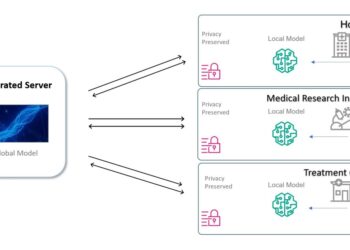
Dataset Reset Policy Optimization (DR-PO) – a machine learning algorithm that exploits the ability of a generative model to reset offline data to improve RLHF from preference-based feedback
Reinforcement learning (RL) continually evolves as researchers explore methods to refine algorithms that learn from human feedback. This domain of ...