 NEWSLETTER
NEWSLETTER

CLARIO IMPROVE THE QUALITY OF THE DOCUMENTATION PROCESS OF THE CLINICAL TEST WITH Amazon Bedrock
This publication is co -written with Kimen and Shyam Banuprakash of Clio. CLARIO is a leading provider of final point ...
This publication is co -written with Kimen and Shyam Banuprakash of Clio. CLARIO is a leading provider of final point ...
journey from 2D photographs to 3D models follows a structured path. This path consists of distinct steps that build upon ...

When Princess Mononoke He debuted for the first time in 1997, marked an important turning point for Studio Ghibli. The ...

Key points: Teaching writing today is like being an orchestra director. Like a director gathers different instruments and dynamics to ...

Scaling up large language models (LLMs) and their training data has now opened up emerging capabilities that allow these models ...

Scientific research is often limited by resource limitations and time-consuming processes. Tasks such as hypothesis testing, data analysis, and report ...

Dennis Porter, co-founder and president of Satoshi Action Fund, a 501(c)(4) nonprofit organization, has revealed a significant development in US ...
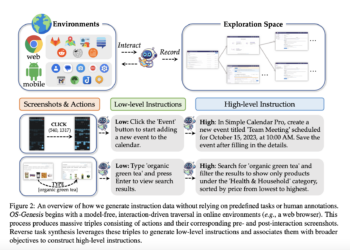
Designing GUI agents that perform human-like tasks in graphical user interfaces faces a critical hurdle: collecting high-quality trajectory data for ...

Efficient image operations with multiprocessing in PythonImage processing data setManual and repetitive tasks. Ex. One of the things I hate ...

Semiconductors are essential for powering various electronic devices and driving development in the telecommunications, automotive, healthcare, renewable energy and IoT ...




