NEWSLETTER
NEWSLETTER
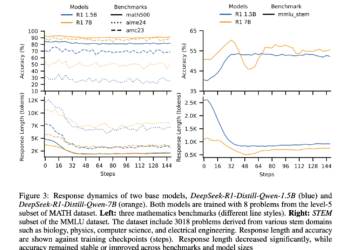
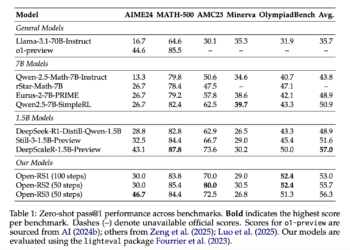
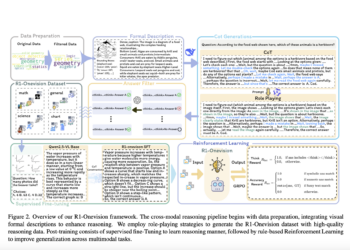
Precision and Efficiency Balance in Language Models: A two-phase RL post-LEADING APPROACH FOR CONCISE REASONING
Recent advances in LLM have significantly improve their reasoning capabilities, particularly through Fine RL -based adjustment. Initially trained with supervised ...