
Apple launches 4M-21: a highly effective multimodal AI model that solves dozens of tasks and modalities
Large language models (LLMs) have made significant progress in handling multiple modalities and tasks, but still need to improve their ...

Large language models (LLMs) have made significant progress in handling multiple modalities and tasks, but still need to improve their ...
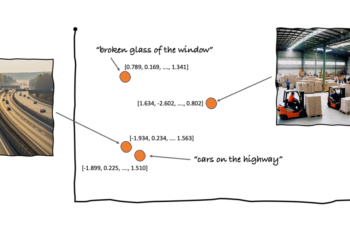
In today’s data-driven world, industries across various sectors are accumulating massive amounts of video data through cameras installed in their ...

Multimodal machine learning is a cutting-edge field of research that combines multiple types of data, such as text, images, and ...

Sleep medicine is a fundamental field that involves monitoring and evaluating physiological signals to diagnose sleep disorders and understand sleep ...

A variety of different techniques have been used for returning images relevant to search queries. Historically, the idea of creating ...

Multimodal large language models (MLLM) are cutting-edge innovations in artificial intelligence that combine the capabilities of language and vision models ...
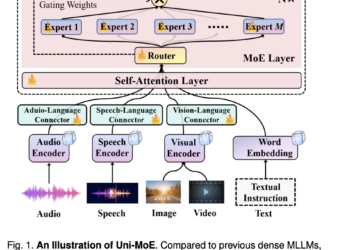
Unleashing the potential of large multimodal language models (MLLMs) to handle diverse modalities such as speech, text, images and video ...

App developers advertise their apps by creating product pages with app images and bidding on search terms. So it is ...

Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating ...
Introduction In today’s world, where data comes in various forms, including text, images, and multimedia, there is a growing need ...




