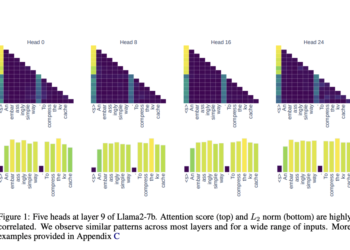
This AI paper presents a novel L2 standards-based KV cache compression strategy for large language models
Large language models (LLMs) are designed to understand and manage complex linguistic tasks by capturing context and long-term dependencies. A ...