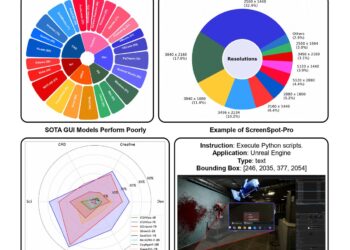
ScreenSpot-Pro: The First Benchmark Driving Multimodal LLMs Towards High-Resolution Professional GUI Agent and Computer Usage Environments
GUI agents face three critical challenges in professional environments: (1) the increased complexity of professional applications compared to general-purpose software, ...