
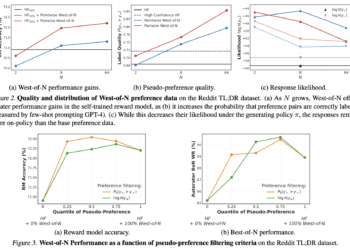
This AI paper from ETH Zurich, Google and Max Plank proposes an effective AI strategy to boost the performance of reward models for RLHF (reinforcement learning from human feedback)
In language model alignment, the effectiveness of reinforcement learning from human feedback (RLHF) depends on the excellence of the underlying ...




