 NEWSLETTER
NEWSLETTER
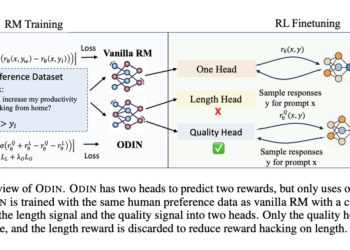
Researchers at NVIDIA and the University of Maryland propose ODIN: a reward disentanglement technique that mitigates hacking in reinforcement learning from human feedback (RLHF)
The well-known artificial intelligence (ai) based chatbot i.e. ChatGPT, which has been built on the transformative architecture of GPT, uses ...




