 NEWSLETTER
NEWSLETTER

Memory-Efficient Model Weight Loading in PyTorch
I recently came across a post by Sebastian that caught my attention, and I wanted to dive deeper into its ...
I recently came across a post by Sebastian that caught my attention, and I wanted to dive deeper into its ...
Introduction Vector streaming is being introduced in EmbedAnything, a feature designed to streamline large-scale document embedding. Enabling asynchronous sharding and ...
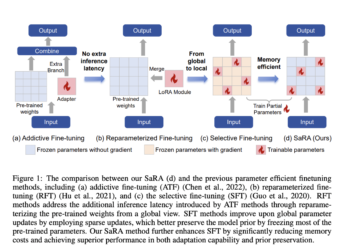
Recent advances in diffusion models have significantly improved tasks such as image, video, and 3D generation, with pre-trained models such ...
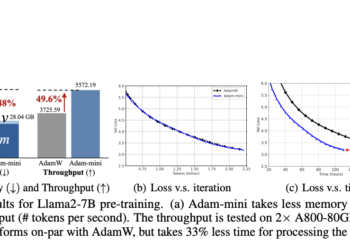
The research field focuses on optimizing algorithms for training large language models (LLMs), which are essential for understanding and generating ...

Flash attention is a power optimization transformer attention mechanism that provides 15% efficiency.Photo by sander traa in unpackFlash attention is ...

Many developers and researchers working with large language models face the challenge of tuning the models efficiently and effectively. Tuning ...

The field of natural language processing (NLP) has witnessed significant advancements with the emergence of large language models (LLM) such ...
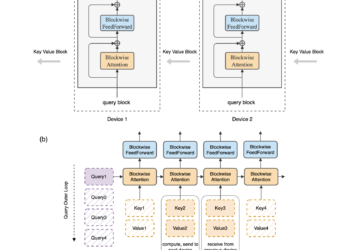
One type of deep learning model architecture is called Transformers in the context of many next-generation ai models. They have ...




