 NEWSLETTER
NEWSLETTER

Vitalik demands a 10x scale to reinforce Ethereum's L1 domain in a heavy world L2
Key control Vitalik Buterin proposes a 10x increase in the ethereum L1 gas limit. An L1 climbing improves security, facilitates ...
Key control Vitalik Buterin proposes a 10x increase in the ethereum L1 gas limit. An L1 climbing improves security, facilitates ...

Bhutan's Gelephu Mindfulness City (GMC) has revealed plans to include bitcoin, ethereum and BNB in its strategic reserve assets, according ...
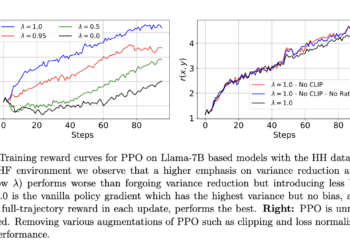
Aligning large language models (LLMs) with human preferences has become a crucial area of research. As these models gain complexity ...




