 NEWSLETTER
NEWSLETTER

Flextok: Folding in token sequences 1d flexible length
This work was carried out in collaboration with the Federal Swiss Institute of Lausanian technology (EPFL). The tokenization of images ...
This work was carried out in collaboration with the Federal Swiss Institute of Lausanian technology (EPFL). The tokenization of images ...

Significant progress has been made in instrumental compositions shortly in ai and music generation. However, creating complete songs with lyrics, ...

Advances in large languages (LLM) models have significantly improved natural language processing (NLP), allowing capacities such as contextual understanding, code ...
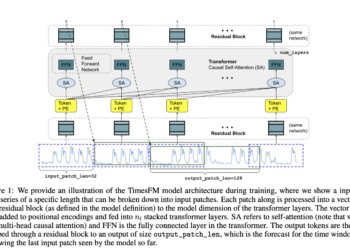
Time series forecasting plays a crucial role in various fields, including finance, healthcare, and climate science. However, achieving accurate predictions ...
Detecting user-defined keywords on a resource-constrained edge device is challenging. However, keywords are often limited by a maximum keyword length, ...
Large Language Models (LLM) are commonly trained on data sets consisting of sequences of fixed-length tokens. These data sets are ...
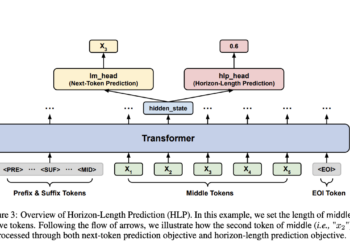
When writing the code for any program or algorithm, developers can have difficulty filling in gaps in incomplete code and ...
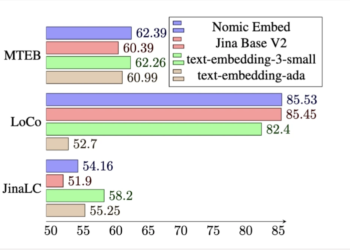
Nomic ai launched an onboarding model with a multi-stage training process. ai/posts/nomic-embed-text-v1">Embed nomic, an open source, auditable, high-performance text embedding ...
The large Language Model (LLM) has changed the way people work. With a model like the GPT family being widely ...

How to turn your llama into a giraffeAuthor's image. (ai generated flames)Context length refers to the maximum number of tokens ...




