 NEWSLETTER
NEWSLETTER

Visatronic: A multimodal decoder model for speech synthesis
In this document, we propose a new task, generating speeches from videos of people and their transcripts (VTT), to motivate ...
In this document, we propose a new task, generating speeches from videos of people and their transcripts (VTT), to motivate ...
Google’s commitment to making ai accessible leaps forward with Gemma 3, the latest addition to the Gemma family of open ...
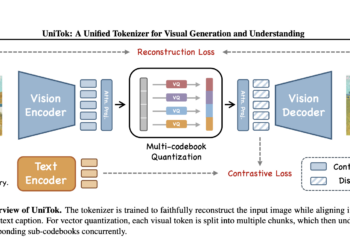
With researchers with the aim of unifying visual generation and understanding in a single framework, multimodal artificial intelligence is rapidly ...
This is an invited publication written by the team in Bytedonce. Byte It is a technology company that operates a ...
ModalitySupported LanguagesTextArabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, ...

Vision language models (VLMS) have demonstrated impressive capabilities in the general understanding of the image, but face significant challenges when ...
We introduce Mia Bench, a new reference point designed to evaluate large multimodal language models (MLLM) about its ability to ...
Multimodal large language models (MLLM) have demonstrated a wide range of capacities in many domains, including incorporated ai. In this ...
We examine the ability of large language models (MLLM) multimodal to address various domains that extend beyond the traditional tasks ...
Los sistemas de agente multimodal representan un avance revolucionario en el campo de la inteligencia artificial, combinando perfectamente diversos tipos ...




