 NEWSLETTER
NEWSLETTER
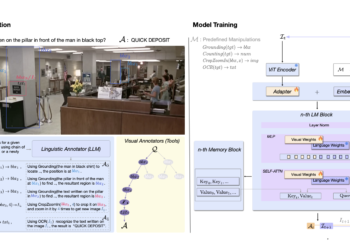
Improving vision-language models with chain of manipulations: a leap towards faithful visual reasoning and error traceability
High-vision language models (VLMs) trained to understand vision have demonstrated viability in broad scenarios such as visual question answering, visual ...





