 NEWSLETTER
NEWSLETTER
Optimized parallelism strategies published by Deepseek
As part of the 4 #Opensourceweek, Depseek presents 2 new tools to make deep learning faster and more efficient: Dualpipe ...
As part of the 4 #Opensourceweek, Depseek presents 2 new tools to make deep learning faster and more efficient: Dualpipe ...
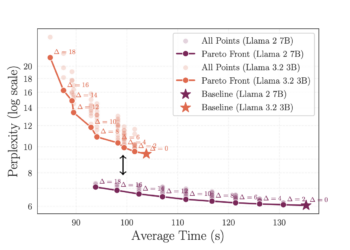
LLMs have demonstrated exceptional capabilities, but their substantial computational demands pose significant challenges for large -scale implementation. While above studies ...
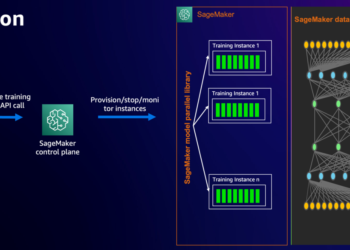
Mixture of Experts (MoE) architectures for large language models (LLMs) have recently gained popularity due to their ability to increase ...



