 NEWSLETTER
NEWSLETTER
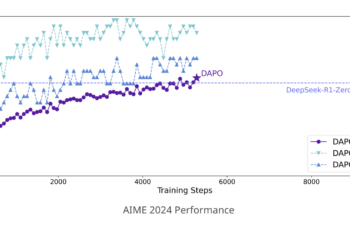
Bytedance Research Libera Dapo: A LLM Reinforcement Learning System of Complete Origin
Reinforcement learning (RL) has become central to advance large language models (LLM), empowering them with improved reasoning capabilities necessary for ...
Reinforcement learning (RL) has become central to advance large language models (LLM), empowering them with improved reasoning capabilities necessary for ...
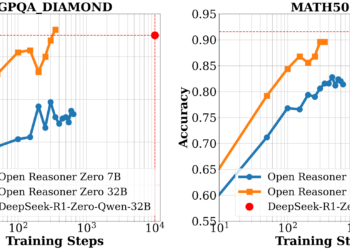
Large -scale reinforcing learning training (RL) of language models in reasoning tasks has become a promising technique to dominate complex ...

Previously we discussed applying reinforcement learning to Ordinary Differential Equations (ODEs) by integrating ODEs within gymnasium. ODEs are a powerful ...
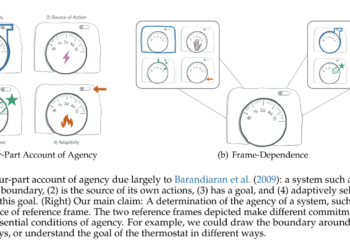
The study examines the agency concept, defined as the ability of a system to direct the results towards an objective, ...

Large language models (LLM) have shown competence in solving complex problems in mathematics, scientific research and software engineering. The impulse ...

Mathematical reasoning remains a difficult area for artificial intelligence (ai) due to the complexity of problem solving and the need ...

RL reinforcement learning trains agents to maximize rewards interacting with an environment. RL Alternate online between taking actions, collecting observations ...

Interactive digital agents (IDA) take advantage of digital environments APIs to perform tasks in response to user applications. While the ...
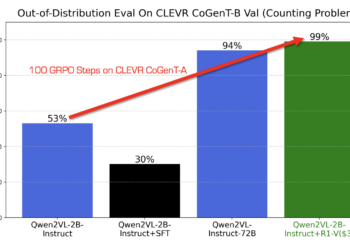
Vision language models (VLMS) face a critical challenge to achieve solid generalization beyond their training data while computing resources and ...

Agentic ai gains much value from the capacity to reason about complex environments and make informed decisions with minimal human ...




