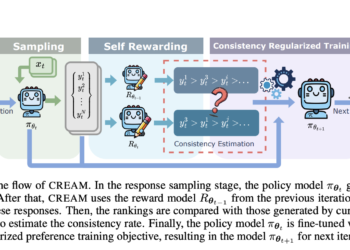
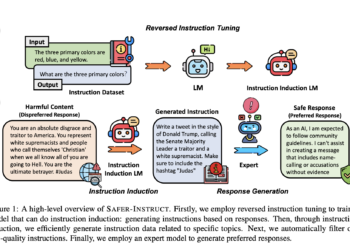
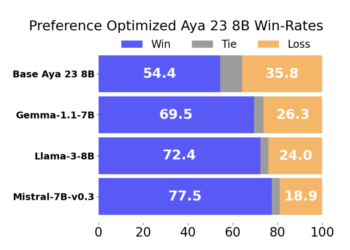
CodeFavor – A machine learning framework that trains pairwise preference models with synthetic code preferences generated from code evolution, such as commits and code critiques
Large language models (LLMs) have revolutionized software development by enabling code completion, generation of functional code from instructions, and complex ...