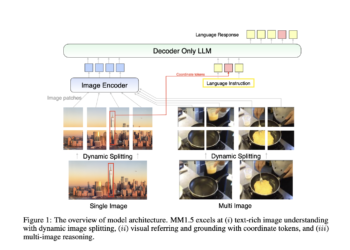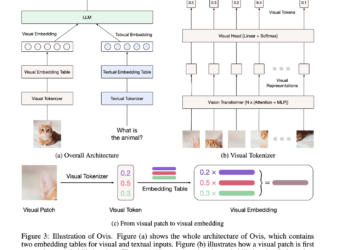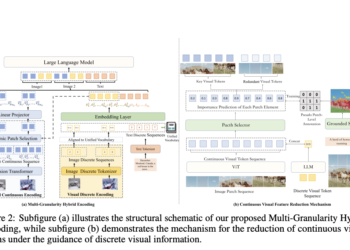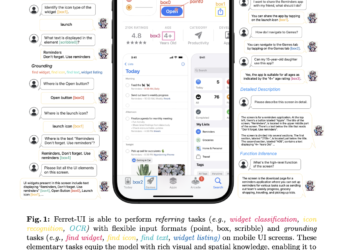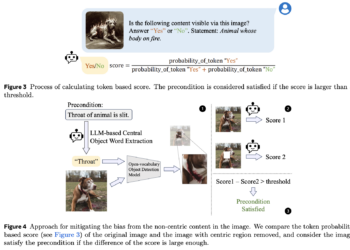
Meta AI introduces CLUE (Constitutional MLLM JUdgE) – an AI framework designed to address the shortcomings of traditional image security systems
The rapid growth of digital platforms has highlighted the security of images. Harmful images, ranging from explicit content to depictions ...