is ...