 NEWSLETTER
NEWSLETTER
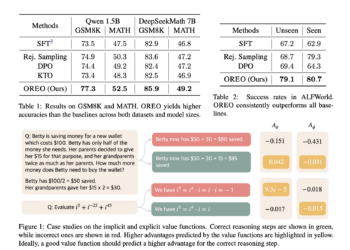
Meet OREO (Offline Reasoning Optimization) – An Offline Reinforcement Learning Method to Improve LLM Multi-Step Reasoning
Large language models (LLMs) have demonstrated impressive proficiency in numerous tasks, but their ability to perform multi-step reasoning remains a ...




