 NEWSLETTER
NEWSLETTER

TIS-DPO: Importance sampling at the token level for direct preferences optimization
The direct preference optimization (DPO) has been widely adopted for the alignment of preferences of large language models (LLM) due ...
The direct preference optimization (DPO) has been widely adopted for the alignment of preferences of large language models (LLM) due ...
Automatic translation (MT) is experiencing a paradigm shift, with systems based on large -tuning language models (LLM) that become increasingly ...
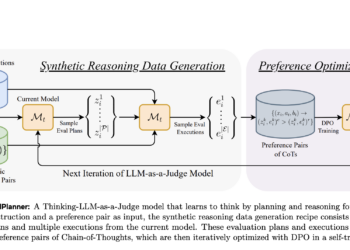
The rapid advance of large language models (LLM) has significantly improved their ability to generate long format responses. However, evaluating ...

Large language models (LLM) have become an indispensable part of contemporary life, shaping the future of almost all conceivable domains. ...

Large language models (LLMs) have revolutionized software development by enabling code completion, generation of functional code from instructions, and complex ...
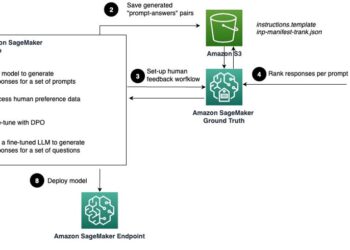
Large language models (LLMs) have remarkable capabilities. Nevertheless, using them in customer-facing applications often requires tailoring their responses to align ...
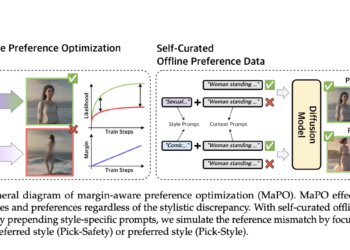
Machine learning has made notable advances, particularly in generative models such as diffusion models. These models are designed to handle ...
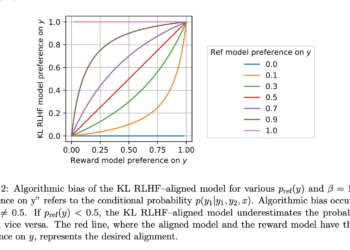
Large language models (LLMs) like ChatGPT-4 and Claude-3 Opus excel at tasks like code generation, data analysis, and reasoning. Their ...
Preference-based reinforcement learning (PbRL) has shown great promise in learning from human preference binary feedback on the agent's trajectory behaviors, ...




